 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMesorasi: Architecture Support for Point Cloud Analytics via Delayed-Aggregation
Aug 16, 2020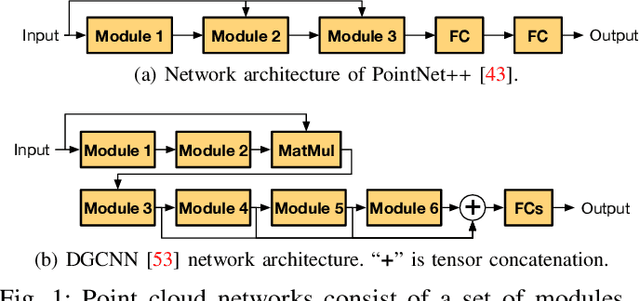
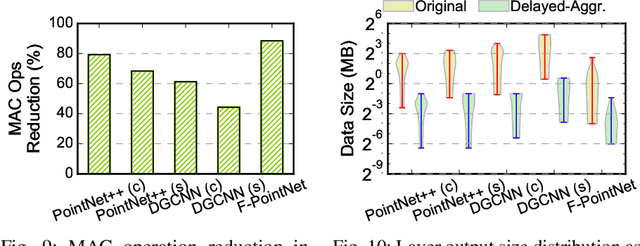
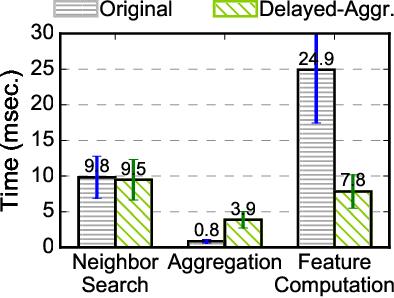
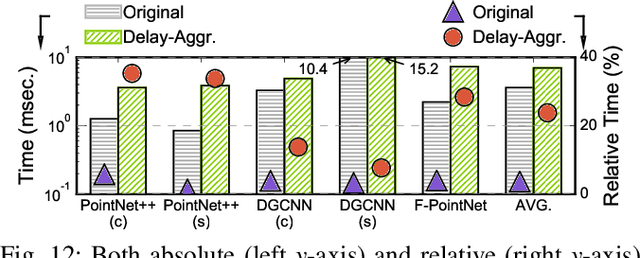
Point cloud analytics is poised to become a key workload on battery-powered embedded and mobile platforms in a wide range of emerging application domains, such as autonomous driving, robotics, and augmented reality, where efficiency is paramount. This paper proposes Mesorasi, an algorithm-architecture co-designed system that simultaneously improves the performance and energy efficiency of point cloud analytics while retaining its accuracy. Our extensive characterizations of state-of-the-art point cloud algorithms show that, while structurally reminiscent of convolutional neural networks (CNNs), point cloud algorithms exhibit inherent compute and memory inefficiencies due to the unique characteristics of point cloud data. We propose delayed-aggregation, a new algorithmic primitive for building efficient point cloud algorithms. Delayed-aggregation hides the performance bottlenecks and reduces the compute and memory redundancies by exploiting the approximately distributive property of key operations in point cloud algorithms. Delayed-aggregation let point cloud algorithms achieve 1.6x speedup and 51.1% energy reduction on a mobile GPU while retaining the accuracy (-0.9% loss to 1.2% gains). To maximize the algorithmic benefits, we propose minor extensions to contemporary CNN accelerators, which can be integrated into a mobile Systems-on-a-Chip (SoC) without modifying other SoC components. With additional hardware support, Mesorasi achieves up to 3.6x speedup.
Tigris: Architecture and Algorithms for 3D Perception in Point Clouds
Nov 21, 2019
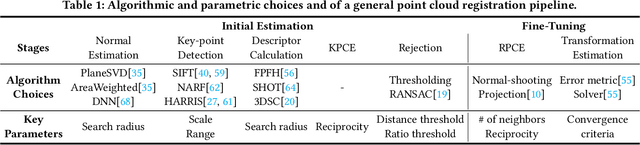

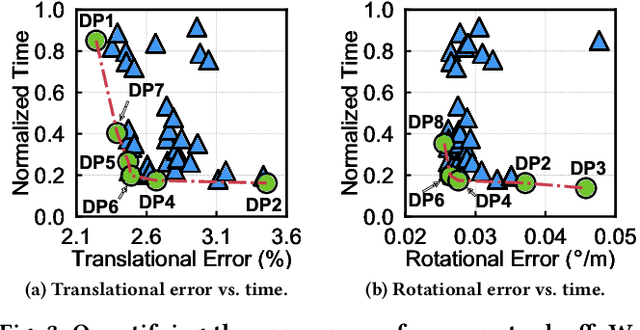
Machine perception applications are increasingly moving toward manipulating and processing 3D point cloud. This paper focuses on point cloud registration, a key primitive of 3D data processing widely used in high-level tasks such as odometry, simultaneous localization and mapping, and 3D reconstruction. As these applications are routinely deployed in energy-constrained environments, real-time and energy-efficient point cloud registration is critical. We present Tigris, an algorithm-architecture co-designed system specialized for point cloud registration. Through an extensive exploration of the registration pipeline design space, we find that, while different design points make vastly different trade-offs between accuracy and performance, KD-tree search is a common performance bottleneck, and thus is an ideal candidate for architectural specialization. While KD-tree search is inherently sequential, we propose an acceleration-amenable data structure and search algorithm that exposes different forms of parallelism of KD-tree search in the context of point cloud registration. The co-designed accelerator systematically exploits the parallelism while incorporating a set of architectural techniques that further improve the accelerator efficiency. Overall, Tigris achieves 77.2$\times$ speedup and 7.4$\times$ power reduction in KD-tree search over an RTX 2080 Ti GPU, which translates to a 41.7% registration performance improvements and 3.0$\times$ power reduction.