 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoSA: Locality Aware Sparse Attention for Block-Wise Diffusion Language Models
Apr 13, 2026Block-wise diffusion language models (DLMs) generate multiple tokens in any order, offering a promising alternative to the autoregressive decoding pipeline. However, they still remain bottlenecked by memory-bound attention in long-context scenarios. Naive sparse attention fails on DLMs due to a KV Inflation problem, where different queries select different prefix positions, making the union of accessed KV pages large. To address this, we observe that between consecutive denoising steps, only a small fraction of active tokens exhibit significant hidden-state changes, while the majority of stable tokens remain nearly constant. Based on this insight, we propose LOSA (Locality-aware Sparse Attention), which reuses cached prefix-attention results for stable tokens and applies sparse attention only to active tokens. This substantially shrinks the number of KV indices that must be loaded, yielding both higher speedup and higher accuracy. Across multiple block-wise DLMs and benchmarks, LOSA preserves near-dense accuracy while significantly improving efficiency, achieving up to +9 points in average accuracy at aggressive sparsity levels while maintaining 1.54x lower attention density. It also achieves up to 4.14x attention speedup on RTX A6000 GPUs, demonstrating the effectiveness of the proposed method.
FluidGaussian: Propagating Simulation-Based Uncertainty Toward Functionally-Intelligent 3D Reconstruction
Mar 22, 2026Real objects that inhabit the physical world follow physical laws and thus behave plausibly during interaction with other physical objects. However, current methods that perform 3D reconstructions of real-world scenes from multi-view 2D images optimize primarily for visual fidelity, i.e., they train with photometric losses and reason about uncertainty in the image or representation space. This appearance-centric view overlooks body contacts and couplings, conflates function-critical regions (e.g., aerodynamic or hydrodynamic surfaces) with ornamentation, and reconstructs structures suboptimally, even when physical regularizers are added. All these can lead to unphysical and implausible interactions. To address this, we consider the question: How can 3D reconstruction become aware of real-world interactions and underlying object functionality, beyond visual cues? To answer this question, we propose FluidGaussian, a plug-and-play method that tightly couples geometry reconstruction with ubiquitous fluid-structure interactions to assess surface quality at high granularity. We define a simulation-based uncertainty metric induced by fluid simulations and integrate it with active learning to prioritize views that improve both visual and physical fidelity. In an empirical evaluation on NeRF Synthetic (Blender), Mip-NeRF 360, and DrivAerNet++, our FluidGaussian method yields up to +8.6% visual PSNR (Peak Signal-to-Noise Ratio) and -62.3% velocity divergence during fluid simulations. Our code is available at https://github.com/delta-lab-ai/FluidGaussian.
Modeling Non-Ergodic Path Effects Using Conditional Generative Model for Fourier Amplitude Spectra
Dec 22, 2025Recent developments in non-ergodic ground-motion models (GMMs) explicitly model systematic spatial variations in source, site, and path effects, reducing standard deviation to 30-40% of ergodic models and enabling more accurate site-specific seismic hazard analysis. Current non-ergodic GMMs rely on Gaussian Process (GP) methods with prescribed correlation functions and thus have computational limitations for large-scale predictions. This study proposes a deep-learning approach called Conditional Generative Modeling for Fourier Amplitude Spectra (CGM-FAS) as an alternative to GP-based methods for modeling non-ergodic path effects in Fourier Amplitude Spectra (FAS). CGM-FAS uses a Conditional Variational Autoencoder architecture to learn spatial patterns and interfrequency correlation directly from data by using geographical coordinates of earthquakes and stations as conditional variables. Using San Francisco Bay Area earthquake data, we compare CGM-FAS against a recent GP-based GMM for the region and demonstrate consistent predictions of non-ergodic path effects. Additionally, CGM-FAS offers advantages compared to GP-based approaches in learning spatial patterns without prescribed correlation functions, capturing interfrequency correlations, and enabling rapid predictions, generating maps for 10,000 sites across 1,000 frequencies within 10 seconds using a few GB of memory. CGM-FAS hyperparameters can be tuned to ensure generated path effects exhibit variability consistent with the GP-based empirical GMM. This work demonstrates a promising direction for efficient non-ergodic ground-motion prediction across multiple frequencies and large spatial domains.
