 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-Device CPU Scheduling for Sense-React Systems
Aug 14, 2022

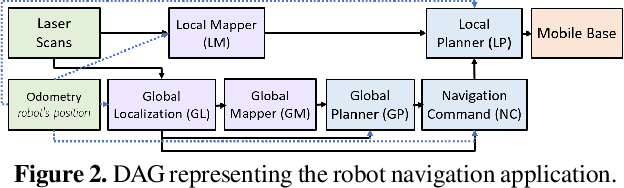
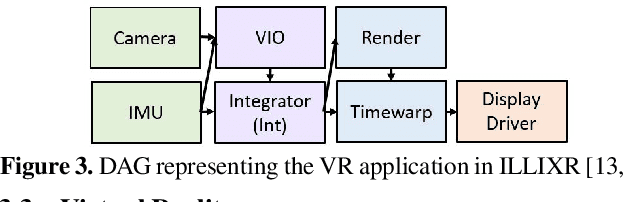
Sense-react systems (e.g. robotics and AR/VR) have to take highly responsive real-time actions, driven by complex decisions involving a pipeline of sensing, perception, planning, and reaction tasks. These tasks must be scheduled on resource-constrained devices such that the performance goals and the requirements of the application are met. This is a difficult scheduling problem that requires handling multiple scheduling dimensions, and variations in resource usage and availability. In practice, system designers manually tune parameters for their specific hardware and application, which results in poor generalization and increases the development burden. In this work, we highlight the emerging need for scheduling CPU resources at runtime in sense-react systems. We study three canonical applications (face tracking, robot navigation, and VR) to first understand the key scheduling requirements for such systems. Armed with this understanding, we develop a scheduling framework, Catan, that dynamically schedules compute resources across different components of an app so as to meet the specified application requirements. Through experiments with a prototype implemented on a widely-used robotics framework (ROS) and an open-source AR/VR platform, we show the impact of system scheduling on meeting the performance goals for the three applications, how Catan is able to achieve better application performance than hand-tuned configurations, and how it dynamically adapts to runtime variations.
Caramel: Accelerating Decentralized Distributed Deep Learning with Computation Scheduling
Apr 29, 2020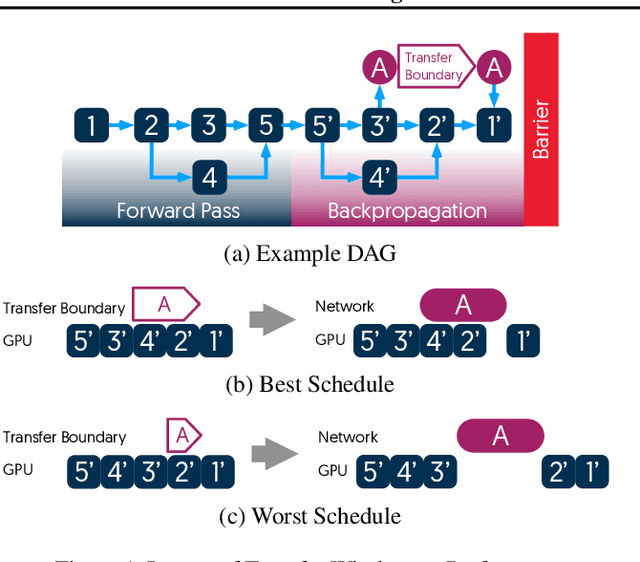
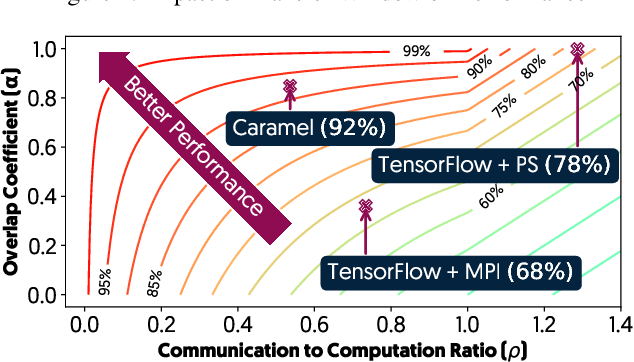
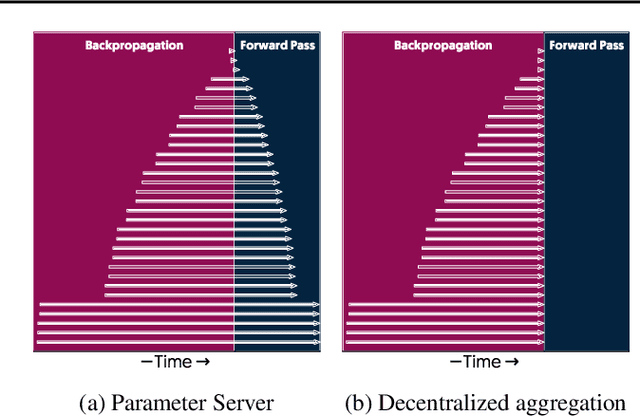
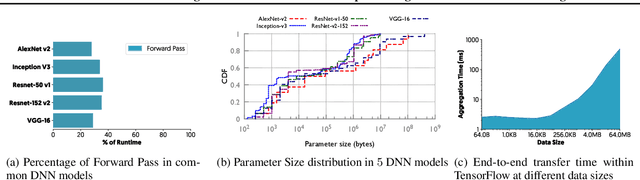
The method of choice for parameter aggregation in Deep Neural Network (DNN) training, a network-intensive task, is shifting from the Parameter Server model to decentralized aggregation schemes (AllReduce) inspired by theoretical guarantees of better performance. However, current implementations of AllReduce overlook the interdependence of communication and computation, resulting in significant performance degradation. In this paper, we develop Caramel, a system that accelerates decentralized distributed deep learning through model-aware computation scheduling and communication optimizations for AllReduce. Caramel achieves this goal through (a) computation DAG scheduling that expands the feasible window of transfer for each parameter (transfer boundaries), and (b) network optimizations for smoothening of the load including adaptive batching and pipelining of parameter transfers. Caramel maintains the correctness of the dataflow model, is hardware-independent, and does not require any user-level or framework-level changes. We implement Caramel over TensorFlow and show that the iteration time of DNN training can be improved by up to 3.62x in a cloud environment.