 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIT-LMPC: Safe Information-Theoretic Learning Model Predictive Control for Iterative Tasks
Feb 18, 2026Robots executing iterative tasks in complex, uncertain environments require control strategies that balance robustness, safety, and high performance. This paper introduces a safe information-theoretic learning model predictive control (SIT-LMPC) algorithm for iterative tasks. Specifically, we design an iterative control framework based on an information-theoretic model predictive control algorithm to address a constrained infinite-horizon optimal control problem for discrete-time nonlinear stochastic systems. An adaptive penalty method is developed to ensure safety while balancing optimality. Trajectories from previous iterations are utilized to learn a value function using normalizing flows, which enables richer uncertainty modeling compared to Gaussian priors. SIT-LMPC is designed for highly parallel execution on graphics processing units, allowing efficient real-time optimization. Benchmark simulations and hardware experiments demonstrate that SIT-LMPC iteratively improves system performance while robustly satisfying system constraints.
* 8 pages, 5 figures. Published in IEEE RA-L, vol. 11, no. 1, Jan. 2026. Presented at ICRA 2026
A Constructive Method for Designing Safe Multirate Controllers for Differentially-Flat Systems
Mar 26, 2024We present a multi-rate control architecture that leverages fundamental properties of differential flatness to synthesize controllers for safety-critical nonlinear dynamical systems. We propose a two-layer architecture, where the high-level generates reference trajectories using a linear Model Predictive Controller, and the low-level tracks this reference using a feedback controller. The novelty lies in how we couple these layers, to achieve formal guarantees on recursive feasibility of the MPC problem, and safety of the nonlinear system. Furthermore, using differential flatness, we provide a constructive means to synthesize the multi-rate controller, thereby removing the need to search for suitable Lyapunov or barrier functions, or to approximately linearize/discretize nonlinear dynamics. We show the synthesized controller is a convex optimization problem, making it amenable to real-time implementations. The method is demonstrated experimentally on a ground rover and a quadruped robotic system.
* 6 pages, 3 figures, accepted at IEEE Control Systems Letters 2021
Ensemble Gaussian Processes for Adaptive Autonomous Driving on Multi-friction Surfaces
Mar 23, 2023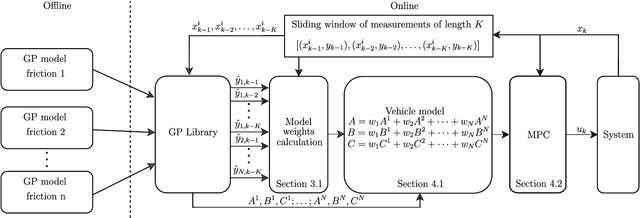
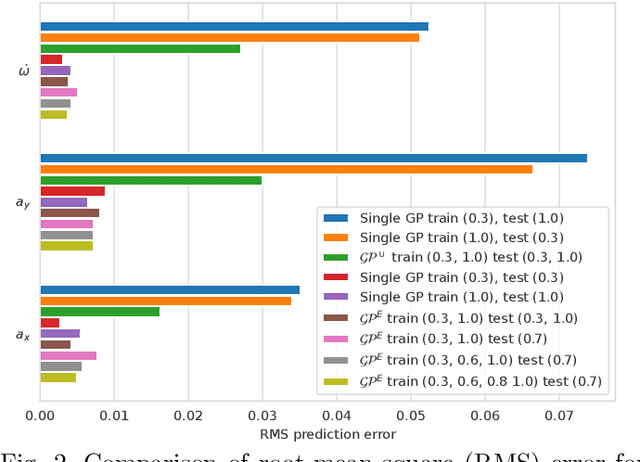