Uncertainty-Aware Diagnostics for Physics-Informed Machine Learning
Oct 30, 2025Physics-informed machine learning (PIML) integrates prior physical information, often in the form of differential equation constraints, into the process of fitting machine learning models to physical data. Popular PIML approaches, including neural operators, physics-informed neural networks, neural ordinary differential equations, and neural discrete equilibria, are typically fit to objectives that simultaneously include both data and physical constraints. However, the multi-objective nature of this approach creates ambiguity in the measurement of model quality. This is related to a poor understanding of epistemic uncertainty, and it can lead to surprising failure modes, even when existing statistical metrics suggest strong fits. Working within a Gaussian process regression framework, we introduce the Physics-Informed Log Evidence (PILE) score. Bypassing the ambiguities of test losses, the PILE score is a single, uncertainty-aware metric that provides a selection principle for hyperparameters of a PIML model. We show that PILE minimization yields excellent choices for a wide variety of model parameters, including kernel bandwidth, least squares regularization weights, and even kernel function selection. We also show that, even prior to data acquisition, a special 'data-free' case of the PILE score identifies a priori kernel choices that are 'well-adapted' to a given PDE. Beyond the kernel setting, we anticipate that the PILE score can be extended to PIML at large, and we outline approaches to do so.
Towards Foundation Models for Scientific Machine Learning: Characterizing Scaling and Transfer Behavior
Jun 01, 2023



Pre-trained machine learning (ML) models have shown great performance for a wide range of applications, in particular in natural language processing (NLP) and computer vision (CV). Here, we study how pre-training could be used for scientific machine learning (SciML) applications, specifically in the context of transfer learning. We study the transfer behavior of these models as (i) the pre-trained model size is scaled, (ii) the downstream training dataset size is scaled, (iii) the physics parameters are systematically pushed out of distribution, and (iv) how a single model pre-trained on a mixture of different physics problems can be adapted to various downstream applications. We find that-when fine-tuned appropriately-transfer learning can help reach desired accuracy levels with orders of magnitude fewer downstream examples (across different tasks that can even be out-of-distribution) than training from scratch, with consistent behavior across a wide range of downstream examples. We also find that fine-tuning these models yields more performance gains as model size increases, compared to training from scratch on new downstream tasks. These results hold for a broad range of PDE learning tasks. All in all, our results demonstrate the potential of the "pre-train and fine-tune" paradigm for SciML problems, demonstrating a path towards building SciML foundation models. We open-source our code for reproducibility.
