 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEArch: Optimistic Policy Selection Between Scene Noise and Drift for UAV Radar Search
May 31, 2026Unmanned Aerial Vehicles (UAVs) equipped with radar sensors are deployed for target search missions in diverse environments, where targets exhibit characteristic signatures (e.g., respiration micro-motion in human search) detectable through occlusions. A fundamental challenge arises from shifts in radar statistics as the UAV moves through a dynamic and potentially non-stationary environment, rendering any fixed signal-processing strategy suboptimal; yet perception and adaptation must run onboard a resource-constrained aerial node in real time. Since no single detector performs well across all conditions, we adopt a multi-policy paradigm and formulate UAV target search as an online policy selection problem over a library of specialized detectors, with performance measured by regret, the cumulative loss gap relative to the best policy in each scene. The setting couples in-scene stochastic noise with inter-scene shifts. Whereas prior methods capture only one regime, we account for both through the Stochastically Extended Adversary (SEA) framework, without requiring oracle knowledge of scene dynamics. Because adaptation must run at the UAV, we instantiate SEA through \textsc{SEArch}, a lightweight optimistic Follow the Regularized Leader (OFTRL) selector with an adaptive learning rate, achieving regret $O(\barσ_T \sqrt{T} + \sqrt{J})$, where $\barσ_T$ captures radar measurement noise and $J$ is the number of scene transitions over the mission horizon $T$. To enable rapid adaptation under frequent scene changes, we further introduce \textsc{W-SEArch}, a windowed variant that restarts every $w$ rounds and achieves regret $O(\barσ_I \sqrt{w})$ under at most one transition per window. Experiments show up to 30\% regret reduction compared to non-adaptive baselines across a range of non-stationary settings.
Partially Lazy Gradient Descent for Smoothed Online Learning
Jan 22, 2026We introduce $k$-lazyGD, an online learning algorithm that bridges the gap between greedy Online Gradient Descent (OGD, for $k=1$) and lazy GD/dual-averaging (for $k=T$), creating a spectrum between reactive and stable updates. We analyze this spectrum in Smoothed Online Convex Optimization (SOCO), where the learner incurs both hitting and movement costs. Our main contribution is establishing that laziness is possible without sacrificing hitting performance: we prove that $k$-lazyGD achieves the optimal dynamic regret $\mathcal{O}(\sqrt{(P_T+1)T})$ for any laziness slack $k$ up to $Θ(\sqrt{T/P_T})$, where $P_T$ is the comparator path length. This result formally connects the allowable laziness to the comparator's shifts, showing that $k$-lazyGD can retain the inherently small movements of lazy methods without compromising tracking ability. We base our analysis on the Follow the Regularized Leader (FTRL) framework, and derive a matching lower bound. Since the slack depends on $P_T$, an ensemble of learners with various slacks is used, yielding a method that is provably stable when it can be, and agile when it must be.
On the Dynamic Regret of Following the Regularized Leader: Optimism with History Pruning
May 28, 2025We revisit the Follow the Regularized Leader (FTRL) framework for Online Convex Optimization (OCO) over compact sets, focusing on achieving dynamic regret guarantees. Prior work has highlighted the framework's limitations in dynamic environments due to its tendency to produce "lazy" iterates. However, building on insights showing FTRL's ability to produce "agile" iterates, we show that it can indeed recover known dynamic regret bounds through optimistic composition of future costs and careful linearization of past costs, which can lead to pruning some of them. This new analysis of FTRL against dynamic comparators yields a principled way to interpolate between greedy and agile updates and offers several benefits, including refined control over regret terms, optimism without cyclic dependence, and the application of minimal recursive regularization akin to AdaFTRL. More broadly, we show that it is not the lazy projection style of FTRL that hinders (optimistic) dynamic regret, but the decoupling of the algorithm's state (linearized history) from its iterates, allowing the state to grow arbitrarily. Instead, pruning synchronizes these two when necessary.
Optimistic Learning for Communication Networks
Apr 04, 2025AI/ML-based tools are at the forefront of resource management solutions for communication networks. Deep learning, in particular, is highly effective in facilitating fast and high-performing decision-making whenever representative training data is available to build offline accurate models. Conversely, online learning solutions do not require training and enable adaptive decisions based on runtime observations, alas are often overly conservative. This extensive tutorial proposes the use of optimistic learning (OpL) as a decision engine for resource management frameworks in modern communication systems. When properly designed, such solutions can achieve fast and high-performing decisions -- comparable to offline-trained models -- while preserving the robustness and performance guarantees of the respective online learning approaches. We introduce the fundamental concepts, algorithms and results of OpL, discuss the roots of this theory and present different approaches to defining and achieving optimism. We proceed to showcase how OpL can enhance resource management in communication networks for several key problems such as caching, edge computing, network slicing, and workload assignment in decentralized O-RAN platforms. Finally, we discuss the open challenges that must be addressed to unlock the full potential of this new resource management approach.