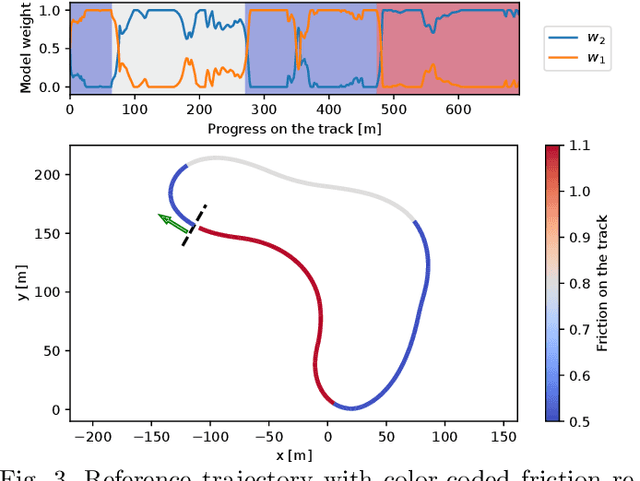
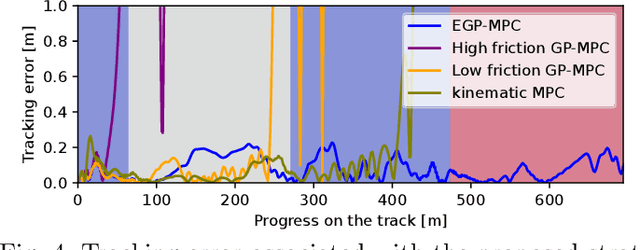
Driving under varying road conditions is challenging, especially for autonomous vehicles that must adapt in real-time to changes in the environment, e.g., rain, snow, etc. It is difficult to apply offline learning-based methods in these time-varying settings, as the controller should be trained on datasets representing all conditions it might encounter in the future. While online learning may adapt a model from real-time data, its convergence is often too slow for fast varying road conditions. We study this problem in autonomous racing, where driving at the limits of handling under varying road conditions is required for winning races. We propose a computationally-efficient approach that leverages an ensemble of Gaussian processes (GPs) to generalize and adapt pre-trained GPs to unseen conditions. Each GP is trained on driving data with a different road surface friction. A time-varying convex combination of these GPs is used within a model predictive control (MPC) framework, where the model weights are adapted online to the current road condition based on real-time data. The predictive variance of the ensemble Gaussian process (EGP) model allows the controller to account for prediction uncertainty and enables safe autonomous driving. Extensive simulations of a full scale autonomous car demonstrated the effectiveness of our proposed EGP-MPC method for providing good tracking performance in varying road conditions and the ability to generalize to unknown maps.
Solving Recurrent MIPs with Semi-supervised Graph Neural Networks
Feb 20, 2023
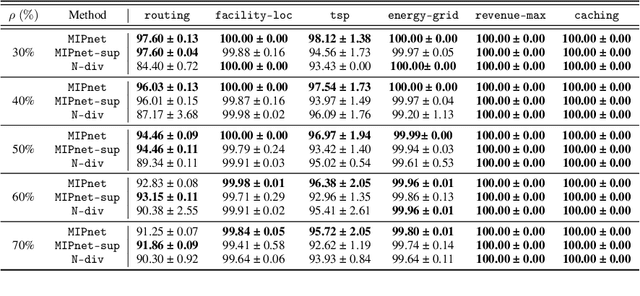
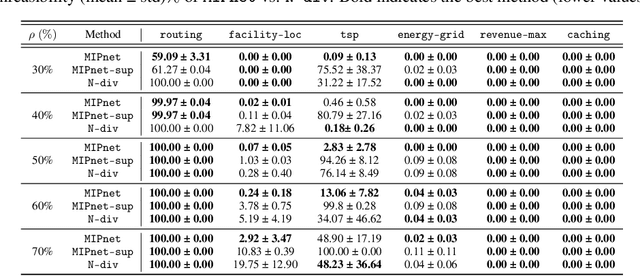
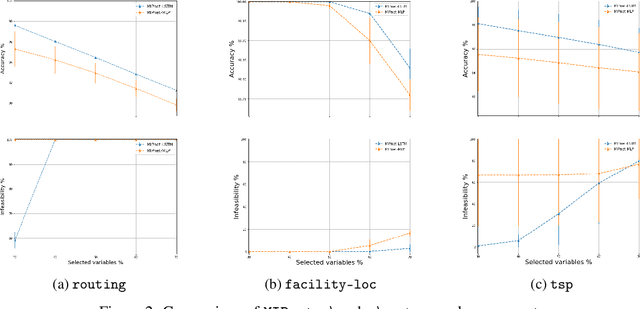
We propose an ML-based model that automates and expedites the solution of MIPs by predicting the values of variables. Our approach is motivated by the observation that many problem instances share salient features and solution structures since they differ only in few (time-varying) parameters. Examples include transportation and routing problems where decisions need to be re-optimized whenever commodity volumes or link costs change. Our method is the first to exploit the sequential nature of the instances being solved periodically, and can be trained with ``unlabeled'' instances, when exact solutions are unavailable, in a semi-supervised setting. Also, we provide a principled way of transforming the probabilistic predictions into integral solutions. Using a battery of experiments with representative binary MIPs, we show the gains of our model over other ML-based optimization approaches.
