 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2026 3D Restoration and Reconstruction in Real-world Adverse Conditions: RealX3D Challenge Results
Apr 05, 2026This paper presents a comprehensive review of the NTIRE 2026 3D Restoration and Reconstruction (3DRR) Challenge, detailing the proposed methods and results. The challenge seeks to identify robust reconstruction pipelines that are robust under real-world adverse conditions, specifically extreme low-light and smoke-degraded environments, as captured by our RealX3D benchmark. A total of 279 participants registered for the competition, of whom 33 teams submitted valid results. We thoroughly evaluate the submitted approaches against state-of-the-art baselines, revealing significant progress in 3D reconstruction under adverse conditions. Our analysis highlights shared design principles among top-performing methods and provides insights into effective strategies for handling 3D scene degradation.
FlexGaussian: Flexible and Cost-Effective Training-Free Compression for 3D Gaussian Splatting
Jul 09, 2025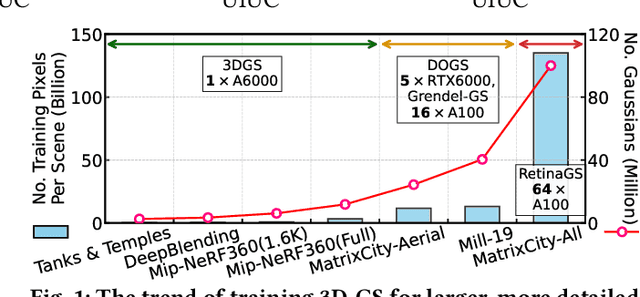
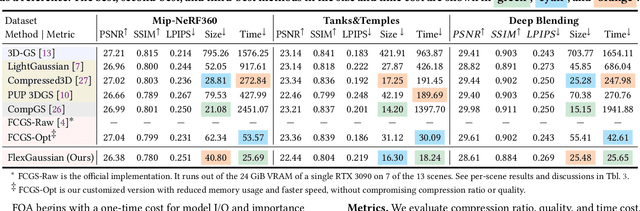
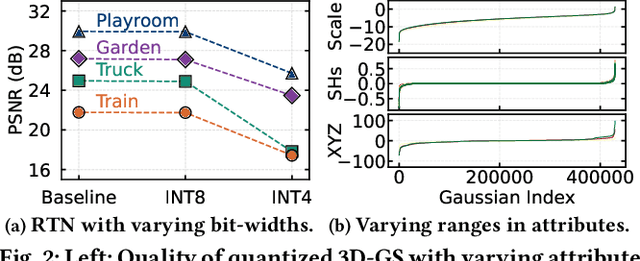
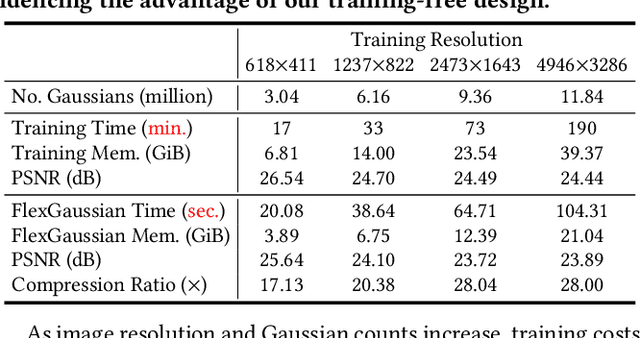
3D Gaussian splatting has become a prominent technique for representing and rendering complex 3D scenes, due to its high fidelity and speed advantages. However, the growing demand for large-scale models calls for effective compression to reduce memory and computation costs, especially on mobile and edge devices with limited resources. Existing compression methods effectively reduce 3D Gaussian parameters but often require extensive retraining or fine-tuning, lacking flexibility under varying compression constraints. In this paper, we introduce FlexGaussian, a flexible and cost-effective method that combines mixed-precision quantization with attribute-discriminative pruning for training-free 3D Gaussian compression. FlexGaussian eliminates the need for retraining and adapts easily to diverse compression targets. Evaluation results show that FlexGaussian achieves up to 96.4% compression while