 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRisk-Averse Decision Making Under Uncertainty
Paper and Code
Sep 09, 2021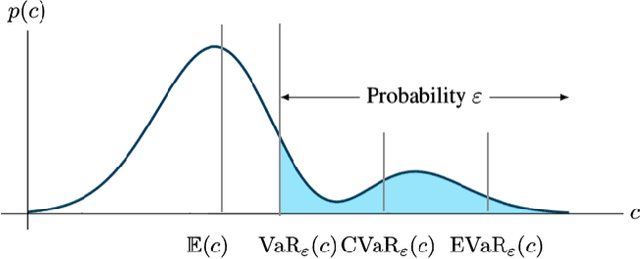


A large class of decision making under uncertainty problems can be described via Markov decision processes (MDPs) or partially observable MDPs (POMDPs), with application to artificial intelligence and operations research, among others. Traditionally, policy synthesis techniques are proposed such that a total expected cost or reward is minimized or maximized. However, optimality in the total expected cost sense is only reasonable if system behavior in the large number of runs is of interest, which has limited the use of such policies in practical mission-critical scenarios, wherein large deviations from the expected behavior may lead to mission failure. In this paper, we consider the problem of designing policies for MDPs and POMDPs with objectives and constraints in terms of dynamic coherent risk measures, which we refer to as the constrained risk-averse problem. For MDPs, we reformulate the problem into a infsup problem via the Lagrangian framework and propose an optimization-based method to synthesize Markovian policies. For MDPs, we demonstrate that the formulated optimization problems are in the form of difference convex programs (DCPs) and can be solved by the disciplined convex-concave programming (DCCP) framework. We show that these results generalize linear programs for constrained MDPs with total discounted expected costs and constraints. For POMDPs, we show that, if the coherent risk measures can be defined as a Markov risk transition mapping, an infinite-dimensional optimization can be used to design Markovian belief-based policies. For stochastic finite-state controllers (FSCs), we show that the latter optimization simplifies to a (finite-dimensional) DCP and can be solved by the DCCP framework. We incorporate these DCPs in a policy iteration algorithm to design risk-averse FSCs for POMDPs.