 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale Fully-Unsupervised Re-Identification
Jul 26, 2023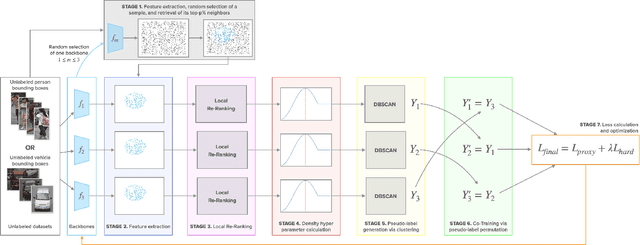
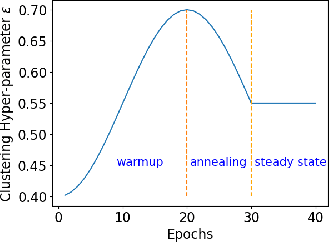


Fully-unsupervised Person and Vehicle Re-Identification have received increasing attention due to their broad applicability in surveillance, forensics, event understanding, and smart cities, without requiring any manual annotation. However, most of the prior art has been evaluated in datasets that have just a couple thousand samples. Such small-data setups often allow the use of costly techniques in time and memory footprints, such as Re-Ranking, to improve clustering results. Moreover, some previous work even pre-selects the best clustering hyper-parameters for each dataset, which is unrealistic in a large-scale fully-unsupervised scenario. In this context, this work tackles a more realistic scenario and proposes two strategies to learn from large-scale unlabeled data. The first strategy performs a local neighborhood sampling to reduce the dataset size in each iteration without violating neighborhood relationships. A second strategy leverages a novel Re-Ranking technique, which has a lower time upper bound complexity and reduces the memory complexity from O(n^2) to O(kn) with k << n. To avoid the pre-selection of specific hyper-parameter values for the clustering algorithm, we also present a novel scheduling algorithm that adjusts the density parameter during training, to leverage the diversity of samples and keep the learning robust to noisy labeling. Finally, due to the complementary knowledge learned by different models, we also introduce a co-training strategy that relies upon the permutation of predicted pseudo-labels, among the backbones, with no need for any hyper-parameters or weighting optimization. The proposed methodology outperforms the state-of-the-art methods in well-known benchmarks and in the challenging large-scale Veri-Wild dataset, with a faster and memory-efficient Re-Ranking strategy, and a large-scale, noisy-robust, and ensemble-based learning approach.
The Age of Synthetic Realities: Challenges and Opportunities
Jun 09, 2023Synthetic realities are digital creations or augmentations that are contextually generated through the use of Artificial Intelligence (AI) methods, leveraging extensive amounts of data to construct new narratives or realities, regardless of the intent to deceive. In this paper, we delve into the concept of synthetic realities and their implications for Digital Forensics and society at large within the rapidly advancing field of AI. We highlight the crucial need for the development of forensic techniques capable of identifying harmful synthetic creations and distinguishing them from reality. This is especially important in scenarios involving the creation and dissemination of fake news, disinformation, and misinformation. Our focus extends to various forms of media, such as images, videos, audio, and text, as we examine how synthetic realities are crafted and explore approaches to detecting these malicious creations. Additionally, we shed light on the key research challenges that lie ahead in this area. This study is of paramount importance due to the rapid progress of AI generative techniques and their impact on the fundamental principles of Forensic Science.
Reasoning for Complex Data through Ensemble-based Self-Supervised Learning
Feb 12, 2022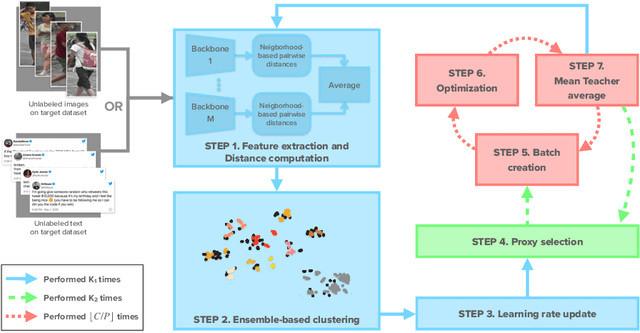
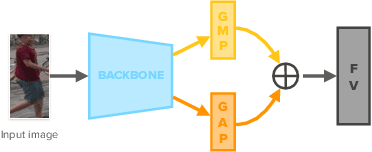
Self-supervised learning deals with problems that have little or no available labeled data. Recent work has shown impressive results when underlying classes have significant semantic differences. One important dataset in which this technique thrives is ImageNet, as intra-class distances are substantially lower than inter-class distances. However, this is not the case for several critical tasks, and general self-supervised learning methods fail to learn discriminative features when classes have closer semantics, thus requiring more robust strategies. We propose a strategy to tackle this problem, and to enable learning from unlabeled data even when samples from different classes are not prominently diverse. We approach the problem by leveraging a novel ensemble-based clustering strategy where clusters derived from different configurations are combined to generate a better grouping for the data samples in a fully-unsupervised way. This strategy allows clusters with different densities and higher variability to emerge, which in turn reduces intra-class discrepancies, without requiring the burden of finding an optimal configuration per dataset. We also consider different Convolutional Neural Networks to compute distances between samples. We refine these distances by performing context analysis and group them to capture complementary information. We consider two applications to validate our pipeline: Person Re-Identification and Text Authorship Verification. These are challenging applications considering that classes are semantically close to each other and that training and test sets have disjoint identities. Our method is robust across different modalities and outperforms state-of-the-art results with a fully-unsupervised solution without any labeling or human intervention.