maintaining high rendering quality (<1 dB drop in PSNR), and is deployable on mobile devices. FlexGaussian delivers high compression ratios within seconds, being 1.7-2.1x faster than state-of-the-art training-free methods and 10-100x faster than training-involved approaches. The code is being prepared and will be released soon at: https://github.com/Supercomputing-System-AI-Lab/FlexGaussian
Towards Energy-Efficiency by Navigating the Trilemma of Energy, Latency, and Accuracy
Sep 06, 2024
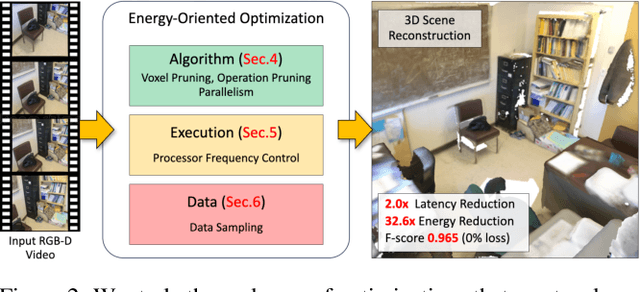
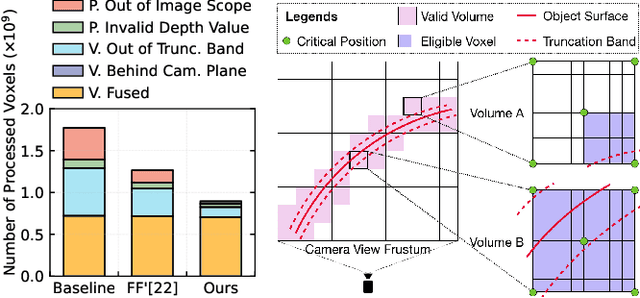
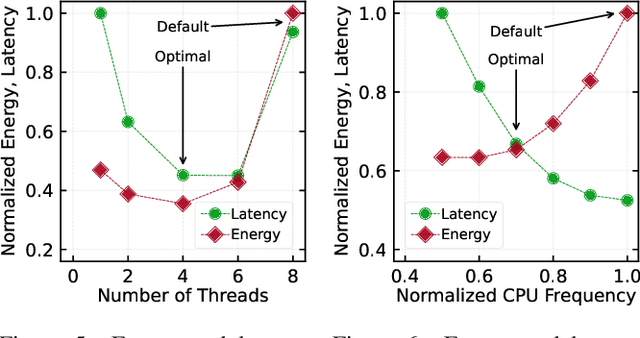
Extended Reality (XR) enables immersive experiences through untethered headsets but suffers from stringent battery and resource constraints. Energy-efficient design is crucial to ensure both longevity and high performance in XR devices. However, latency and accuracy are often prioritized over energy, leading to a gap in achieving energy efficiency. This paper examines scene reconstruction, a key building block for immersive XR experiences, and demonstrates how energy efficiency can be achieved by navigating the trilemma of energy, latency, and accuracy. We explore three classes of energy-oriented optimizations, covering the algorithm, execution, and data, that reveal a broad design space through configurable parameters. Our resulting 72 designs expose a wide range of latency and energy trade-offs, with a smaller range of accuracy loss. We identify a Pareto-optimal curve and show that the designs on the curve are achievable only through synergistic co-optimization of all three optimization classes and by considering the latency and accuracy needs of downstream scene reconstruction consumers. Our analysis covering various use cases and measurements on an embedded class system shows that, relative to the baseline, our designs offer energy benefits of up to 60X with potential latency range of 4X slowdown to 2X speedup. Detailed exploration of a use case across representative data sequences from ScanNet showed about 25X energy savings with 1.5X latency reduction and negligible reconstruction quality loss.
