 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale Fully-Unsupervised Re-Identification
Paper and Code
Jul 26, 2023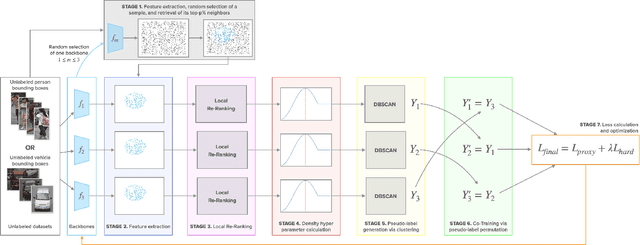
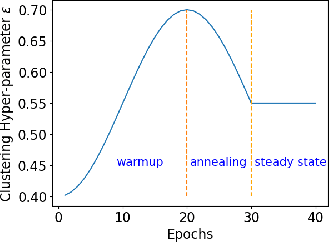


Fully-unsupervised Person and Vehicle Re-Identification have received increasing attention due to their broad applicability in surveillance, forensics, event understanding, and smart cities, without requiring any manual annotation. However, most of the prior art has been evaluated in datasets that have just a couple thousand samples. Such small-data setups often allow the use of costly techniques in time and memory footprints, such as Re-Ranking, to improve clustering results. Moreover, some previous work even pre-selects the best clustering hyper-parameters for each dataset, which is unrealistic in a large-scale fully-unsupervised scenario. In this context, this work tackles a more realistic scenario and proposes two strategies to learn from large-scale unlabeled data. The first strategy performs a local neighborhood sampling to reduce the dataset size in each iteration without violating neighborhood relationships. A second strategy leverages a novel Re-Ranking technique, which has a lower time upper bound complexity and reduces the memory complexity from O(n^2) to O(kn) with k << n. To avoid the pre-selection of specific hyper-parameter values for the clustering algorithm, we also present a novel scheduling algorithm that adjusts the density parameter during training, to leverage the diversity of samples and keep the learning robust to noisy labeling. Finally, due to the complementary knowledge learned by different models, we also introduce a co-training strategy that relies upon the permutation of predicted pseudo-labels, among the backbones, with no need for any hyper-parameters or weighting optimization. The proposed methodology outperforms the state-of-the-art methods in well-known benchmarks and in the challenging large-scale Veri-Wild dataset, with a faster and memory-efficient Re-Ranking strategy, and a large-scale, noisy-robust, and ensemble-based learning approach.