 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompress to Focus: Efficient Coordinate Compression for Policy Optimization in Multi-Turn GUI Agents
Jan 14, 2026Multi-turn GUI agents enable complex task completion through sequential decision-making, but suffer from severe context inflation as interaction history accumulates. Existing strategies either sacrifice long-term context via truncation or compromise spatial structure through token pruning. In this paper, we propose Coordinate Compression Policy Optimization (CCPO), an efficient policy optimization framework that couples visual compression with policy optimization for multi-turn GUI agents. CCPO introduces Coordinate-Aware Spatial Compression (CASC), which aggregates coordinates from multiple rollouts to capture target-relevant regions and progressively narrow historical attention around key visual areas. From interactions across rollouts, CASC adaptively constructs attention boundaries that concentrate computation on the most informative regions of the scene. We further design a Distance-Based Advantage that provides fine-grained learning signals based on distance rather than binary correctness, improving both grounding accuracy and compression quality. Extensive experiments demonstrate that CCPO achieves SOTA performance across four benchmarks with up to 55% token compression and 3.8$\times$ training speedup.
Fine-Tuning vs. RAG for Multi-Hop Question Answering with Novel Knowledge
Jan 11, 2026Multi-hop question answering is widely used to evaluate the reasoning capabilities of large language models (LLMs), as it requires integrating multiple pieces of supporting knowledge to arrive at a correct answer. While prior work has explored different mechanisms for providing knowledge to LLMs, such as finetuning and retrieval-augmented generation (RAG), their relative effectiveness for multi-hop question answering remains insufficiently understood, particularly when the required knowledge is temporally novel. In this paper, we systematically compare parametric and non-parametric knowledge injection methods for open-domain multi-hop question answering. We evaluate unsupervised fine-tuning (continual pretraining), supervised fine-tuning, and retrieval-augmented generation across three 7B-parameter open-source LLMs. Experiments are conducted on two benchmarks: QASC, a standard multi-hop science question answering dataset, and a newly constructed dataset of over 10,000 multi-hop questions derived from Wikipedia events in 2024, designed to test knowledge beyond the models' pretraining cutoff. Our results show that unsupervised fine-tuning provides only limited gains over base models, suggesting that continual pretraining alone is insufficient for improving multi-hop reasoning accuracy. In contrast, retrieval-augmented generation yields substantial and consistent improvements, particularly when answering questions that rely on temporally novel information. Supervised fine-tuning achieves the highest overall accuracy across models and datasets. These findings highlight fundamental differences in how knowledge injection mechanisms support multi-hop question answering and underscore the importance of retrieval-based methods when external or compositional knowledge is required.
ShareLoRA: Parameter Efficient and Robust Large Language Model Fine-tuning via Shared Low-Rank Adaptation
Jun 16, 2024This study introduces an approach to optimize Parameter Efficient Fine Tuning (PEFT) for Pretrained Language Models (PLMs) by implementing a Shared Low Rank Adaptation (ShareLoRA). By strategically deploying ShareLoRA across different layers and adapting it for the Query, Key, and Value components of self-attention layers, we achieve a substantial reduction in the number of training parameters and memory usage. Importantly, ShareLoRA not only maintains model performance but also exhibits robustness in both classification and generation tasks across a variety of models, including RoBERTa, GPT-2, LLaMA and LLaMA2. It demonstrates superior transfer learning capabilities compared to standard LoRA applications and mitigates overfitting by sharing weights across layers. Our findings affirm that ShareLoRA effectively boosts parameter efficiency while ensuring scalable and high-quality performance across different language model architectures.
VCD: Knowledge Base Guided Visual Commonsense Discovery in Images
Feb 27, 2024


