 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing RAG Rerankers with LLM Feedback via Reinforcement Learning
Apr 02, 2026Rerankers play a pivotal role in refining retrieval results for Retrieval-Augmented Generation. However, current reranking models are typically optimized on static human annotated relevance labels in isolation, decoupled from the downstream generation process. This isolation leads to a fundamental misalignment: documents identified as topically relevant by information retrieval metrics often fail to provide the actual utility required by the LLM for precise answer generation. To bridge this gap, we introduce ReRanking Preference Optimization (RRPO), a reinforcement learning framework that directly aligns reranking with the LLM's generation quality. By formulating reranking as a sequential decision-making process, RRPO optimizes for context utility using LLM feedback, thereby eliminating the need for expensive human annotations. To ensure training stability, we further introduce a reference-anchored deterministic baseline. Extensive experiments on knowledge-intensive benchmarks demonstrate that RRPO significantly outperforms strong baselines, including the powerful list-wise reranker RankZephyr. Further analysis highlights the versatility of our framework: it generalizes seamlessly to diverse readers (e.g., GPT-4o), integrates orthogonally with query expansion modules like Query2Doc, and remains robust even when trained with noisy supervisors.
Execution-Verified Reinforcement Learning for Optimization Modeling
Apr 01, 2026Automating optimization modeling with LLMs is a promising path toward scalable decision intelligence, but existing approaches either rely on agentic pipelines built on closed-source LLMs with high inference latency, or fine-tune smaller LLMs using costly process supervision that often overfits to a single solver API. Inspired by reinforcement learning with verifiable rewards, we propose Execution-Verified Optimization Modeling (EVOM), an execution-verified learning framework that treats a mathematical programming solver as a deterministic, interactive verifier. Given a natural-language problem and a target solver, EVOM generates solver-specific code, executes it in a sandboxed harness, and converts execution outcomes into scalar rewards, optimized with GRPO and DAPO in a closed-loop generate-execute-feedback-update process. This outcome-only formulation removes the need for process-level supervision, and enables cross-solver generalization by switching the verification environment rather than reconstructing solver-specific datasets. Experiments on NL4OPT, MAMO, IndustryOR, and OptiBench across Gurobi, OR-Tools, and COPT show that EVOM matches or outperforms process-supervised SFT, supports zero-shot solver transfer, and achieves effective low-cost solver adaptation by continuing training under the target solver backend.
Reason-Align-Respond: Aligning LLM Reasoning with Knowledge Graphs for KGQA
May 27, 2025LLMs have demonstrated remarkable capabilities in complex reasoning tasks, yet they often suffer from hallucinations and lack reliable factual grounding. Meanwhile, knowledge graphs (KGs) provide structured factual knowledge but lack the flexible reasoning abilities of LLMs. In this paper, we present Reason-Align-Respond (RAR), a novel framework that systematically integrates LLM reasoning with knowledge graphs for KGQA. Our approach consists of three key components: a Reasoner that generates human-like reasoning chains, an Aligner that maps these chains to valid KG paths, and a Responser that synthesizes the final answer. We formulate this process as a probabilistic model and optimize it using the Expectation-Maximization algorithm, which iteratively refines the reasoning chains and knowledge paths. Extensive experiments on multiple benchmarks demonstrate the effectiveness of RAR, achieving state-of-the-art performance with Hit@1 scores of 93.3% and 91.0% on WebQSP and CWQ respectively. Human evaluation confirms that RAR generates high-quality, interpretable reasoning chains well-aligned with KG paths. Furthermore, RAR exhibits strong zero-shot generalization capabilities and maintains computational efficiency during inference.
MEMIT-Merge: Addressing MEMIT's Key-Value Conflicts in Same-Subject Batch Editing for LLMs
Feb 11, 2025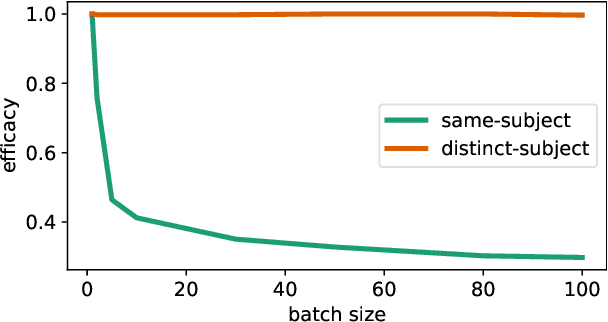

