 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAiravat: An Agentic Framework for Internet Measurement
Feb 24, 2026Internet measurement faces twin challenges: complex analyses require expert-level orchestration of tools, yet even syntactically correct implementations can have methodological flaws and can be difficult to verify. Democratizing measurement capabilities thus demands automating both workflow generation and verification against methodological standards established through decades of research. We present Airavat, the first agentic framework for Internet measurement workflow generation with systematic verification and validation. Airavat coordinates a set of agents mirroring expert reasoning: three agents handle problem decomposition, solution design, and code implementation, with assistance from a registry of existing tools. Two specialized engines ensure methodological correctness: a Verification Engine evaluates workflows against a knowledge graph encoding five decades of measurement research, while a Validation Engine identifies appropriate validation techniques grounded in established methodologies. Through four Internet measurement case studies, we demonstrate that Airavat (i) generates workflows matching expert-level solutions, (ii) makes sound architectural decisions, (iii) addresses novel problems without ground truth, and (iv) identifies methodological flaws missed by standard execution-based testing.
Towards an Agentic Workflow for Internet Measurement Research
Nov 13, 2025Internet measurement research faces an accessibility crisis: complex analyses require custom integration of multiple specialized tools that demands specialized domain expertise. When network disruptions occur, operators need rapid diagnostic workflows spanning infrastructure mapping, routing analysis, and dependency modeling. However, developing these workflows requires specialized knowledge and significant manual effort. We present ArachNet, the first system demonstrating that LLM agents can independently generate measurement workflows that mimics expert reasoning. Our core insight is that measurement expertise follows predictable compositional patterns that can be systematically automated. ArachNet operates through four specialized agents that mirror expert workflow, from problem decomposition to solution implementation. We validate ArachNet with progressively challenging Internet resilience scenarios. The system independently generates workflows that match expert-level reasoning and produce analytical outputs similar to specialist solutions. Generated workflows handle complex multi-framework integration that traditionally requires days of manual coordination. ArachNet lowers barriers to measurement workflow composition by automating the systematic reasoning process that experts use, enabling broader access to sophisticated measurement capabilities while maintaining the technical rigor required for research-quality analysis.
IMPQ: Interaction-Aware Layerwise Mixed Precision Quantization for LLMs
Sep 18, 2025Large Language Models (LLMs) promise impressive capabilities, yet their multi-billion-parameter scale makes on-device or low-resource deployment prohibitive. Mixed-precision quantization offers a compelling solution, but existing methods struggle when the average precision drops below four bits, as they rely on isolated, layer-specific metrics that overlook critical inter-layer interactions affecting overall performance. In this paper, we propose two innovations to address these limitations. First, we frame the mixed-precision quantization problem as a cooperative game among layers and introduce Shapley-based Progressive Quantization Estimation (SPQE) to efficiently obtain accurate Shapley estimates of layer sensitivities and inter-layer interactions. Second, building upon SPQE, we propose Interaction-aware Mixed-Precision Quantization (IMPQ) which translates these Shapley estimates into a binary quadratic optimization formulation, assigning either 2 or 4-bit precision to layers under strict memory constraints. Comprehensive experiments conducted on Llama-3, Gemma-2, and Qwen-3 models across three independent PTQ backends (Quanto, HQQ, GPTQ) demonstrate IMPQ's scalability and consistently superior performance compared to methods relying solely on isolated metrics. Across average precisions spanning 4 bit down to 2 bit, IMPQ cuts Perplexity by 20 to 80 percent relative to the best baseline, with the margin growing as the bit-width tightens.
