 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaramel: Accelerating Decentralized Distributed Deep Learning with Computation Scheduling
Apr 29, 2020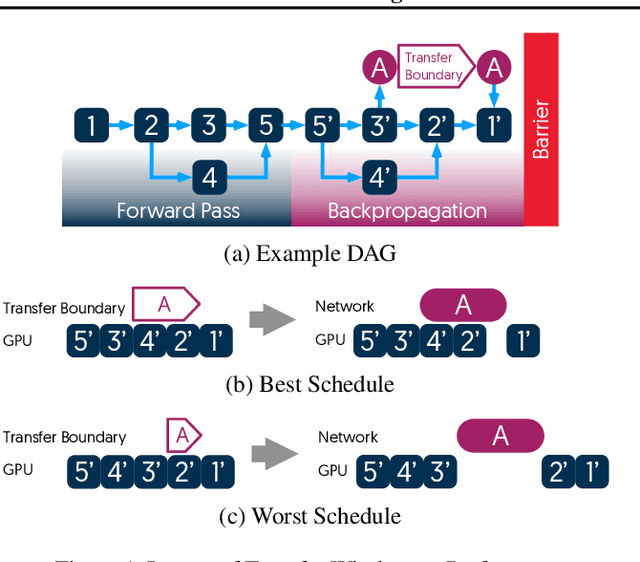
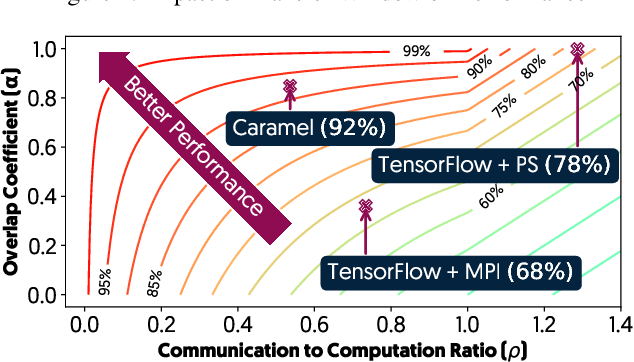
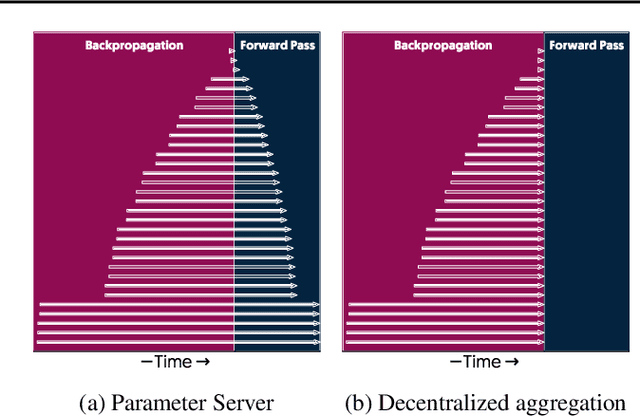
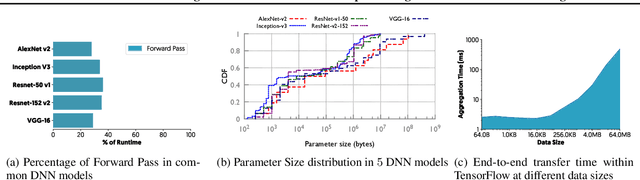
The method of choice for parameter aggregation in Deep Neural Network (DNN) training, a network-intensive task, is shifting from the Parameter Server model to decentralized aggregation schemes (AllReduce) inspired by theoretical guarantees of better performance. However, current implementations of AllReduce overlook the interdependence of communication and computation, resulting in significant performance degradation. In this paper, we develop Caramel, a system that accelerates decentralized distributed deep learning through model-aware computation scheduling and communication optimizations for AllReduce. Caramel achieves this goal through (a) computation DAG scheduling that expands the feasible window of transfer for each parameter (transfer boundaries), and (b) network optimizations for smoothening of the load including adaptive batching and pipelining of parameter transfers. Caramel maintains the correctness of the dataflow model, is hardware-independent, and does not require any user-level or framework-level changes. We implement Caramel over TensorFlow and show that the iteration time of DNN training can be improved by up to 3.62x in a cloud environment.