 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartially Lazy Gradient Descent for Smoothed Online Learning
Jan 22, 2026We introduce $k$-lazyGD, an online learning algorithm that bridges the gap between greedy Online Gradient Descent (OGD, for $k=1$) and lazy GD/dual-averaging (for $k=T$), creating a spectrum between reactive and stable updates. We analyze this spectrum in Smoothed Online Convex Optimization (SOCO), where the learner incurs both hitting and movement costs. Our main contribution is establishing that laziness is possible without sacrificing hitting performance: we prove that $k$-lazyGD achieves the optimal dynamic regret $\mathcal{O}(\sqrt{(P_T+1)T})$ for any laziness slack $k$ up to $Θ(\sqrt{T/P_T})$, where $P_T$ is the comparator path length. This result formally connects the allowable laziness to the comparator's shifts, showing that $k$-lazyGD can retain the inherently small movements of lazy methods without compromising tracking ability. We base our analysis on the Follow the Regularized Leader (FTRL) framework, and derive a matching lower bound. Since the slack depends on $P_T$, an ensemble of learners with various slacks is used, yielding a method that is provably stable when it can be, and agile when it must be.
Meta-Learning-Based Handover Management in NextG O-RAN
Dec 26, 2025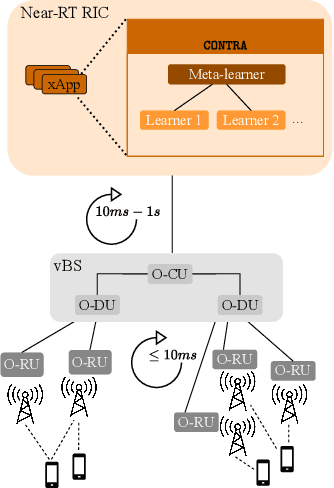
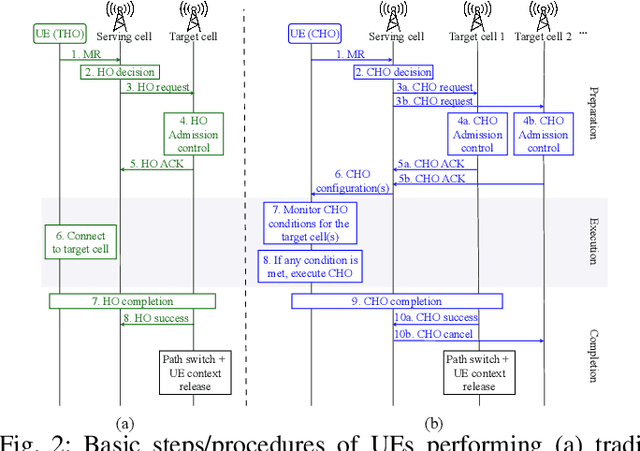
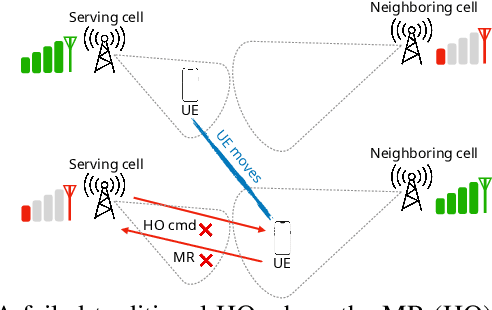
While traditional handovers (THOs) have served as a backbone for mobile connectivity, they increasingly suffer from failures and delays, especially in dense deployments and high-frequency bands. To address these limitations, 3GPP introduced Conditional Handovers (CHOs) that enable proactive cell reservations and user-driven execution. However, both handover (HO) types present intricate trade-offs in signaling, resource usage, and reliability. This paper presents unique, countrywide mobility management datasets from a top-tier mobile network operator (MNO) that offer fresh insights into these issues and call for adaptive and robust HO control in next-generation networks. Motivated by these findings, we propose CONTRA, a framework that, for the first time, jointly optimizes THOs and CHOs within the O-RAN architecture. We study two variants of CONTRA: one where users are a priori assigned to one of the HO types, reflecting distinct service or user-specific requirements, as well as a more dynamic formulation where the controller decides on-the-fly the HO type, based on system conditions and needs. To this end, it relies on a practical meta-learning algorithm that adapts to runtime observations and guarantees performance comparable to an oracle with perfect future information (universal no-regret). CONTRA is specifically designed for near-real-time deployment as an O-RAN xApp and aligns with the 6G goals of flexible and intelligent control. Extensive evaluations leveraging crowdsourced datasets show that CONTRA improves user throughput and reduces both THO and CHO switching costs, outperforming 3GPP-compliant and Reinforcement Learning (RL) baselines in dynamic and real-world scenarios.
