 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInjecting New Knowledge into Large Language Models via Supervised Fine-Tuning
Paper and Code
Apr 02, 2024

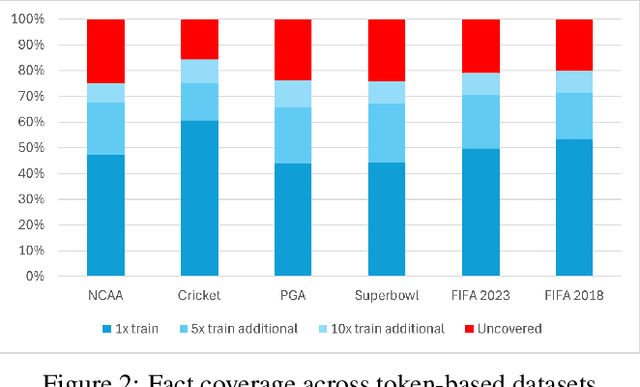

In recent years, Large Language Models (LLMs) have shown remarkable performance in generating human-like text, proving to be a valuable asset across various applications. However, adapting these models to incorporate new, out-of-domain knowledge remains a challenge, particularly for facts and events that occur after the model's knowledge cutoff date. This paper investigates the effectiveness of Supervised Fine-Tuning (SFT) as a method for knowledge injection in LLMs, specifically focusing on the domain of recent sporting events. We compare different dataset generation strategies -- token-based and fact-based scaling -- to create training data that helps the model learn new information. Our experiments on GPT-4 demonstrate that while token-based scaling can lead to improvements in Q&A accuracy, it may not provide uniform coverage of new knowledge. Fact-based scaling, on the other hand, offers a more systematic approach to ensure even coverage across all facts. We present a novel dataset generation process that leads to more effective knowledge ingestion through SFT, and our results show considerable performance improvements in Q&A tasks related to out-of-domain knowledge. This study contributes to the understanding of domain adaptation for LLMs and highlights the potential of SFT in enhancing the factuality of LLM responses in specific knowledge domains.