 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter Re-Initialization through Cyclical Batch Size Schedules
Paper and Code
Dec 04, 2018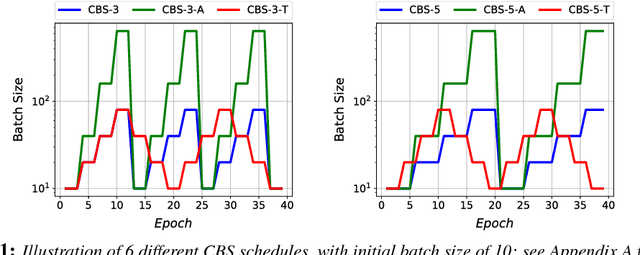
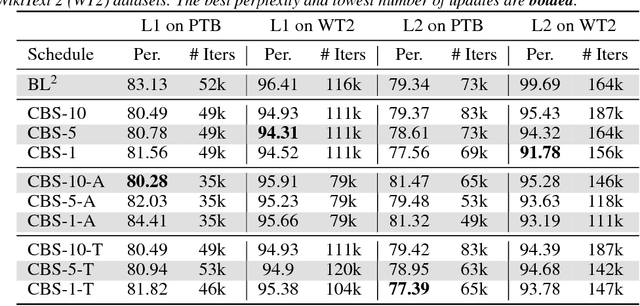
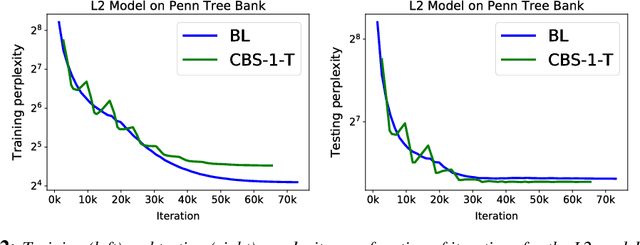
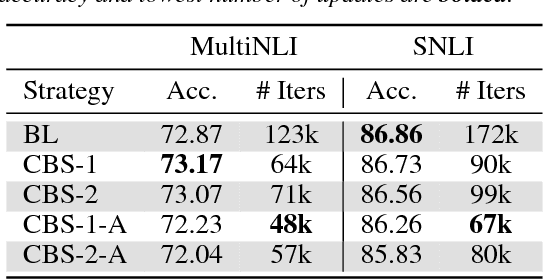
Optimal parameter initialization remains a crucial problem for neural network training. A poor weight initialization may take longer to train and/or converge to sub-optimal solutions. Here, we propose a method of weight re-initialization by repeated annealing and injection of noise in the training process. We implement this through a cyclical batch size schedule motivated by a Bayesian perspective of neural network training. We evaluate our methods through extensive experiments on tasks in language modeling, natural language inference, and image classification. We demonstrate the ability of our method to improve language modeling performance by up to 7.91 perplexity and reduce training iterations by up to $61\%$, in addition to its flexibility in enabling snapshot ensembling and use with adversarial training.