Unsupervised and self-adaptative techniques for cross-domain person re-identification
Mar 26, 2021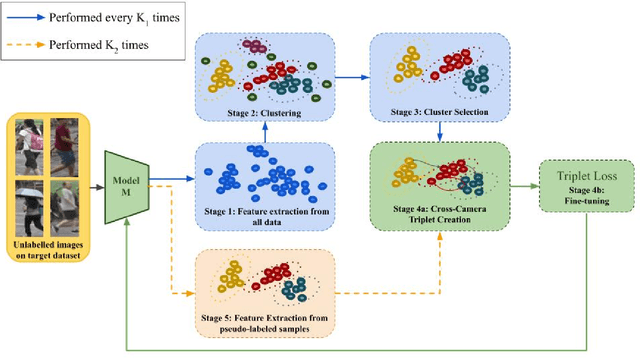
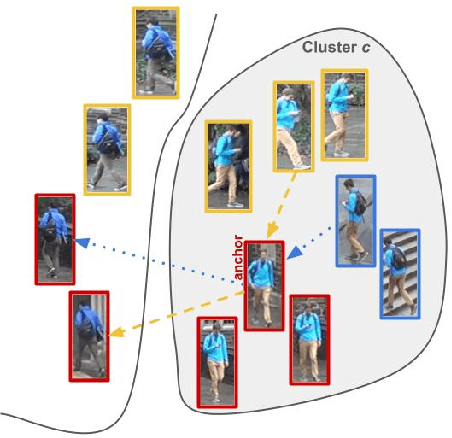
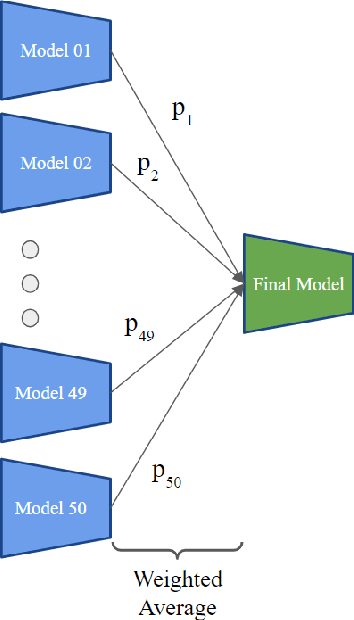
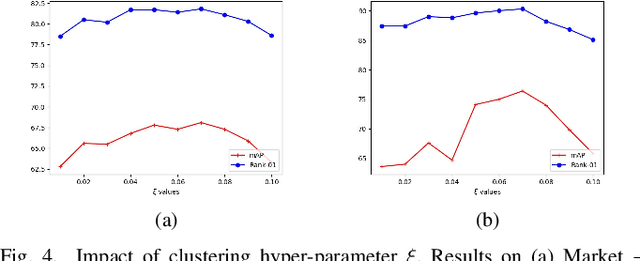
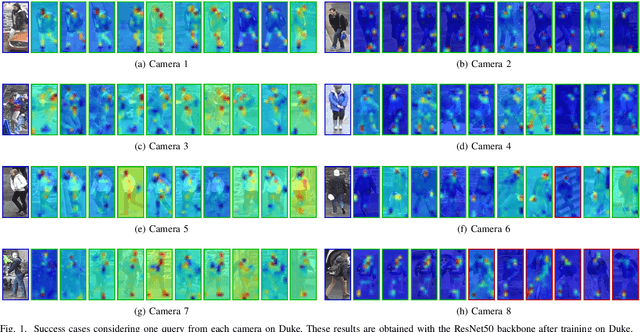
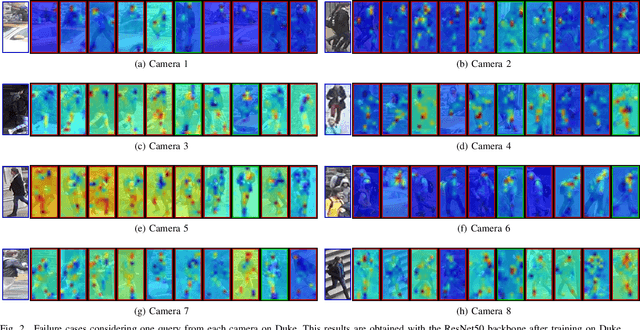
Person Re-Identification (ReID) across non-overlapping cameras is a challenging task and, for this reason, most works in the prior art rely on supervised feature learning from a labeled dataset to match the same person in different views. However, it demands the time-consuming task of labeling the acquired data, prohibiting its fast deployment, specially in forensic scenarios. Unsupervised Domain Adaptation (UDA) emerges as a promising alternative, as it performs feature-learning adaptation from a model trained on a source to a target domain without identity-label annotation. However, most UDA-based algorithms rely upon a complex loss function with several hyper-parameters, which hinders the generalization to different scenarios. Moreover, as UDA depends on the translation between domains, it is important to select the most reliable data from the unseen domain, thus avoiding error propagation caused by noisy examples on the target data -- an often overlooked problem. In this sense, we propose a novel UDA-based ReID method that optimizes a simple loss function with only one hyper-parameter and that takes advantage of triplets of samples created by a new offline strategy based on the diversity of cameras within a cluster. This new strategy adapts the model and also regularizes it, avoiding overfitting on the target domain. We also introduce a new self-ensembling strategy, in which weights from different iterations are aggregated to create a final model combining knowledge from distinct moments of the adaptation. For evaluation, we consider three well-known deep learning architectures and combine them for final decision-making. The proposed method does not use person re-ranking nor any label on the target domain, and outperforms the state of the art, with a much simpler setup, on the Market to Duke, the challenging Market1501 to MSMT17, and Duke to MSMT17 adaptation scenarios.