 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised and self-adaptative techniques for cross-domain person re-identification
Paper and Code
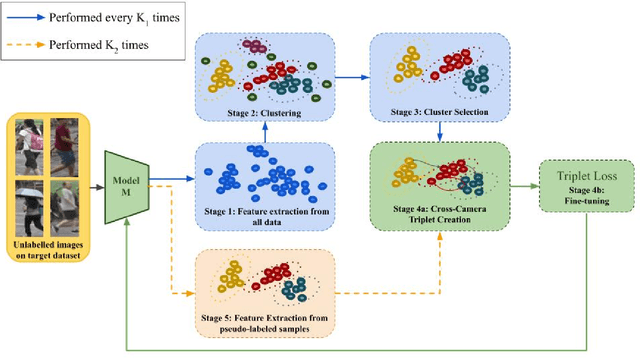
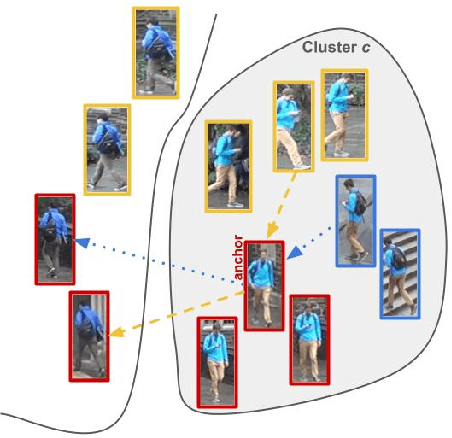
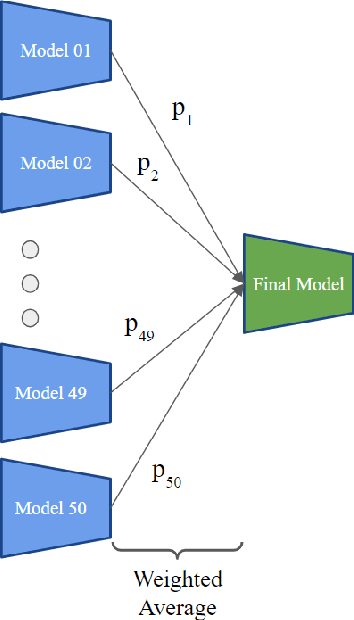
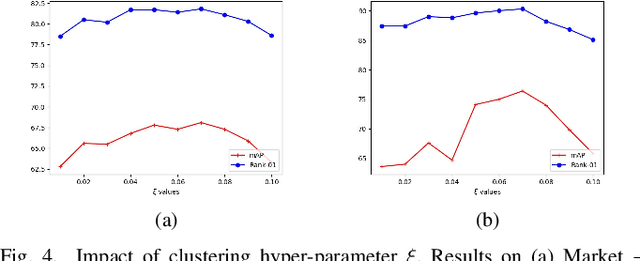
Person Re-Identification (ReID) across non-overlapping cameras is a challenging task and, for this reason, most works in the prior art rely on supervised feature learning from a labeled dataset to match the same person in different views. However, it demands the time-consuming task of labeling the acquired data, prohibiting its fast deployment, specially in forensic scenarios. Unsupervised Domain Adaptation (UDA) emerges as a promising alternative, as it performs feature-learning adaptation from a model trained on a source to a target domain without identity-label annotation. However, most UDA-based algorithms rely upon a complex loss function with several hyper-parameters, which hinders the generalization to different scenarios. Moreover, as UDA depends on the translation between domains, it is important to select the most reliable data from the unseen domain, thus avoiding error propagation caused by noisy examples on the target data -- an often overlooked problem. In this sense, we propose a novel UDA-based ReID method that optimizes a simple loss function with only one hyper-parameter and that takes advantage of triplets of samples created by a new offline strategy based on the diversity of cameras within a cluster. This new strategy adapts the model and also regularizes it, avoiding overfitting on the target domain. We also introduce a new self-ensembling strategy, in which weights from different iterations are aggregated to create a final model combining knowledge from distinct moments of the adaptation. For evaluation, we consider three well-known deep learning architectures and combine them for final decision-making. The proposed method does not use person re-ranking nor any label on the target domain, and outperforms the state of the art, with a much simpler setup, on the Market to Duke, the challenging Market1501 to MSMT17, and Duke to MSMT17 adaptation scenarios.