MLNav: Learning to Safely Navigate on Martian Terrains
Mar 09, 2022
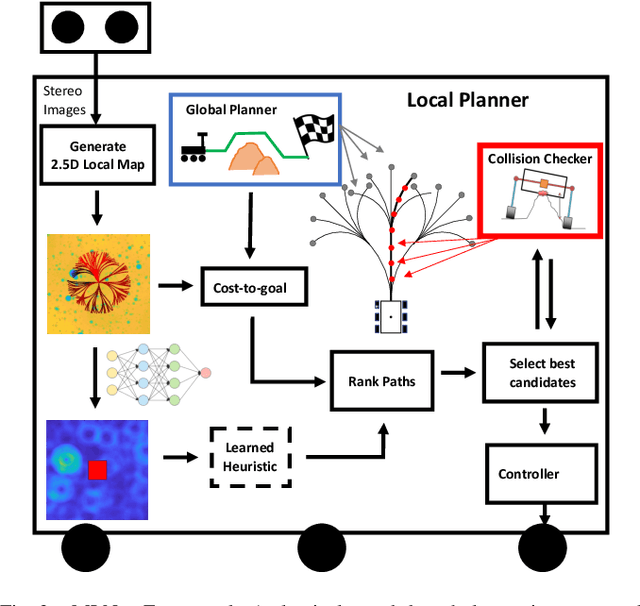
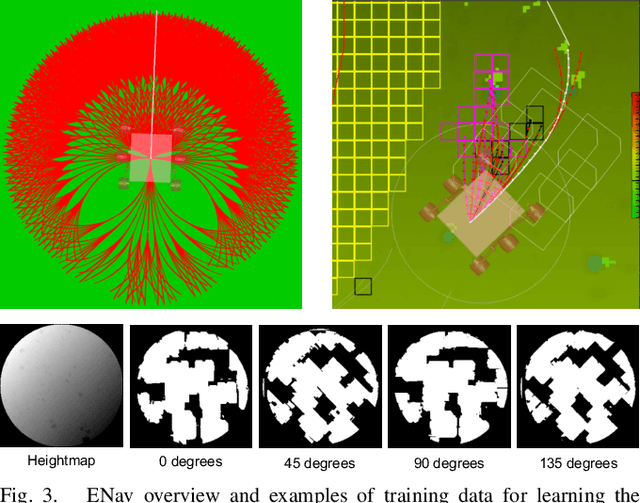

We present MLNav, a learning-enhanced path planning framework for safety-critical and resource-limited systems operating in complex environments, such as rovers navigating on Mars. MLNav makes judicious use of machine learning to enhance the efficiency of path planning while fully respecting safety constraints. In particular, the dominant computational cost in such safety-critical settings is running a model-based safety checker on the proposed paths. Our learned search heuristic can simultaneously predict the feasibility for all path options in a single run, and the model-based safety checker is only invoked on the top-scoring paths. We validate in high-fidelity simulations using both real Martian terrain data collected by the Perseverance rover, as well as a suite of challenging synthetic terrains. Our experiments show that: (i) compared to the baseline ENav path planner on board the Perserverance rover, MLNav can provide a significant improvement in multiple key metrics, such as a 10x reduction in collision checks when navigating real Martian terrains, despite being trained with synthetic terrains; and (ii) MLNav can successfully navigate highly challenging terrains where the baseline ENav fails to find a feasible path before timing out.
