 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMPQ: Interaction-Aware Layerwise Mixed Precision Quantization for LLMs
Sep 18, 2025Large Language Models (LLMs) promise impressive capabilities, yet their multi-billion-parameter scale makes on-device or low-resource deployment prohibitive. Mixed-precision quantization offers a compelling solution, but existing methods struggle when the average precision drops below four bits, as they rely on isolated, layer-specific metrics that overlook critical inter-layer interactions affecting overall performance. In this paper, we propose two innovations to address these limitations. First, we frame the mixed-precision quantization problem as a cooperative game among layers and introduce Shapley-based Progressive Quantization Estimation (SPQE) to efficiently obtain accurate Shapley estimates of layer sensitivities and inter-layer interactions. Second, building upon SPQE, we propose Interaction-aware Mixed-Precision Quantization (IMPQ) which translates these Shapley estimates into a binary quadratic optimization formulation, assigning either 2 or 4-bit precision to layers under strict memory constraints. Comprehensive experiments conducted on Llama-3, Gemma-2, and Qwen-3 models across three independent PTQ backends (Quanto, HQQ, GPTQ) demonstrate IMPQ's scalability and consistently superior performance compared to methods relying solely on isolated metrics. Across average precisions spanning 4 bit down to 2 bit, IMPQ cuts Perplexity by 20 to 80 percent relative to the best baseline, with the margin growing as the bit-width tightens.
ShareLoRA: Parameter Efficient and Robust Large Language Model Fine-tuning via Shared Low-Rank Adaptation
Jun 16, 2024This study introduces an approach to optimize Parameter Efficient Fine Tuning (PEFT) for Pretrained Language Models (PLMs) by implementing a Shared Low Rank Adaptation (ShareLoRA). By strategically deploying ShareLoRA across different layers and adapting it for the Query, Key, and Value components of self-attention layers, we achieve a substantial reduction in the number of training parameters and memory usage. Importantly, ShareLoRA not only maintains model performance but also exhibits robustness in both classification and generation tasks across a variety of models, including RoBERTa, GPT-2, LLaMA and LLaMA2. It demonstrates superior transfer learning capabilities compared to standard LoRA applications and mitigates overfitting by sharing weights across layers. Our findings affirm that ShareLoRA effectively boosts parameter efficiency while ensuring scalable and high-quality performance across different language model architectures.
LinguaLinked: A Distributed Large Language Model Inference System for Mobile Devices
Dec 01, 2023