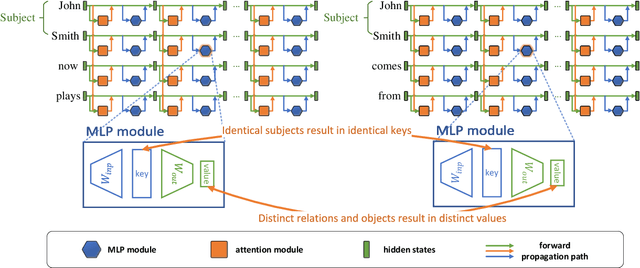

As large language models continue to scale up, knowledge editing techniques that modify models' internal knowledge without full retraining have gained significant attention. MEMIT, a prominent batch editing algorithm, stands out for its capability to perform mass knowledge modifications. However, we uncover a critical limitation that MEMIT's editing efficacy significantly deteriorates when processing batches containing multiple edits sharing the same subject. Our analysis reveals that the root cause lies in MEMIT's key value modeling framework: When multiple facts with the same subject in a batch are modeled through MEMIT's key value mechanism, identical keys (derived from the shared subject) are forced to represent different values (corresponding to different knowledge), resulting in updates conflicts during editing. Addressing this issue, we propose MEMIT-Merge, an enhanced approach that merges value computation processes for facts sharing the same subject, effectively resolving the performance degradation in same-subject batch editing scenarios. Experimental results demonstrate that when MEMIT's edit success rate drops to around 50% at larger batch sizes, MEMIT-Merge maintains a success rate exceeding 90%, showcasing remarkable robustness to subject entity collisions.
VCD: Knowledge Base Guided Visual Commonsense Discovery in Images
Feb 27, 2024


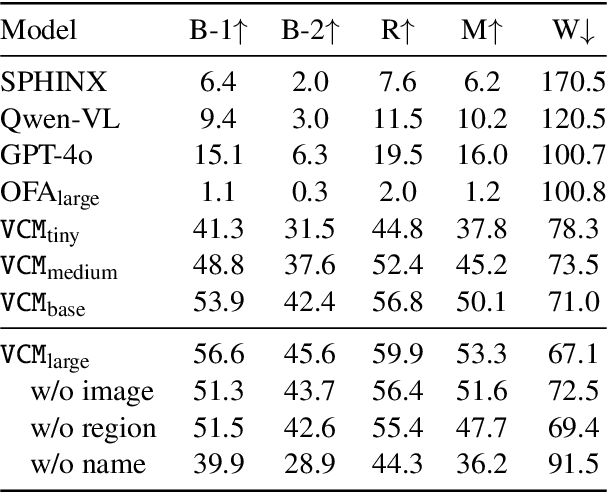
Visual commonsense contains knowledge about object properties, relationships, and behaviors in visual data. Discovering visual commonsense can provide a more comprehensive and richer understanding of images, and enhance the reasoning and decision-making capabilities of computer vision systems. However, the visual commonsense defined in existing visual commonsense discovery studies is coarse-grained and incomplete. In this work, we draw inspiration from a commonsense knowledge base ConceptNet in natural language processing, and systematically define the types of visual commonsense. Based on this, we introduce a new task, Visual Commonsense Discovery (VCD), aiming to extract fine-grained commonsense of different types contained within different objects in the image. We accordingly construct a dataset (VCDD) from Visual Genome and ConceptNet for VCD, featuring over 100,000 images and 14 million object-commonsense pairs. We furthermore propose a generative model (VCDM) that integrates a vision-language model with instruction tuning to tackle VCD. Automatic and human evaluations demonstrate VCDM's proficiency in VCD, particularly outperforming GPT-4V in implicit commonsense discovery. The value of VCD is further demonstrated by its application to two downstream tasks, including visual commonsense evaluation and visual question answering. The data and code will be made available on GitHub.
A New Dialogue Response Generation Agent for Large Language Models by Asking Questions to Detect User's Intentions
Oct 05, 2023