Optimistic Online Non-stochastic Control via FTRL
Apr 04, 2024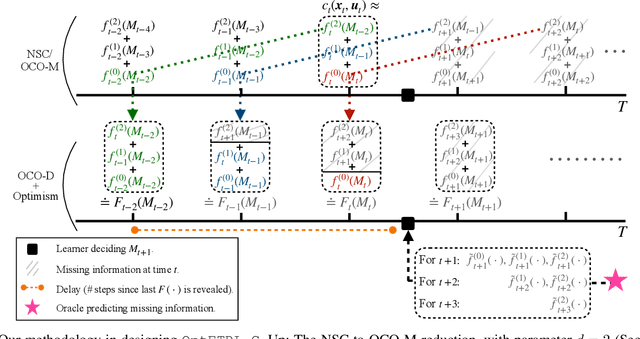
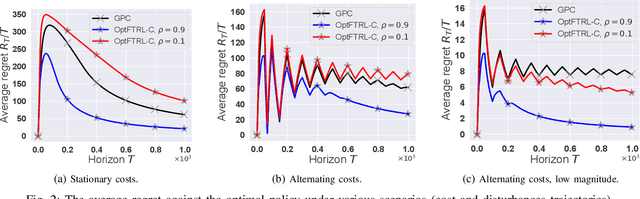
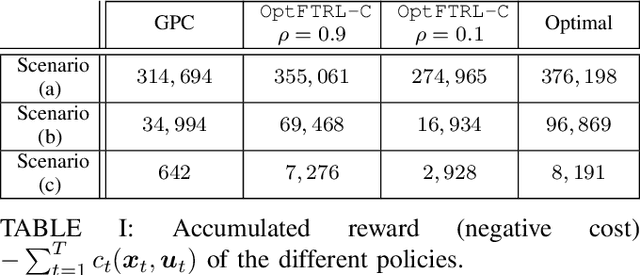
This paper brings the concept of "optimism" to the new and promising framework of online Non-stochastic Control (NSC). Namely, we study how can NSC benefit from a prediction oracle of unknown quality responsible for forecasting future costs. The posed problem is first reduced to an optimistic learning with delayed feedback problem, which is handled through the Optimistic Follow the Regularized Leader (OFTRL) algorithmic family. This reduction enables the design of OptFTRL-C, the first Disturbance Action Controller (DAC) with optimistic policy regret bounds. These new bounds are commensurate with the oracle's accuracy, ranging from $\mathcal{O}(1)$ for perfect predictions to the order-optimal $\mathcal{O}(\sqrt{T})$ even when all predictions fail. By addressing the challenge of incorporating untrusted predictions into control systems, our work contributes to the advancement of the NSC framework and paves the way towards effective and robust learning-based controllers.
Adaptive Online Non-stochastic Control
Oct 02, 2023We tackle the problem of Non-stochastic Control with the aim of obtaining algorithms that adapt to the controlled environment. Namely, we tailor the FTRL framework to dynamical systems where the existence of a state, or equivalently a memory, couples the effect of the online decisions. By designing novel regularization techniques that take the system's memory into consideration, we obtain controllers with new sub-linear data adaptive policy regret bounds. Furthermore, we append these regularizers with untrusted predictions of future costs, which enables the design of the first Optimistic FTRL-based controller whose regret bound is adaptive to the accuracy of the predictions, shrinking when they are accurate while staying sub-linear even when they all fail.
Optimistic No-regret Algorithms for Discrete Caching
Aug 15, 2022
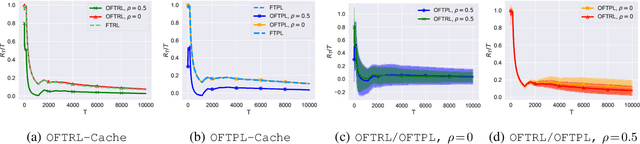

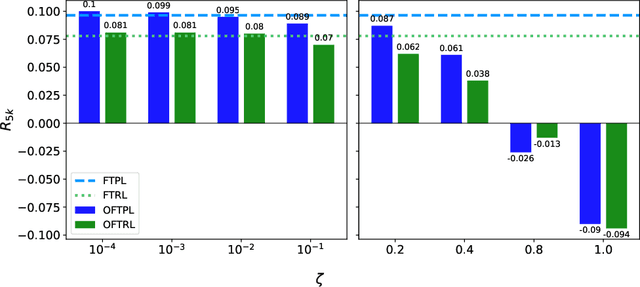
We take a systematic look at the problem of storing whole files in a cache with limited capacity in the context of optimistic learning, where the caching policy has access to a prediction oracle (provided by, e.g., a Neural Network). The successive file requests are assumed to be generated by an adversary, and no assumption is made on the accuracy of the oracle. In this setting, we provide a universal lower bound for prediction-assisted online caching and proceed to design a suite of policies with a range of performance-complexity trade-offs. All proposed policies offer sublinear regret bounds commensurate with the accuracy of the oracle. Our results substantially improve upon all recently-proposed online caching policies, which, being unable to exploit the oracle predictions, offer only $O(\sqrt{T})$ regret. In this pursuit, we design, to the best of our knowledge, the first comprehensive optimistic Follow-the-Perturbed leader policy, which generalizes beyond the caching problem. We also study the problem of caching files with different sizes and the bipartite network caching problem. Finally, we evaluate the efficacy of the proposed policies through extensive numerical experiments using real-world traces.