Deploying Large Language Models (LLMs) locally on mobile devices presents a significant challenge due to their extensive memory requirements. In this paper, we introduce LinguaLinked, a system for decentralized, distributed LLM inference on mobile devices. LinguaLinked enables collaborative execution of the inference task across multiple trusted devices. LinguaLinked ensures data privacy by processing information locally. LinguaLinked uses three key strategies. First, an optimized model assignment technique segments LLMs and uses linear optimization to align segments with each device's capabilities. Second, an optimized data transmission mechanism ensures efficient and structured data flow between model segments while also maintaining the integrity of the original model structure. Finally, LinguaLinked incorporates a runtime load balancer that actively monitors and redistributes tasks among mobile devices to prevent bottlenecks, enhancing the system's overall efficiency and responsiveness. We demonstrate that LinguaLinked facilitates efficient LLM inference while maintaining consistent throughput and minimal latency through extensive testing across various mobile devices, from high-end to low-end Android devices. In our evaluations, compared to the baseline, LinguaLinked achieves an inference performance acceleration of $1.11\times$ to $1.61\times$ in single-threaded settings, $1.73\times$ to $2.65\times$ with multi-threading. Additionally, runtime load balancing yields an overall inference acceleration of $1.29\times$ to $1.32\times$.
Safety-Aware Multi-Agent Apprenticeship Learning
Jan 24, 2022
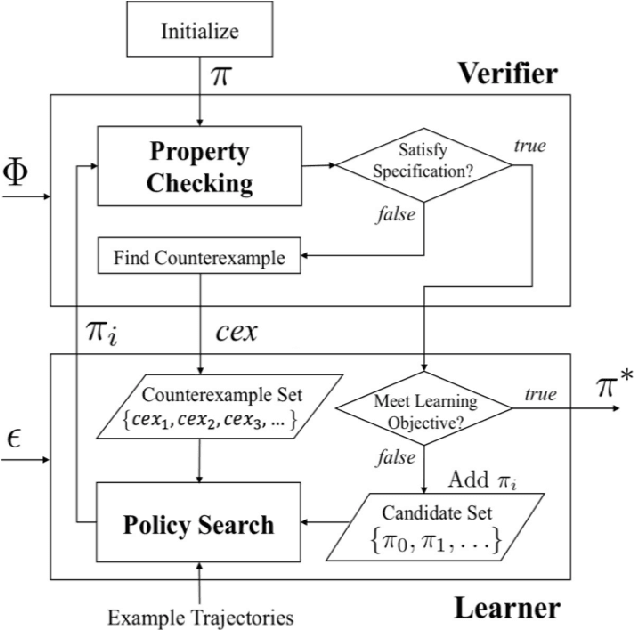
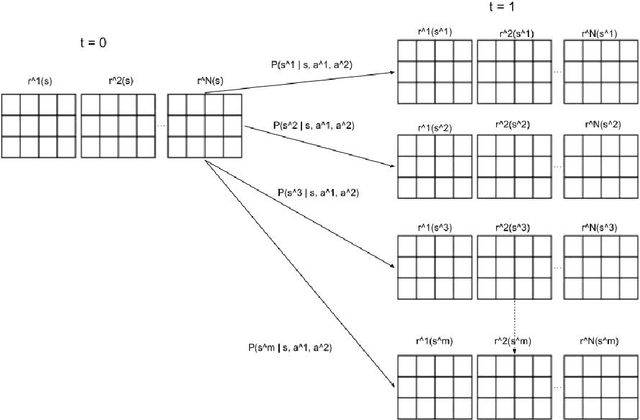

Our objective of this project is to make the extension based on the technique mentioned in the paper "Safety-Aware Apprenticeship Learning" to improve the utility and the efficiency of the existing Reinforcement Learning model from a Single-Agent Learning framework to a Multi-Agent Learning framework. Our contributions to the project are presented in the following bullet points: 1. Regarding the fact that we will add an extension to the Inverse Reinforcement Learning model from a Single-Agent scenario to a Multi-Agentscenario. Our first contribution to this project is considering the case of extracting safe reward functions from expert behaviors in a Multi-Agent scenario instead of being from the Single-Agent scenario. 2. Our second contribution is extending the Single-Agent Learning Framework to a Multi-Agent Learning framework and designing a novel Learning Framework based on the extension in the end. 3. Our final contribution to this project is evaluating empirically the performance of my extension to the Single-Agent Inverse Reinforcement Learning framework.
GAP-Gen: Guided Automatic Python Code Generation
Jan 19, 2022



Automatic code generation from natural language descriptions can be highly beneficial during the process of software development. In this work, we propose GAP-Gen, an automatic code generation method guided by Python syntactic constraints and semantic constraints. We first introduce Python syntactic constraints in the form of Syntax-Flow, which is a simplified version of Abstract Syntax Tree (AST) reducing the size and high complexity of Abstract Syntax Tree but maintaining the crucial syn-tactic information of Python code. In addition to Syntax-Flow, we introduce Variable-Flow which abstracts variable and function names consistently throughout the code. In our work, rather than pre-training, we focus on modifying the fine-tuning process which reduces computational requirements but retains high generation performance on automatic Python code generation task. GAP-Gen fine-tunes the transformer-based language models T5 and CodeT5 using the Code-to-Docstring datasets CodeSearchNet, CodeSearchNet AdvTest, and Code-Docstring-Corpus from EdinburghNLP. Our experiments show that GAP-Gen achieves better results on automatic Python code generation task than previous works