Large Language Models (LLMs), such as ChatGPT, have recently been applied to various NLP tasks due to its open-domain generation capabilities. However, there are two issues with applying LLMs to dialogue tasks. 1. During the dialogue process, users may have implicit intentions that might be overlooked by LLMs. Consequently, generated responses couldn't align with the user's intentions. 2. It is unlikely for LLMs to encompass all fields comprehensively. In certain specific domains, their knowledge may be incomplete, and LLMs cannot update the latest knowledge in real-time. To tackle these issues, we propose a framework~\emph{using LLM to \textbf{E}nhance dialogue response generation by asking questions to \textbf{D}etect user's \textbf{I}mplicit in\textbf{T}entions} (\textbf{EDIT}). Firstly, EDIT generates open questions related to the dialogue context as the potential user's intention; Then, EDIT answers those questions by interacting with LLMs and searching in domain-specific knowledge bases respectively, and use LLMs to choose the proper answers to questions as extra knowledge; Finally, EDIT enhances response generation by explicitly integrating those extra knowledge. Besides, previous question generation works only focus on asking questions with answers in context. In order to ask open questions, we construct a Context-Open-Question (COQ) dataset. On two task-oriented dialogue tasks (Wizard of Wikipedia and Holl-E), EDIT outperformed other LLMs.
Commonsense Knowledge Graph Completion Via Contrastive Pretraining and Node Clustering
May 26, 2023The nodes in the commonsense knowledge graph (CSKG) are normally represented by free-form short text (e.g., word or phrase). Different nodes may represent the same concept. This leads to the problems of edge sparsity and node redundancy, which challenges CSKG representation and completion. On the one hand, edge sparsity limits the performance of graph representation learning; On the other hand, node redundancy makes different nodes corresponding to the same concept have inconsistent relations with other nodes. To address the two problems, we propose a new CSKG completion framework based on Contrastive Pretraining and Node Clustering (CPNC). Contrastive Pretraining constructs positive and negative head-tail node pairs on CSKG and utilizes contrastive learning to obtain better semantic node representation. Node Clustering aggregates nodes with the same concept into a latent concept, assisting the task of CSKG completion. We evaluate our CPNC approach on two CSKG completion benchmarks (CN-100K and ATOMIC), where CPNC outperforms the state-of-the-art methods. Extensive experiments demonstrate that both Contrastive Pretraining and Node Clustering can significantly improve the performance of CSKG completion. The source code of CPNC is publicly available on \url{https://github.com/NUSTM/CPNC}.
Personality-aware Human-centric Multimodal Reasoning: A New Task
Apr 05, 2023Multimodal reasoning, an area of artificial intelligence that aims at make inferences from multimodal signals such as vision, language and speech, has drawn more and more attention in recent years. People with different personalities may respond differently to the same situation. However, such individual personalities were ignored in the previous studies. In this work, we introduce a new Personality-aware Human-centric Multimodal Reasoning (Personality-aware HMR) task, and accordingly construct a new dataset based on The Big Bang Theory television shows, to predict the behavior of a specific person at a specific moment, given the multimodal information of its past and future moments. The Myers-Briggs Type Indicator (MBTI) was annotated and utilized in the task to represent individuals' personalities. We benchmark the task by proposing three baseline methods, two were adapted from the related tasks and one was newly proposed for our task. The experimental results demonstrate that personality can effectively improve the performance of human-centric multimodal reasoning. To further solve the lack of personality annotation in real-life scenes, we introduce an extended task called Personality-predicted HMR, and propose the corresponding methods, to predict the MBTI personality at first, and then use the predicted personality to help multimodal reasoning. The experimental results show that our method can accurately predict personality and achieves satisfactory multimodal reasoning performance without relying on personality annotations.
Dense-ATOMIC: Construction of Densely-connected and Multi-hop Commonsense Knowledge Graph upon ATOMIC
Oct 14, 2022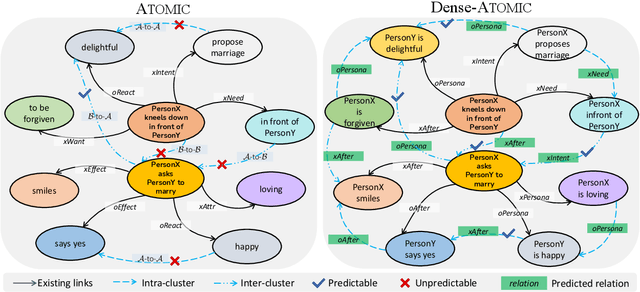

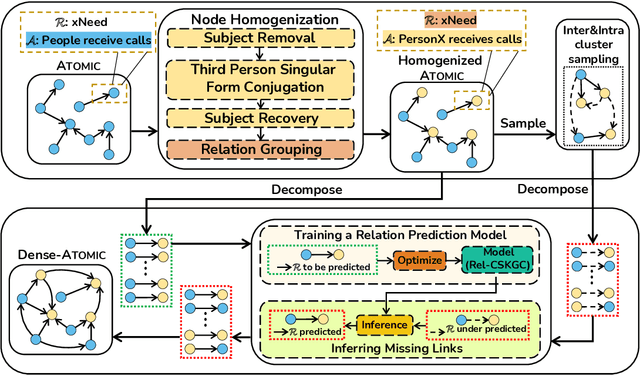

ATOMIC is a large-scale commonsense knowledge graph (CSKG) containing everyday if-then knowledge triplets, i.e., {head event, relation, tail event}. The one-hop annotation manner made ATOMIC a set of independent bipartite graphs, which ignored the numerous missing links between events in different bipartite graphs and consequently caused shortcomings in knowledge coverage and multi-hop reasoning. To address these issues, we propose a CSKG completion approach by training a relation prediction model based on a set of existing triplets, and infer the missing links on ATOMIC. On this basis, we construct Dense-ATOMIC, a densely-connected and multi-hop commonsense knowledge graph. The experimental results on an annotated dense subgraph demonstrate the effectiveness of our CSKG completion approach upon ATOMIC. The evaluation on a downstream commonsense reasoning task also proves the advantage of Dense-ATOMIC against conventional ATOMIC.