Mesorasi: Architecture Support for Point Cloud Analytics via Delayed-Aggregation
Aug 16, 2020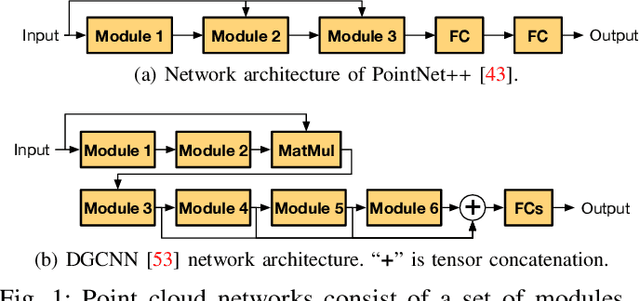
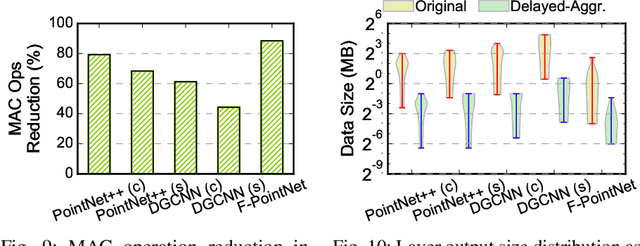
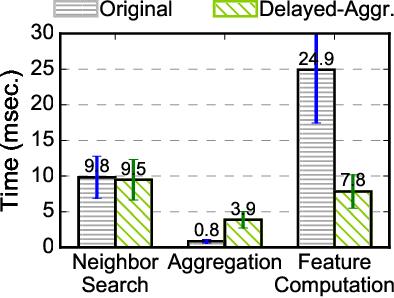
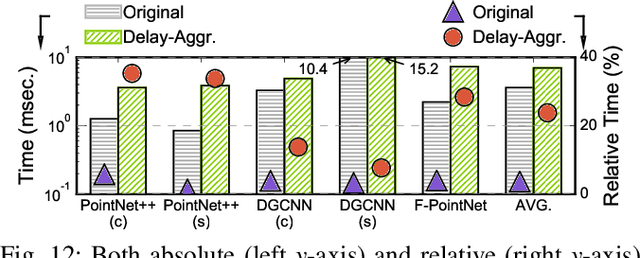
Point cloud analytics is poised to become a key workload on battery-powered embedded and mobile platforms in a wide range of emerging application domains, such as autonomous driving, robotics, and augmented reality, where efficiency is paramount. This paper proposes Mesorasi, an algorithm-architecture co-designed system that simultaneously improves the performance and energy efficiency of point cloud analytics while retaining its accuracy. Our extensive characterizations of state-of-the-art point cloud algorithms show that, while structurally reminiscent of convolutional neural networks (CNNs), point cloud algorithms exhibit inherent compute and memory inefficiencies due to the unique characteristics of point cloud data. We propose delayed-aggregation, a new algorithmic primitive for building efficient point cloud algorithms. Delayed-aggregation hides the performance bottlenecks and reduces the compute and memory redundancies by exploiting the approximately distributive property of key operations in point cloud algorithms. Delayed-aggregation let point cloud algorithms achieve 1.6x speedup and 51.1% energy reduction on a mobile GPU while retaining the accuracy (-0.9% loss to 1.2% gains). To maximize the algorithmic benefits, we propose minor extensions to contemporary CNN accelerators, which can be integrated into a mobile Systems-on-a-Chip (SoC) without modifying other SoC components. With additional hardware support, Mesorasi achieves up to 3.6x speedup.
Tigris: Architecture and Algorithms for 3D Perception in Point Clouds
Nov 21, 2019
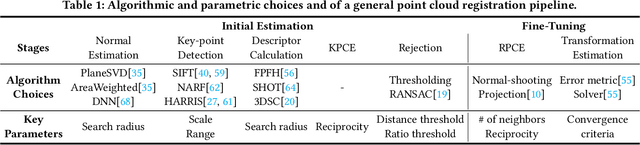

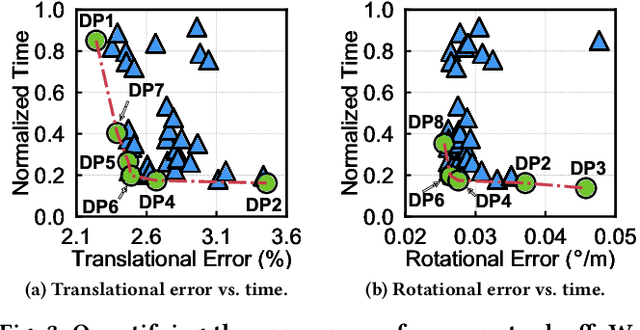
Machine perception applications are increasingly moving toward manipulating and processing 3D point cloud. This paper focuses on point cloud registration, a key primitive of 3D data processing widely used in high-level tasks such as odometry, simultaneous localization and mapping, and 3D reconstruction. As these applications are routinely deployed in energy-constrained environments, real-time and energy-efficient point cloud registration is critical. We present Tigris, an algorithm-architecture co-designed system specialized for point cloud registration. Through an extensive exploration of the registration pipeline design space, we find that, while different design points make vastly different trade-offs between accuracy and performance, KD-tree search is a common performance bottleneck, and thus is an ideal candidate for architectural specialization. While KD-tree search is inherently sequential, we propose an acceleration-amenable data structure and search algorithm that exposes different forms of parallelism of KD-tree search in the context of point cloud registration. The co-designed accelerator systematically exploits the parallelism while incorporating a set of architectural techniques that further improve the accelerator efficiency. Overall, Tigris achieves 77.2$\times$ speedup and 7.4$\times$ power reduction in KD-tree search over an RTX 2080 Ti GPU, which translates to a 41.7% registration performance improvements and 3.0$\times$ power reduction.