GACT: Activation Compressed Training for General Architectures
Jun 28, 2022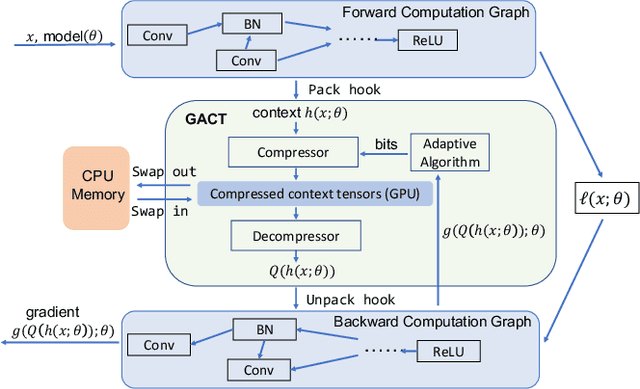
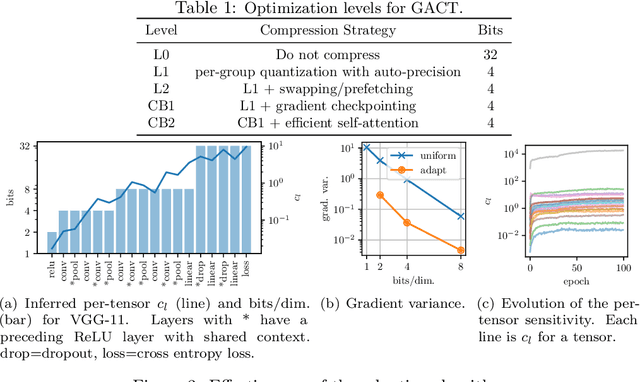

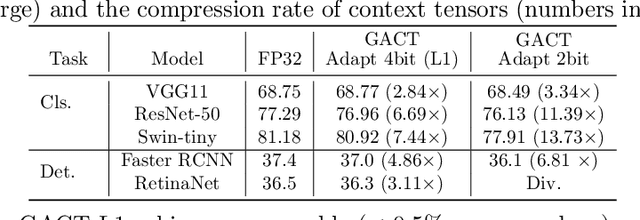
Training large neural network (NN) models requires extensive memory resources, and Activation Compressed Training (ACT) is a promising approach to reduce training memory footprint. This paper presents GACT, an ACT framework to support a broad range of machine learning tasks for generic NN architectures with limited domain knowledge. By analyzing a linearized version of ACT's approximate gradient, we prove the convergence of GACT without prior knowledge on operator type or model architecture. To make training stable, we propose an algorithm that decides the compression ratio for each tensor by estimating its impact on the gradient at run time. We implement GACT as a PyTorch library that readily applies to any NN architecture. GACT reduces the activation memory for convolutional NNs, transformers, and graph NNs by up to 8.1x, enabling training with a 4.2x to 24.7x larger batch size, with negligible accuracy loss.
AutoIP: A United Framework to Integrate Physics into Gaussian Processes
Feb 24, 2022
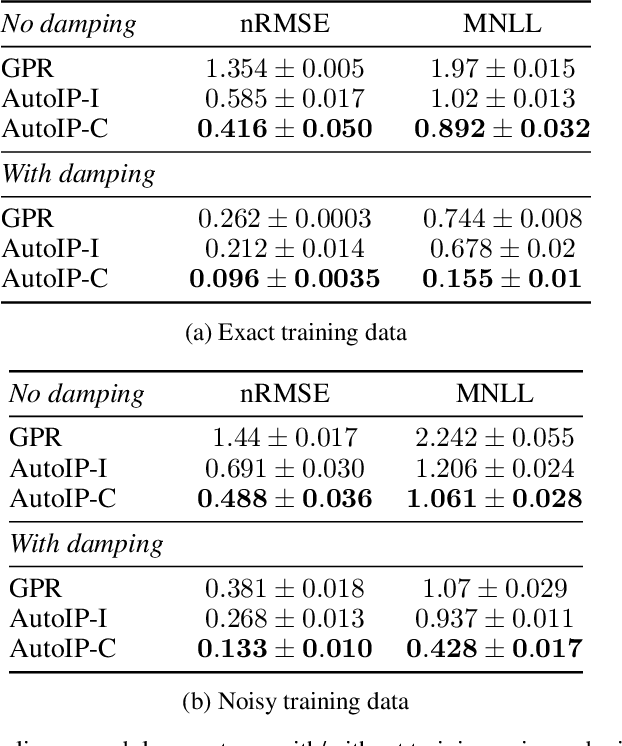
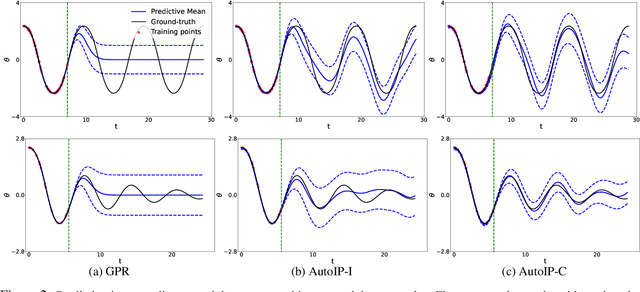

Physics modeling is critical for modern science and engineering applications. From data science perspective, physics knowledge -- often expressed as differential equations -- is valuable in that it is highly complementary to data, and can potentially help overcome data sparsity, noise, inaccuracy, etc. In this work, we propose a simple yet powerful framework that can integrate all kinds of differential equations into Gaussian processes (GPs) to enhance prediction accuracy and uncertainty quantification. These equations can be linear, nonlinear, temporal, time-spatial, complete, incomplete with unknown source terms, etc. Specifically, based on kernel differentiation, we construct a GP prior to jointly sample the values of the target function, equation-related derivatives, and latent source functions from a multivariate Gaussian distribution. The sampled values are fed to two likelihoods -- one is to fit the observations and the other to conform to the equation. We use the whitening trick to evade the strong dependency between the sampled function values and kernel parameters, and develop a stochastic variational learning algorithm. Our method shows improvement upon vanilla GPs in both simulation and several real-world applications, even using rough, incomplete equations.