ShareLoRA: Parameter Efficient and Robust Large Language Model Fine-tuning via Shared Low-Rank Adaptation
Jun 16, 2024This study introduces an approach to optimize Parameter Efficient Fine Tuning (PEFT) for Pretrained Language Models (PLMs) by implementing a Shared Low Rank Adaptation (ShareLoRA). By strategically deploying ShareLoRA across different layers and adapting it for the Query, Key, and Value components of self-attention layers, we achieve a substantial reduction in the number of training parameters and memory usage. Importantly, ShareLoRA not only maintains model performance but also exhibits robustness in both classification and generation tasks across a variety of models, including RoBERTa, GPT-2, LLaMA and LLaMA2. It demonstrates superior transfer learning capabilities compared to standard LoRA applications and mitigates overfitting by sharing weights across layers. Our findings affirm that ShareLoRA effectively boosts parameter efficiency while ensuring scalable and high-quality performance across different language model architectures.
LinguaLinked: A Distributed Large Language Model Inference System for Mobile Devices
Dec 01, 2023



Deploying Large Language Models (LLMs) locally on mobile devices presents a significant challenge due to their extensive memory requirements. In this paper, we introduce LinguaLinked, a system for decentralized, distributed LLM inference on mobile devices. LinguaLinked enables collaborative execution of the inference task across multiple trusted devices. LinguaLinked ensures data privacy by processing information locally. LinguaLinked uses three key strategies. First, an optimized model assignment technique segments LLMs and uses linear optimization to align segments with each device's capabilities. Second, an optimized data transmission mechanism ensures efficient and structured data flow between model segments while also maintaining the integrity of the original model structure. Finally, LinguaLinked incorporates a runtime load balancer that actively monitors and redistributes tasks among mobile devices to prevent bottlenecks, enhancing the system's overall efficiency and responsiveness. We demonstrate that LinguaLinked facilitates efficient LLM inference while maintaining consistent throughput and minimal latency through extensive testing across various mobile devices, from high-end to low-end Android devices. In our evaluations, compared to the baseline, LinguaLinked achieves an inference performance acceleration of $1.11\times$ to $1.61\times$ in single-threaded settings, $1.73\times$ to $2.65\times$ with multi-threading. Additionally, runtime load balancing yields an overall inference acceleration of $1.29\times$ to $1.32\times$.
CrystalBox: Future-Based Explanations for DRL Network Controllers
Feb 27, 2023Lack of explainability is a key factor limiting the practical adoption of high-performant Deep Reinforcement Learning (DRL) controllers. Explainable RL for networking hitherto used salient input features to interpret a controller's behavior. However, these feature-based solutions do not completely explain the controller's decision-making process. Often, operators are interested in understanding the impact of a controller's actions on performance in the future, which feature-based solutions cannot capture. In this paper, we present CrystalBox, a framework that explains a controller's behavior in terms of the future impact on key network performance metrics. CrystalBox employs a novel learning-based approach to generate succinct and expressive explanations. We use reward components of the DRL network controller, which are key performance metrics meaningful to operators, as the basis for explanations. CrystalBox is generalizable and can work across both discrete and continuous control environments without any changes to the controller or the DRL workflow. Using adaptive bitrate streaming and congestion control, we demonstrate CrytalBox's ability to generate high-fidelity future-based explanations. We additionally present three practical use cases of CrystalBox: cross-state explainability, guided reward design, and network observability.
Prioritized Trace Selection: Towards High-Performance DRL-based Network Controllers
Feb 24, 2023



Deep Reinforcement Learning (DRL) based controllers offer high performance in a variety of network environments. However, simulator-based training of DRL controllers using highly skewed datasets of real-world traces often results in poor performance in the wild. In this paper, we put forward a generalizable solution for training high-performance DRL controllers in simulators -- Prioritized Trace Selection (PTS). PTS employs an automated three-stage process. First, we identify critical features that determine trace behavior. Second, we classify the traces into clusters. Finally, we dynamically identify and prioritize the salient clusters during training. PTS does not require any changes to the DRL workflow. It can work across both on-policy and off-policy DRL algorithms. We use Adaptive Bit Rate selection and Congestion Control as representative applications to show that PTS offers better performance in simulation and real-world, across multiple controllers and DRL algorithms. Our novel ABR controller, Gelato, trained with PTS outperforms state-of-the-art controllers on the real-world live-streaming platform, Puffer, reducing stalls by 59% and significantly improving average video quality.
