 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOntology-Driven Robotic Specification Synthesis
Feb 05, 2026This paper addresses robotic system engineering for safety- and mission-critical applications by bridging the gap between high-level objectives and formal, executable specifications. The proposed method, Robotic System Task to Model Transformation Methodology (RSTM2) is an ontology-driven, hierarchical approach using stochastic timed Petri nets with resources, enabling Monte Carlo simulations at mission, system, and subsystem levels. A hypothetical case study demonstrates how the RSTM2 method supports architectural trades, resource allocation, and performance analysis under uncertainty. Ontological concepts further enable explainable AI-based assistants, facilitating fully autonomous specification synthesis. The methodology offers particular benefits to complex multi-robot systems, such as the NASA CADRE mission, representing decentralized, resource-aware, and adaptive autonomous systems of the future.
Risk-Averse Decision Making Under Uncertainty
Sep 09, 2021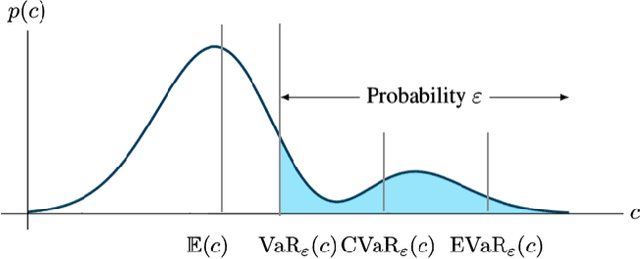


A large class of decision making under uncertainty problems can be described via Markov decision processes (MDPs) or partially observable MDPs (POMDPs), with application to artificial intelligence and operations research, among others. Traditionally, policy synthesis techniques are proposed such that a total expected cost or reward is minimized or maximized. However, optimality in the total expected cost sense is only reasonable if system behavior in the large number of runs is of interest, which has limited the use of such policies in practical mission-critical scenarios, wherein large deviations from the expected behavior may lead to mission failure. In this paper, we consider the problem of designing policies for MDPs and POMDPs with objectives and constraints in terms of dynamic coherent risk measures, which we refer to as the constrained risk-averse problem. For MDPs, we reformulate the problem into a infsup problem via the Lagrangian framework and propose an optimization-based method to synthesize Markovian policies. For MDPs, we demonstrate that the formulated optimization problems are in the form of difference convex programs (DCPs) and can be solved by the disciplined convex-concave programming (DCCP) framework. We show that these results generalize linear programs for constrained MDPs with total discounted expected costs and constraints. For POMDPs, we show that, if the coherent risk measures can be defined as a Markov risk transition mapping, an infinite-dimensional optimization can be used to design Markovian belief-based policies. For stochastic finite-state controllers (FSCs), we show that the latter optimization simplifies to a (finite-dimensional) DCP and can be solved by the DCCP framework. We incorporate these DCPs in a policy iteration algorithm to design risk-averse FSCs for POMDPs.
Constrained Risk-Averse Markov Decision Processes
Dec 04, 2020
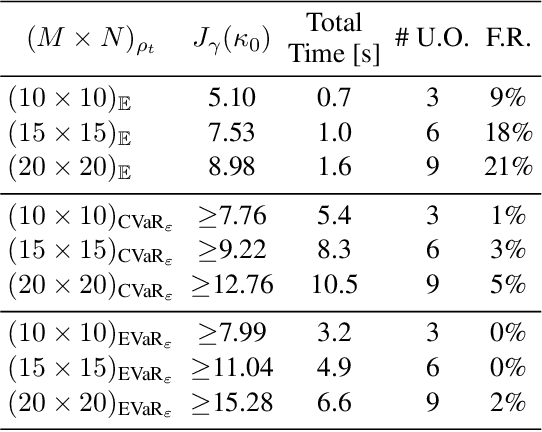
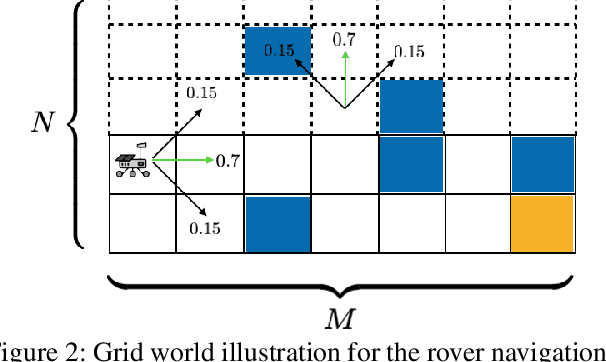

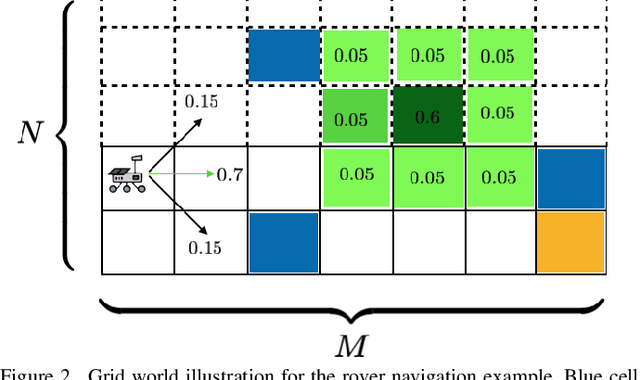
We consider the problem of designing policies for Markov decision processes (MDPs) with dynamic coherent risk objectives and constraints. We begin by formulating the problem in a Lagrangian framework. Under the assumption that the risk objectives and constraints can be represented by a Markov risk transition mapping, we propose an optimization-based method to synthesize Markovian policies that lower-bound the constrained risk-averse problem. We demonstrate that the formulated optimization problems are in the form of difference convex programs (DCPs) and can be solved by the disciplined convex-concave programming (DCCP) framework. We show that these results generalize linear programs for constrained MDPs with total discounted expected costs and constraints. Finally, we illustrate the effectiveness of the proposed method with numerical experiments on a rover navigation problem involving conditional-value-at-risk (CVaR) and entropic-value-at-risk (EVaR) coherent risk measures.
Partially Observable Games for Secure Autonomy
Feb 05, 2020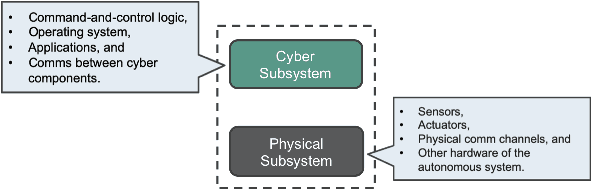



Technology development efforts in autonomy and cyber-defense have been evolving independently of each other, over the past decade. In this paper, we report our ongoing effort to integrate these two presently distinct areas into a single framework. To this end, we propose the two-player partially observable stochastic game formalism to capture both high-level autonomous mission planning under uncertainty and adversarial decision making subject to imperfect information. We show that synthesizing sub-optimal strategies for such games is possible under finite-memory assumptions for both the autonomous decision maker and the cyber-adversary. We then describe an experimental testbed to evaluate the efficacy of the proposed framework.
Risk-Averse Planning Under Uncertainty
Sep 27, 2019

We consider the problem of designing policies for partially observable Markov decision processes (POMDPs) with dynamic coherent risk objectives. Synthesizing risk-averse optimal policies for POMDPs requires infinite memory and thus undecidable. To overcome this difficulty, we propose a method based on bounded policy iteration for designing stochastic but finite state (memory) controllers, which takes advantage of standard convex optimization methods. Given a memory budget and optimality criterion, the proposed method modifies the stochastic finite state controller leading to sub-optimal solutions with lower coherent risk.