Autonomous Vehicles on the Edge: A Survey on Autonomous Vehicle Racing
Feb 14, 2022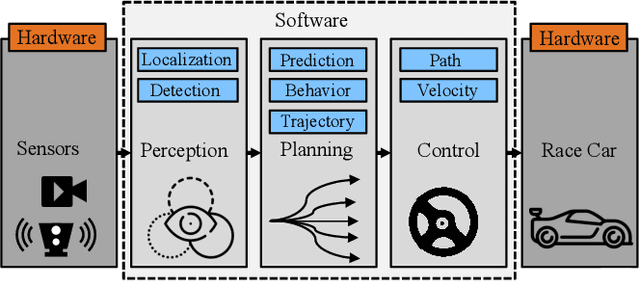
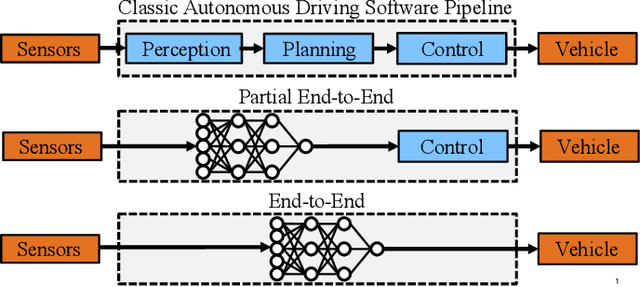

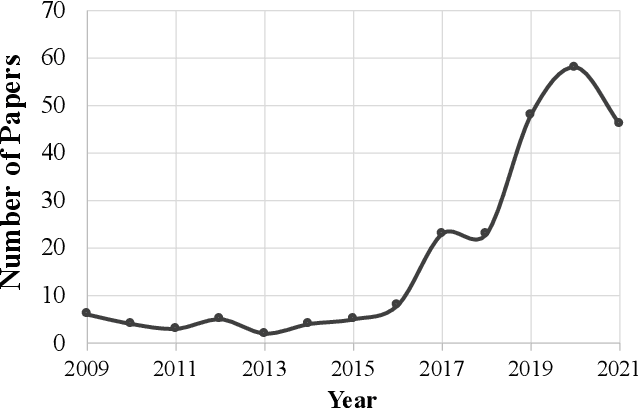
The rising popularity of self-driving cars has led to the emergence of a new research field in the recent years: Autonomous racing. Researchers are developing software and hardware for high performance race vehicles which aim to operate autonomously on the edge of the vehicles limits: High speeds, high accelerations, low reaction times, highly uncertain, dynamic and adversarial environments. This paper represents the first holistic survey that covers the research in the field of autonomous racing. We focus on the field of autonomous racecars only and display the algorithms, methods and approaches that are used in the fields of perception, planning and control as well as end-to-end learning. Further, with an increasing number of autonomous racing competitions, researchers now have access to a range of high performance platforms to test and evaluate their autonomy algorithms. This survey presents a comprehensive overview of the current autonomous racing platforms emphasizing both the software-hardware co-evolution to the current stage. Finally, based on additional discussion with leading researchers in the field we conclude with a summary of open research challenges that will guide future researchers in this field.
CEM-GD: Cross-Entropy Method with Gradient Descent Planner for Model-Based Reinforcement Learning
Dec 14, 2021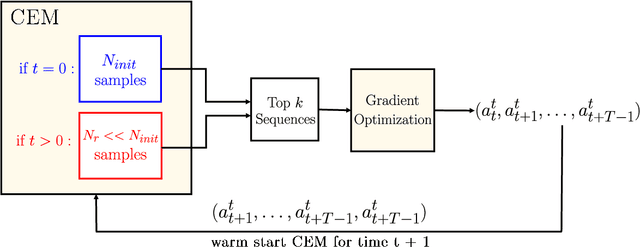
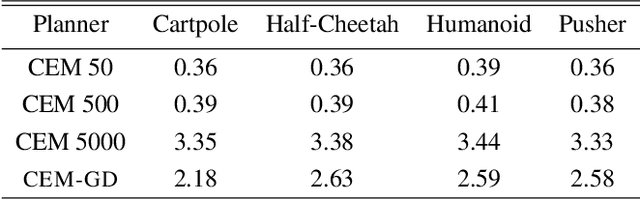
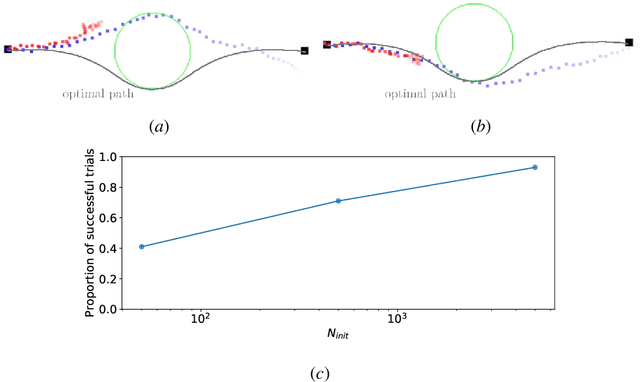
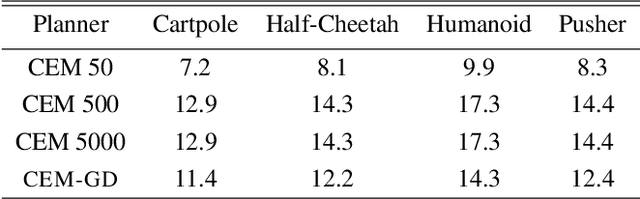
Current state-of-the-art model-based reinforcement learning algorithms use trajectory sampling methods, such as the Cross-Entropy Method (CEM), for planning in continuous control settings. These zeroth-order optimizers require sampling a large number of trajectory rollouts to select an optimal action, which scales poorly for large prediction horizons or high dimensional action spaces. First-order methods that use the gradients of the rewards with respect to the actions as an update can mitigate this issue, but suffer from local optima due to the non-convex optimization landscape. To overcome these issues and achieve the best of both worlds, we propose a novel