 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVCD: Knowledge Base Guided Visual Commonsense Discovery in Images
Paper and Code
Feb 27, 2024


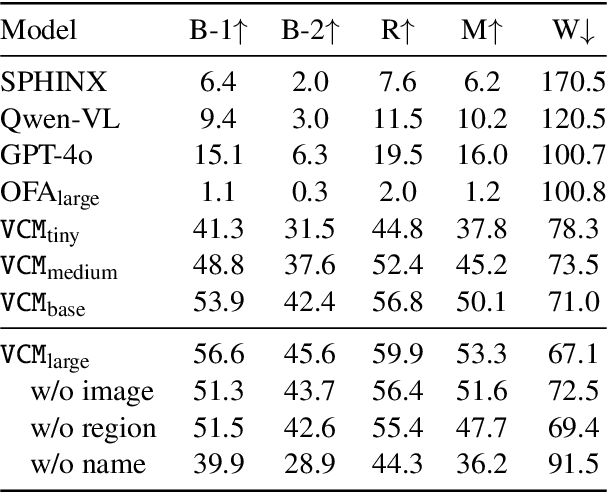
Visual commonsense contains knowledge about object properties, relationships, and behaviors in visual data. Discovering visual commonsense can provide a more comprehensive and richer understanding of images, and enhance the reasoning and decision-making capabilities of computer vision systems. However, the visual commonsense defined in existing visual commonsense discovery studies is coarse-grained and incomplete. In this work, we draw inspiration from a commonsense knowledge base ConceptNet in natural language processing, and systematically define the types of visual commonsense. Based on this, we introduce a new task, Visual Commonsense Discovery (VCD), aiming to extract fine-grained commonsense of different types contained within different objects in the image. We accordingly construct a dataset (VCDD) from Visual Genome and ConceptNet for VCD, featuring over 100,000 images and 14 million object-commonsense pairs. We furthermore propose a generative model (VCDM) that integrates a vision-language model with instruction tuning to tackle VCD. Automatic and human evaluations demonstrate VCDM's proficiency in VCD, particularly outperforming GPT-4V in implicit commonsense discovery. The value of VCD is further demonstrated by its application to two downstream tasks, including visual commonsense evaluation and visual question answering. The data and code will be made available on GitHub.