LocalNewton: Reducing Communication Bottleneck for Distributed Learning
May 16, 2021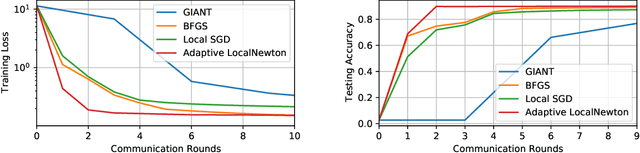
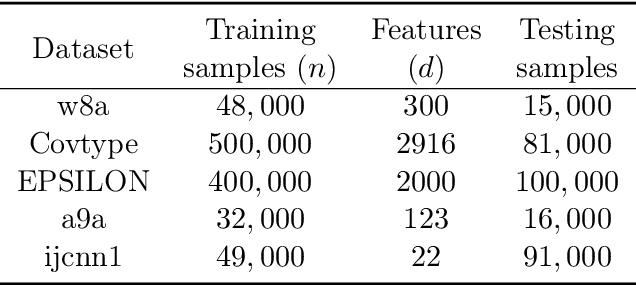
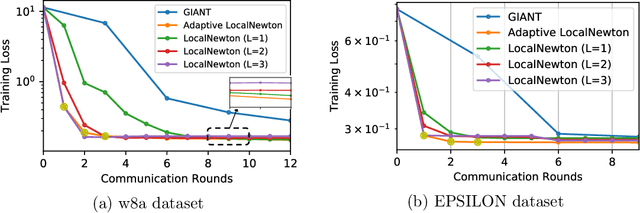

To address the communication bottleneck problem in distributed optimization within a master-worker framework, we propose LocalNewton, a distributed second-order algorithm with local averaging. In LocalNewton, the worker machines update their model in every iteration by finding a suitable second-order descent direction using only the data and model stored in their own local memory. We let the workers run multiple such iterations locally and communicate the models to the master node only once every few (say L) iterations. LocalNewton is highly practical since it requires only one hyperparameter, the number L of local iterations. We use novel matrix concentration-based techniques to obtain theoretical guarantees for LocalNewton, and we validate them with detailed empirical evaluation. To enhance practicability, we devise an adaptive scheme to choose L, and we show that this reduces the number of local iterations in worker machines between two model synchronizations as the training proceeds, successively refining the model quality at the master. Via extensive experiments using several real-world datasets with AWS Lambda workers and an AWS EC2 master, we show that LocalNewton requires fewer than 60% of the communication rounds (between master and workers) and less than 40% of the end-to-end running time, compared to state-of-the-art algorithms, to reach the same training~loss.