planner, Cross-Entropy Method with Gradient Descent (CEM-GD), that combines first-order methods with CEM. At the beginning of execution, CEM-GD uses CEM to sample a significant amount of trajectory rollouts to explore the optimization landscape and avoid poor local minima. It then uses the top trajectories as initialization for gradient descent and applies gradient updates to each of these trajectories to find the optimal action sequence. At each subsequent time step, however, CEM-GD samples much fewer trajectories from CEM before applying gradient updates. We show that as the dimensionality of the planning problem increases, CEM-GD maintains desirable performance with a constant small number of samples by using the gradient information, while avoiding local optima using initially well-sampled trajectories. Furthermore, CEM-GD achieves better performance than CEM on a variety of continuous control benchmarks in MuJoCo with 100x fewer samples per time step, resulting in around 25% less computation time and 10% less memory usage. The implementation of CEM-GD is available at $\href{https://github.com/KevinHuang8/CEM-GD}{\text{https://github.com/KevinHuang8/CEM-GD}}$.
Mixed Observable RRT: Multi-Agent Mission-Planning in Partially Observable Environments
Oct 03, 2021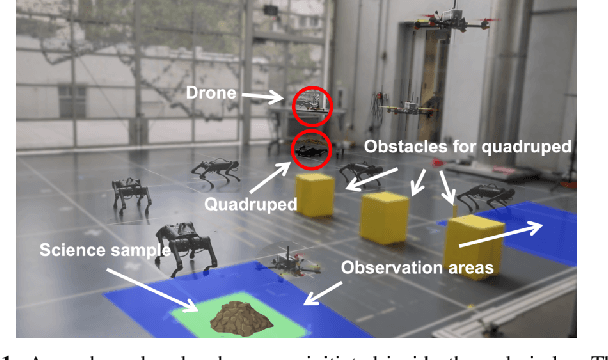
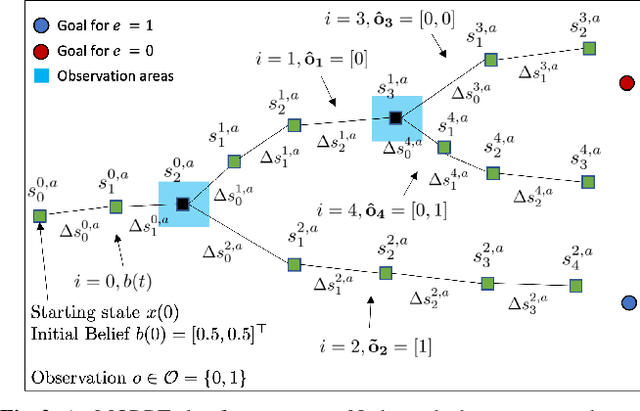

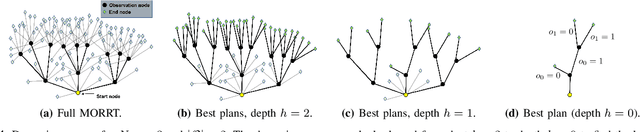
This paper considers centralized mission-planning for a heterogeneous multi-agent system with the aim of locating a hidden target. We propose a mixed observable setting, consisting of a fully observable state-space and a partially observable environment, using a hidden Markov model. First, we construct rapidly exploring random trees (RRTs) to introduce the mixed observable RRT for finding plausible mission plans giving way-points for each agent. Leveraging this construction, we present a path-selection strategy based on a dynamic programming approach, which accounts for the uncertainty from partial observations and minimizes the expected cost. Finally, we combine the high-level plan with model predictive controllers to evaluate the approach on an experimental setup consisting of a quadruped robot and a drone. It is shown that agents are able to make intelligent decisions to explore the area efficiently and to locate the target through collaborative actions.