Caramel: Accelerating Decentralized Distributed Deep Learning with Computation Scheduling
Apr 29, 2020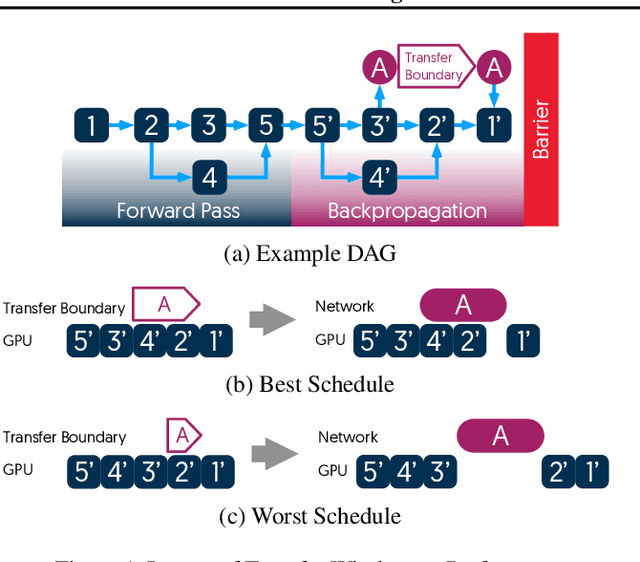
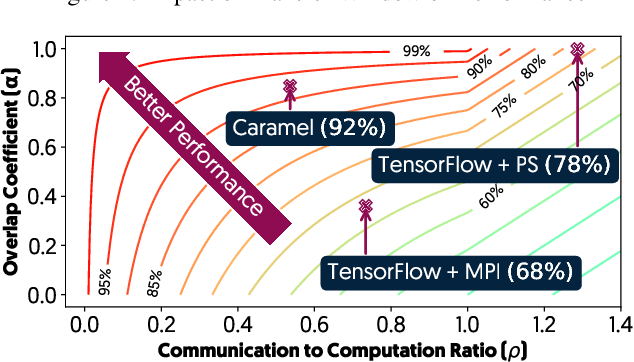
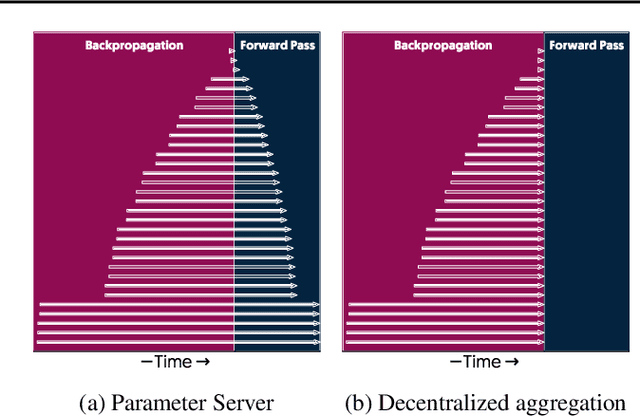
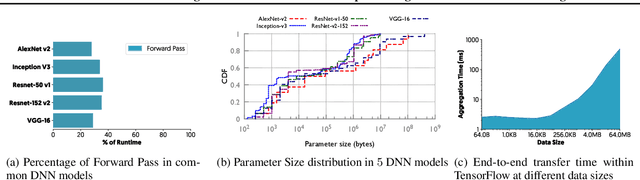
The method of choice for parameter aggregation in Deep Neural Network (DNN) training, a network-intensive task, is shifting from the Parameter Server model to decentralized aggregation schemes (AllReduce) inspired by theoretical guarantees of better performance. However, current implementations of AllReduce overlook the interdependence of communication and computation, resulting in significant performance degradation. In this paper, we develop Caramel, a system that accelerates decentralized distributed deep learning through model-aware computation scheduling and communication optimizations for AllReduce. Caramel achieves this goal through (a) computation DAG scheduling that expands the feasible window of transfer for each parameter (transfer boundaries), and (b) network optimizations for smoothening of the load including adaptive batching and pipelining of parameter transfers. Caramel maintains the correctness of the dataflow model, is hardware-independent, and does not require any user-level or framework-level changes. We implement Caramel over TensorFlow and show that the iteration time of DNN training can be improved by up to 3.62x in a cloud environment.