Rethinking Batch Normalization in Transformers
Mar 17, 2020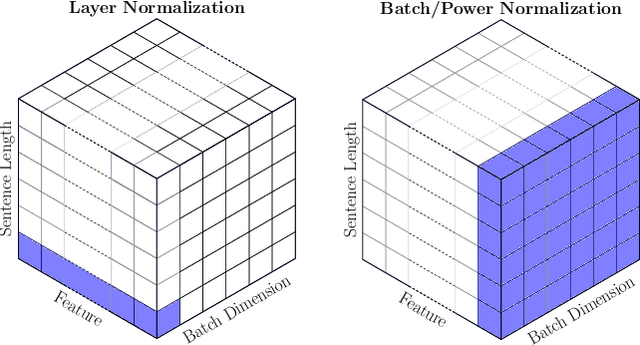
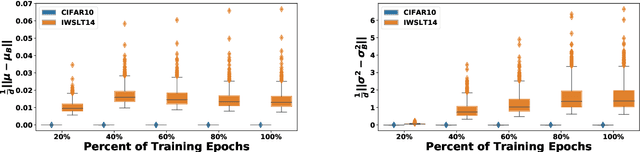
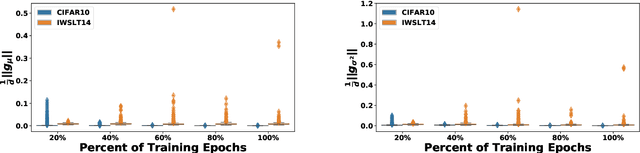
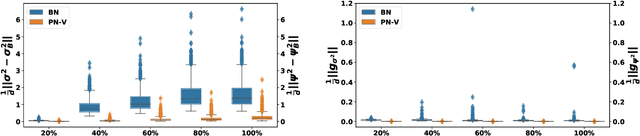
The standard normalization method for neural network (NN) models used in Natural Language Processing (NLP) is layer normalization (LN). This is different than batch normalization (BN), which is widely-adopted in Computer Vision. The preferred use of LN in NLP is principally due to the empirical observation that a (naive/vanilla) use of BN leads to significant performance degradation for NLP tasks; however, a thorough understanding of the underlying reasons for this is not always evident. In this paper, we perform a systematic study of NLP transformer models to understand why BN has a poor performance, as compared to LN. We find that the statistics of NLP data across the batch dimension exhibit large fluctuations throughout training. This results in instability, if BN is naively implemented. To address this, we propose Power Normalization (PN), a novel normalization scheme that resolves this issue by (i) relaxing zero-mean normalization in BN, (ii) incorporating a running quadratic mean instead of per batch statistics to stabilize fluctuations, and (iii) using an approximate backpropagation for incorporating the running statistics in the forward pass. We show theoretically, under mild assumptions, that PN leads to a smaller Lipschitz constant for the loss, compared with BN. Furthermore, we prove that the approximate backpropagation scheme leads to bounded gradients. We extensively test PN for transformers on a range of NLP tasks, and we show that it significantly outperforms both LN and BN. In particular, PN outperforms LN by 0.4/0.6 BLEU on IWSLT14/WMT14 and 5.6/3.0 PPL on PTB/WikiText-103.
PyHessian: Neural Networks Through the Lens of the Hessian
Jan 02, 2020



We present PyHessian, a new scalable framework that enables fast computation of Hessian (i.e., second-order derivative) information for deep neural networks. This framework is developed in Pytorch, and it enables distributed-memory execution on both cloud and supercomputer systems. PyHessian enables fast computations of the top Hessian eigenvalues, the Hessian trace, and the full Hessian eigenvalue/spectral density. This general framework can be used to analyze neural network models, including the topology of the loss landscape (i.e., curvature information) to gain insight into the behavior of different models/optimizers. To illustrate this, we apply PyHessian to analyze the effect of residual connections and Batch Normalization layers on the smoothness of the loss landscape during training. One recent claim, based on simpler first-order analysis, is that residual connections and Batch Normalization make the loss landscape ``smoother,'' thus making it easier for Stochastic Gradient Descent to converge to a good solution. We perform an extensive analysis of this hypothesis, on four residual networks (ResNet20/32/38/56) on the Cifar-10/100 dataset, by measuring directly the Hessian spectrum using PyHessian. This analysis leads to finer-scale insight, demonstrating that while conventional wisdom is sometimes validated, in other cases it is simply incorrect. In particular, we find that Batch Normalization layers do not necessarily make the loss landscape smoother, especially for shallow networks. Instead, the claimed smoother loss landscape only becomes evident for deeper neural networks, at least within this ResNet series. We have open-sourced the PyHessian framework for Hessian spectrum computation.