Interactive multi-modal motion planning with Branch Model Predictive Control
Sep 18, 2021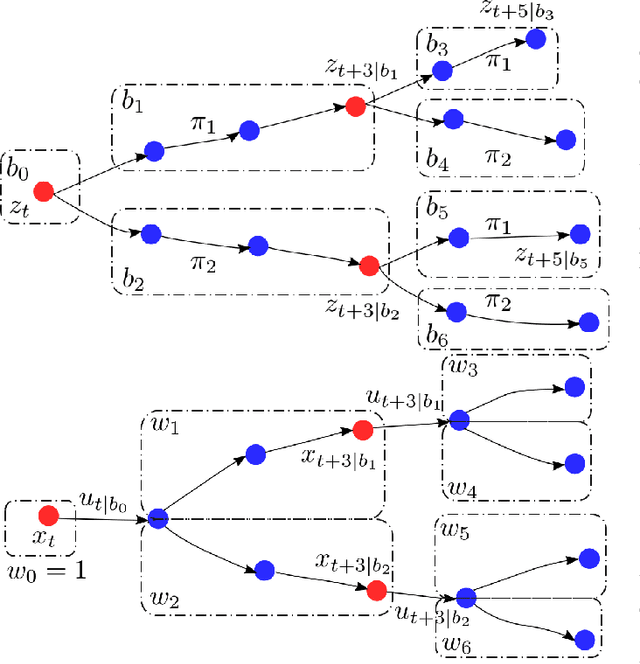
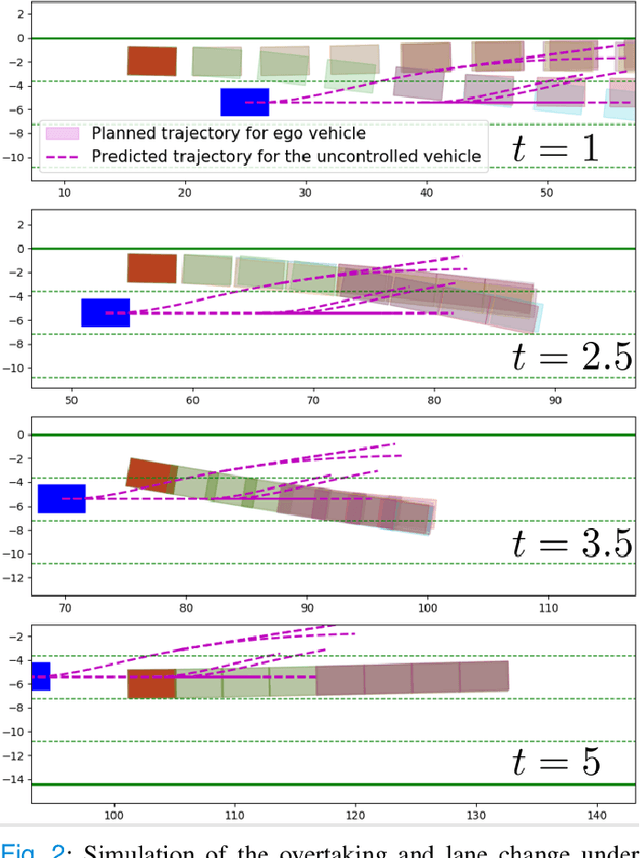

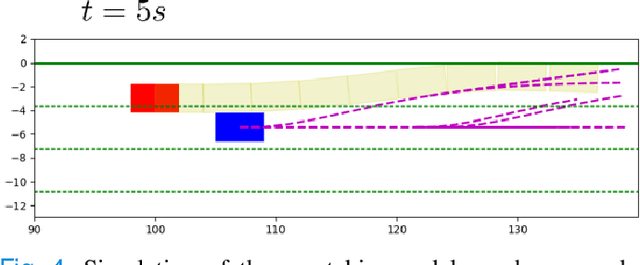
Motion planning for autonomous robots and vehicles in presence of uncontrolled agents remains a challenging problem as the reactive behaviors of the uncontrolled agents must be considered. Since the uncontrolled agents usually demonstrate multimodal reactive behavior, the motion planner needs to solve a continuous motion planning problem under these behaviors, which contains a discrete element. We propose a branch Model Predictive Control (MPC) framework that plans over feedback policies to leverage the reactive behavior of the uncontrolled agent. In particular, a scenario tree is constructed from a finite set of policies of the uncontrolled agent, and the branch MPC solves for a feedback policy in the form of a trajectory tree, which shares the same topology as the scenario tree. Moreover, coherent risk measures such as the Conditional Value at Risk (CVaR) are used as a tuning knob to adjust the tradeoff between performance and robustness. The proposed branch MPC framework is tested on an overtake and lane change task and a merging task for autonomous vehicles in simulation, and on the motion planning of an autonomous quadruped robot alongside an uncontrolled quadruped in experiments. The result demonstrates interesting human-like behaviors, achieving a balance between safety and performance.
Risk-Averse Decision Making Under Uncertainty
Sep 09, 2021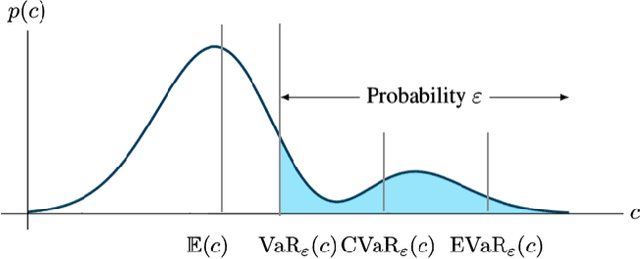

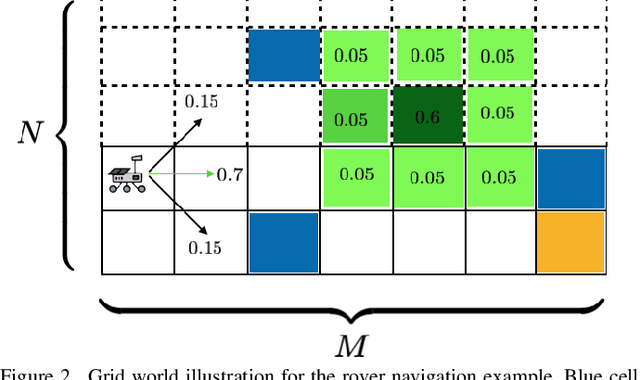