TicTac: Accelerating Distributed Deep Learning with Communication Scheduling
Oct 04, 2018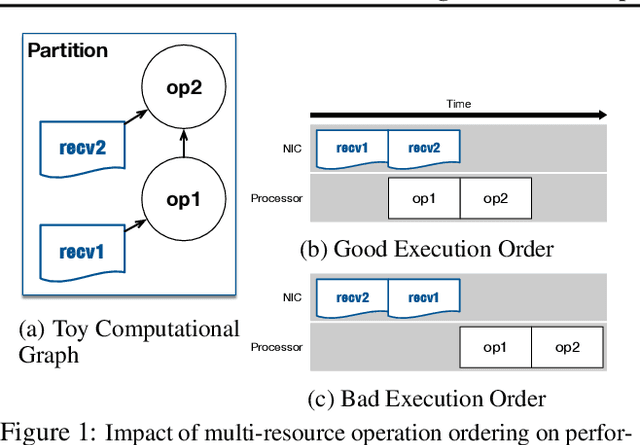
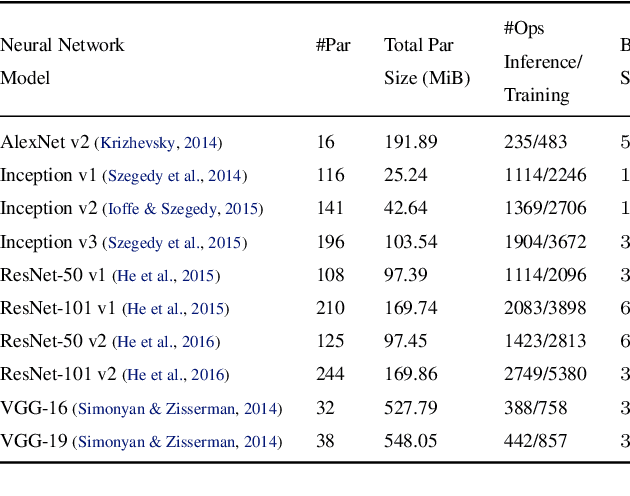
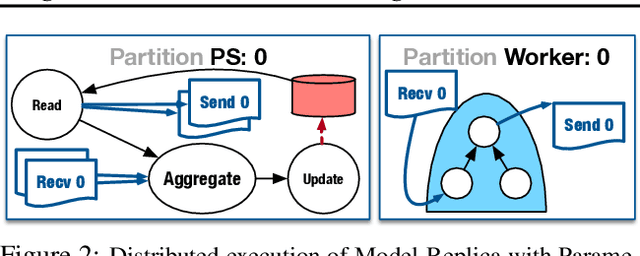
State-of-the-art deep learning systems rely on iterative distributed training to tackle the increasing complexity of models and input data. The iteration time in these communication-heavy systems depends on the computation time, communication time and the extent of overlap of computation and communication. In this work, we identify a shortcoming in systems with graph representation for computation, such as TensorFlow and PyTorch, that result in high variance in iteration time --- random order of received parameters across workers. We develop a system, TicTac, to improve the iteration time by fixing this issue in distributed deep learning with Parameter Servers while guaranteeing near-optimal overlap of communication and computation. TicTac identifies and enforces an order of network transfers which improves the iteration time using prioritization. Our system is implemented over TensorFlow and requires no changes to the model or developer inputs. TicTac improves the throughput by up to $37.7\%$ in inference and $19.2\%$ in training, while also reducing straggler effect by up to $2.3\times$. Our code is publicly available.