CHOMET: Conditional Handovers via Meta-Learning
Jul 10, 2025Handovers (HOs) are the cornerstone of modern cellular networks for enabling seamless connectivity to a vast and diverse number of mobile users. However, as mobile networks become more complex with more diverse users and smaller cells, traditional HOs face significant challenges, such as prolonged delays and increased failures. To mitigate these issues, 3GPP introduced conditional handovers (CHOs), a new type of HO that enables the preparation (i.e., resource allocation) of multiple cells for a single user to increase the chance of HO success and decrease the delays in the procedure. Despite its advantages, CHO introduces new challenges that must be addressed, including efficient resource allocation and managing signaling/communication overhead from frequent cell preparations and releases. This paper presents a novel framework aligned with the O-RAN paradigm that leverages meta-learning for CHO optimization, providing robust dynamic regret guarantees and demonstrating at least 180% superior performance than other 3GPP benchmarks in volatile signal conditions.
On the Dynamic Regret of Following the Regularized Leader: Optimism with History Pruning
May 28, 2025We revisit the Follow the Regularized Leader (FTRL) framework for Online Convex Optimization (OCO) over compact sets, focusing on achieving dynamic regret guarantees. Prior work has highlighted the framework's limitations in dynamic environments due to its tendency to produce "lazy" iterates. However, building on insights showing FTRL's ability to produce "agile" iterates, we show that it can indeed recover known dynamic regret bounds through optimistic composition of future costs and careful linearization of past costs, which can lead to pruning some of them. This new analysis of FTRL against dynamic comparators yields a principled way to interpolate between greedy and agile updates and offers several benefits, including refined control over regret terms, optimism without cyclic dependence, and the application of minimal recursive regularization akin to AdaFTRL. More broadly, we show that it is not the lazy projection style of FTRL that hinders (optimistic) dynamic regret, but the decoupling of the algorithm's state (linearized history) from its iterates, allowing the state to grow arbitrarily. Instead, pruning synchronizes these two when necessary.
Optimistic Learning for Communication Networks
Apr 04, 2025AI/ML-based tools are at the forefront of resource management solutions for communication networks. Deep learning, in particular, is highly effective in facilitating fast and high-performing decision-making whenever representative training data is available to build offline accurate models. Conversely, online learning solutions do not require training and enable adaptive decisions based on runtime observations, alas are often overly conservative. This extensive tutorial proposes the use of optimistic learning (OpL) as a decision engine for resource management frameworks in modern communication systems. When properly designed, such solutions can achieve fast and high-performing decisions -- comparable to offline-trained models -- while preserving the robustness and performance guarantees of the respective online learning approaches. We introduce the fundamental concepts, algorithms and results of OpL, discuss the roots of this theory and present different approaches to defining and achieving optimism. We proceed to showcase how OpL can enhance resource management in communication networks for several key problems such as caching, edge computing, network slicing, and workload assignment in decentralized O-RAN platforms. Finally, we discuss the open challenges that must be addressed to unlock the full potential of this new resource management approach.
