 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEFSA: Episodic Few-Shot Adaptation for Text-to-Image Retrieval
Paper and Code
Nov 28, 2024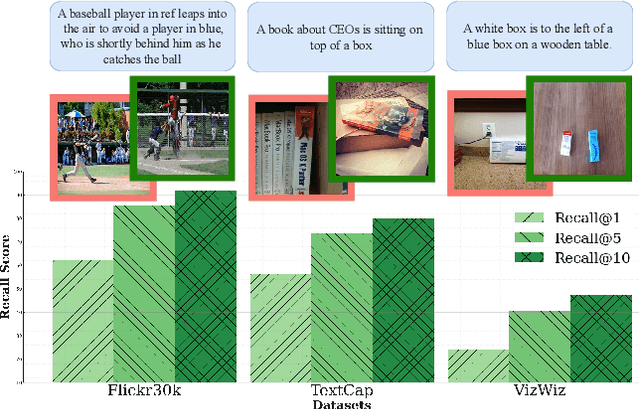



Text-to-image retrieval is a critical task for managing diverse visual content, but common benchmarks for the task rely on small, single-domain datasets that fail to capture real-world complexity. Pre-trained vision-language models tend to perform well with easy negatives but struggle with hard negatives--visually similar yet incorrect images--especially in open-domain scenarios. To address this, we introduce Episodic Few-Shot Adaptation (EFSA), a novel test-time framework that adapts pre-trained models dynamically to a query's domain by fine-tuning on top-k retrieved candidates and synthetic captions generated for them. EFSA improves performance across diverse domains while preserving generalization, as shown in evaluations on queries from eight highly distinct visual domains and an open-domain retrieval pool of over one million images. Our work highlights the potential of episodic few-shot adaptation to enhance robustness in the critical and understudied task of open-domain text-to-image retrieval.