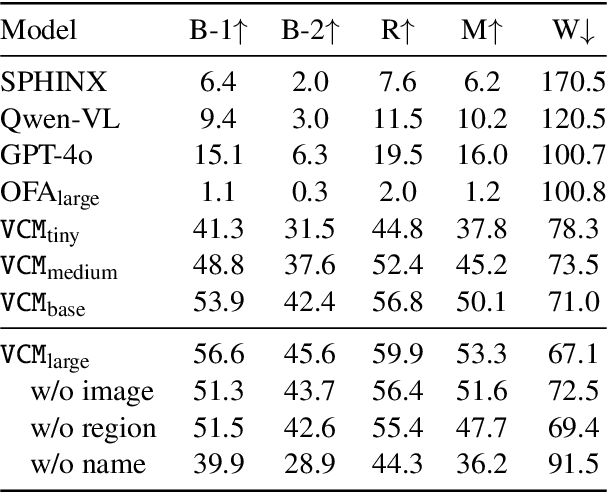
Visual commonsense contains knowledge about object properties, relationships, and behaviors in visual data. Discovering visual commonsense can provide a more comprehensive and richer understanding of images, and enhance the reasoning and decision-making capabilities of computer vision systems. However, the visual commonsense defined in existing visual commonsense discovery studies is coarse-grained and incomplete. In this work, we draw inspiration from a commonsense knowledge base ConceptNet in natural language processing, and systematically define the types of visual commonsense. Based on this, we introduce a new task, Visual Commonsense Discovery (VCD), aiming to extract fine-grained commonsense of different types contained within different objects in the image. We accordingly construct a dataset (VCDD) from Visual Genome and ConceptNet for VCD, featuring over 100,000 images and 14 million object-commonsense pairs. We furthermore propose a generative model (VCDM) that integrates a vision-language model with instruction tuning to tackle VCD. Automatic and human evaluations demonstrate VCDM's proficiency in VCD, particularly outperforming GPT-4V in implicit commonsense discovery. The value of VCD is further demonstrated by its application to two downstream tasks, including visual commonsense evaluation and visual question answering. The data and code will be made available on GitHub.
LinguaLinked: A Distributed Large Language Model Inference System for Mobile Devices
Dec 01, 2023



Deploying Large Language Models (LLMs) locally on mobile devices presents a significant challenge due to their extensive memory requirements. In this paper, we introduce LinguaLinked, a system for decentralized, distributed LLM inference on mobile devices. LinguaLinked enables collaborative execution of the inference task across multiple trusted devices. LinguaLinked ensures data privacy by processing information locally. LinguaLinked uses three key strategies. First, an optimized model assignment technique segments LLMs and uses linear optimization to align segments with each device's capabilities. Second, an optimized data transmission mechanism ensures efficient and structured data flow between model segments while also maintaining the integrity of the original model structure. Finally, LinguaLinked incorporates a runtime load balancer that actively monitors and redistributes tasks among mobile devices to prevent bottlenecks, enhancing the system's overall efficiency and responsiveness. We demonstrate that LinguaLinked facilitates efficient LLM inference while maintaining consistent throughput and minimal latency through extensive testing across various mobile devices, from high-end to low-end Android devices. In our evaluations, compared to the baseline, LinguaLinked achieves an inference performance acceleration of $1.11\times$ to $1.61\times$ in single-threaded settings, $1.73\times$ to $2.65\times$ with multi-threading. Additionally, runtime load balancing yields an overall inference acceleration of $1.29\times$ to $1.32\times$.
GAP-Gen: Guided Automatic Python Code Generation
Jan 19, 2022



Automatic code generation from natural language descriptions can be highly beneficial during the process of software development. In this work, we propose GAP-Gen, an automatic code generation method guided by Python syntactic constraints and semantic constraints. We first introduce Python syntactic constraints in the form of Syntax-Flow, which is a simplified version of Abstract Syntax Tree (AST) reducing the size and high complexity of Abstract Syntax Tree but maintaining the crucial syn-tactic information of Python code. In addition to Syntax-Flow, we introduce Variable-Flow which abstracts variable and function names consistently throughout the code. In our work, rather than pre-training, we focus on modifying the fine-tuning process which reduces computational requirements but retains high generation performance on automatic Python code generation task. GAP-Gen fine-tunes the transformer-based language models T5 and CodeT5 using the Code-to-Docstring datasets CodeSearchNet, CodeSearchNet AdvTest, and Code-Docstring-Corpus from EdinburghNLP. Our experiments show that GAP-Gen achieves better results on automatic Python code generation task than previous works