Smooth Handovers via Smoothed Online Learning
Jan 14, 2025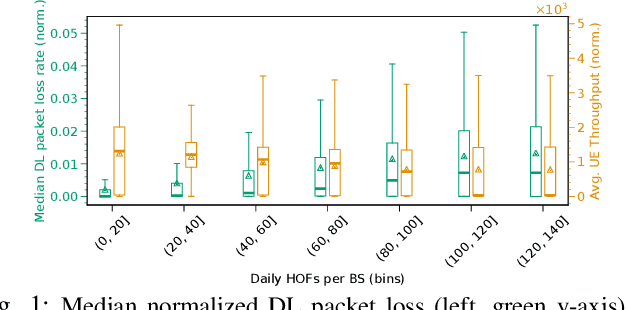
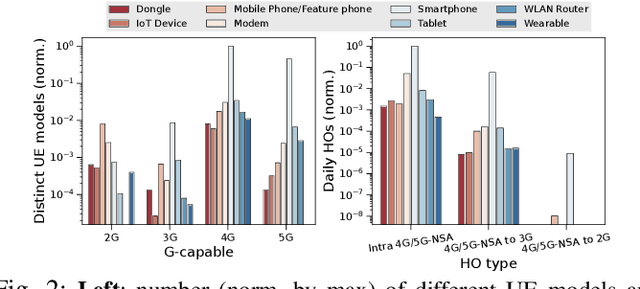
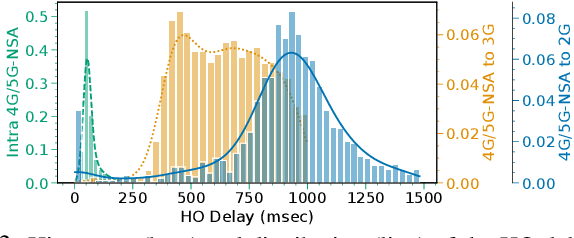
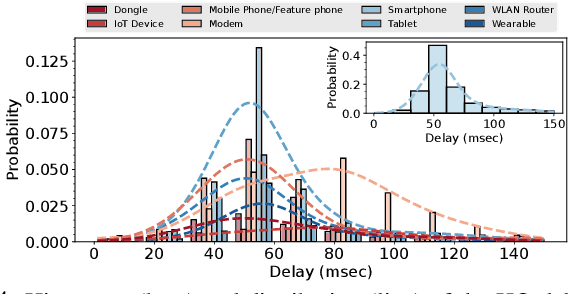
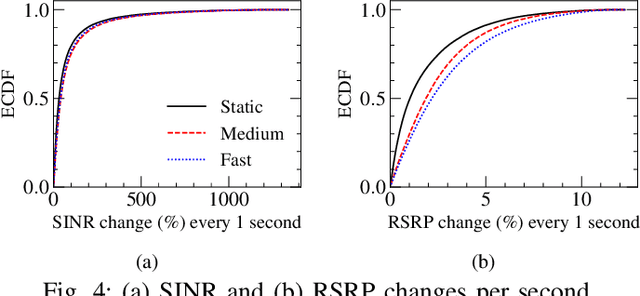
With users demanding seamless connectivity, handovers (HOs) have become a fundamental element of cellular networks. However, optimizing HOs is a challenging problem, further exacerbated by the growing complexity of mobile networks. This paper presents the first countrywide study of HO optimization, through the prism of Smoothed Online Learning (SOL). We first analyze an extensive dataset from a commercial mobile network operator (MNO) in Europe with more than 40M users, to understand and reveal important features and performance impacts on HOs. Our findings highlight a correlation between HO failures/delays, and the characteristics of radio cells and end-user devices, showcasing the impact of heterogeneity in mobile networks nowadays. We subsequently model UE-cell associations as dynamic decisions and propose a realistic system model for smooth and accurate HOs that extends existing approaches by (i) incorporating device and cell features on HO optimization, and (ii) eliminating (prior) strong assumptions about requiring future signal measurements and knowledge of end-user mobility. Our algorithm, aligned with the O-RAN paradigm, provides robust dynamic regret guarantees, even in challenging environments, and shows superior performance in multiple scenarios with real-world and synthetic data.