A large class of decision making under uncertainty problems can be described via Markov decision processes (MDPs) or partially observable MDPs (POMDPs), with application to artificial intelligence and operations research, among others. Traditionally, policy synthesis techniques are proposed such that a total expected cost or reward is minimized or maximized. However, optimality in the total expected cost sense is only reasonable if system behavior in the large number of runs is of interest, which has limited the use of such policies in practical mission-critical scenarios, wherein large deviations from the expected behavior may lead to mission failure. In this paper, we consider the problem of designing policies for MDPs and POMDPs with objectives and constraints in terms of dynamic coherent risk measures, which we refer to as the constrained risk-averse problem. For MDPs, we reformulate the problem into a infsup problem via the Lagrangian framework and propose an optimization-based method to synthesize Markovian policies. For MDPs, we demonstrate that the formulated optimization problems are in the form of difference convex programs (DCPs) and can be solved by the disciplined convex-concave programming (DCCP) framework. We show that these results generalize linear programs for constrained MDPs with total discounted expected costs and constraints. For POMDPs, we show that, if the coherent risk measures can be defined as a Markov risk transition mapping, an infinite-dimensional optimization can be used to design Markovian belief-based policies. For stochastic finite-state controllers (FSCs), we show that the latter optimization simplifies to a (finite-dimensional) DCP and can be solved by the DCCP framework. We incorporate these DCPs in a policy iteration algorithm to design risk-averse FSCs for POMDPs.