Optimistic Online Non-stochastic Control via FTRL
Apr 04, 2024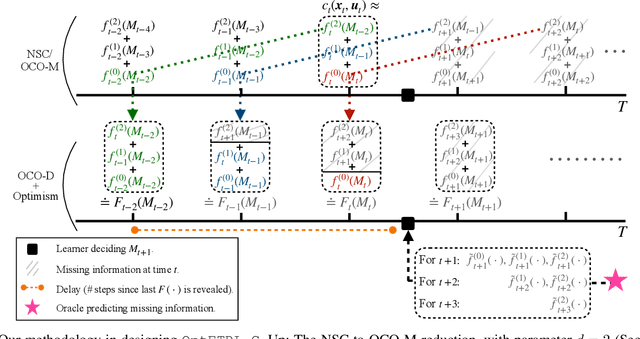
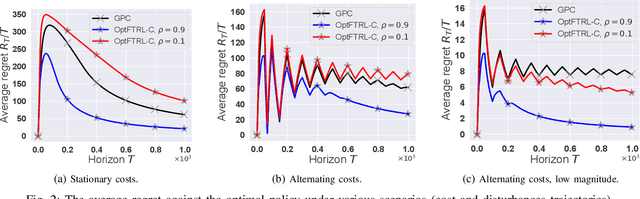
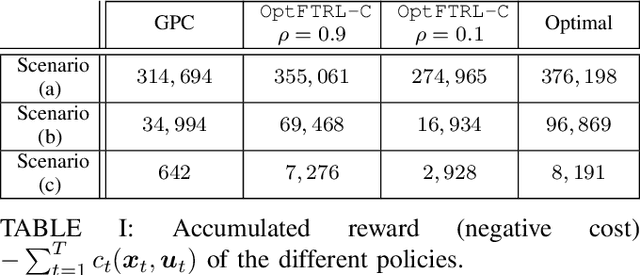
This paper brings the concept of "optimism" to the new and promising framework of online Non-stochastic Control (NSC). Namely, we study how can NSC benefit from a prediction oracle of unknown quality responsible for forecasting future costs. The posed problem is first reduced to an optimistic learning with delayed feedback problem, which is handled through the Optimistic Follow the Regularized Leader (OFTRL) algorithmic family. This reduction enables the design of OptFTRL-C, the first Disturbance Action Controller (DAC) with optimistic policy regret bounds. These new bounds are commensurate with the oracle's accuracy, ranging from $\mathcal{O}(1)$ for perfect predictions to the order-optimal $\mathcal{O}(\sqrt{T})$ even when all predictions fail. By addressing the challenge of incorporating untrusted predictions into control systems, our work contributes to the advancement of the NSC framework and paves the way towards effective and robust learning-based controllers.
Fair Resource Allocation in Virtualized O-RAN Platforms
Feb 17, 2024O-RAN systems and their deployment in virtualized general-purpose computing platforms (O-Cloud) constitute a paradigm shift expected to bring unprecedented performance gains. However, these architectures raise new implementation challenges and threaten to worsen the already-high energy consumption of mobile networks. This paper presents first a series of experiments which assess the O-Cloud's energy costs and their dependency on the servers' hardware, capacity and data traffic properties which, typically, change over time. Next, it proposes a compute policy for assigning the base station data loads to O-Cloud servers in an energy-efficient fashion; and a radio policy that determines at near-real-time the minimum transmission block size for each user so as to avoid unnecessary energy costs. The policies balance energy savings with performance, and ensure that both of them are dispersed fairly across the servers and users, respectively. To cater for the unknown and time-varying parameters affecting the policies, we develop a novel online learning framework with fairness guarantees that apply to the entire operation horizon of the system (long-term fairness). The policies are evaluated using trace-driven simulations and are fully implemented in an O-RAN compatible system where we measure the energy costs and throughput in realistic scenarios.
Adaptive Online Non-stochastic Control
Oct 02, 2023We tackle the problem of Non-stochastic Control with the aim of obtaining algorithms that adapt to the controlled environment. Namely, we tailor the FTRL framework to dynamical systems where the existence of a state, or equivalently a memory, couples the effect of the online decisions. By designing novel regularization techniques that take the system's memory into consideration, we obtain controllers with new sub-linear data adaptive policy regret bounds. Furthermore, we append these regularizers with untrusted predictions of future costs, which enables the design of the first Optimistic FTRL-based controller whose regret bound is adaptive to the accuracy of the predictions, shrinking when they are accurate while staying sub-linear even when they all fail.
Adaptive Resource Allocation for Virtualized Base Stations in O-RAN with Online Learning
Sep 04, 2023Open Radio Access Network systems, with their virtualized base stations (vBSs), offer operators the benefits of increased flexibility, reduced costs, vendor diversity, and interoperability. Optimizing the allocation of resources in a vBS is challenging since it requires knowledge of the environment, (i.e., "external'' information), such as traffic demands and channel quality, which is difficult to acquire precisely over short intervals of a few seconds. To tackle this problem, we propose an online learning algorithm that balances the effective throughput and vBS energy consumption, even under unforeseeable and "challenging'' environments; for instance, non-stationary or adversarial traffic demands. We also develop a meta-learning scheme, which leverages the power of other algorithmic approaches, tailored for more "easy'' environments, and dynamically chooses the best performing one, thus enhancing the overall system's versatility and effectiveness. We prove the proposed solutions achieve sub-linear regret, providing zero average optimality gap even in challenging environments. The performance of the algorithms is evaluated with real-world data and various trace-driven evaluations, indicating savings of up to 64.5% in the power consumption of a vBS compared with state-of-the-art benchmarks.