Online Caching with no Regret: Optimistic Learning via Recommendations
Apr 20, 2022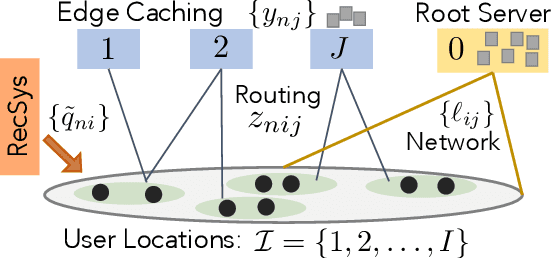
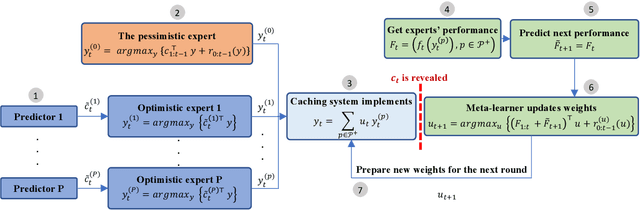
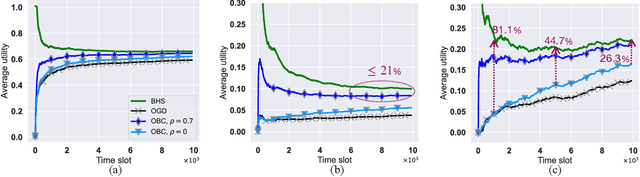
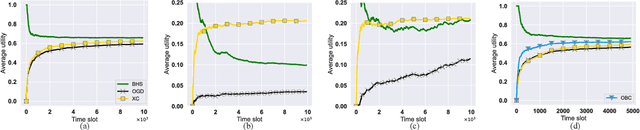
The design of effective online caching policies is an increasingly important problem for content distribution networks, online social networks and edge computing services, among other areas. This paper proposes a new algorithmic toolbox for tackling this problem through the lens of optimistic online learning. We build upon the Follow-the-Regularized-Leader (FTRL) framework, which is developed further here to include predictions for the file requests, and we design online caching algorithms for bipartite networks with fixed-size caches or elastic leased caches subject to time-average budget constraints. The predictions are provided by a content recommendation system that influences the users viewing activity and hence can naturally reduce the caching network's uncertainty about future requests. We also extend the framework to learn and utilize the best request predictor in cases where many are available. We prove that the proposed {optimistic} learning caching policies can achieve sub-zero performance loss (regret) for perfect predictions, and maintain the sub-linear regret bound $O(\sqrt T)$, which is the best achievable bound for policies that do not use predictions, even for arbitrary-bad predictions. The performance of the proposed algorithms is evaluated with detailed trace-driven numerical tests.
Online Caching with Optimistic Learning
Feb 22, 2022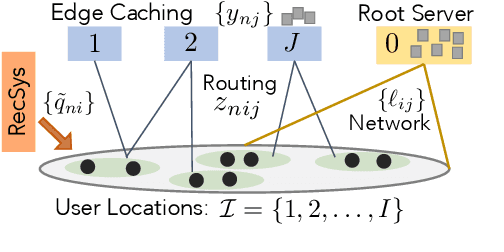
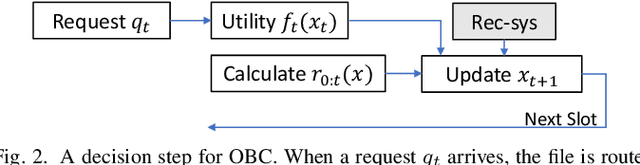
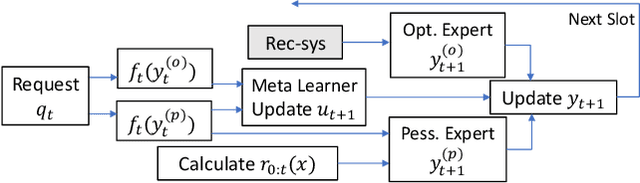
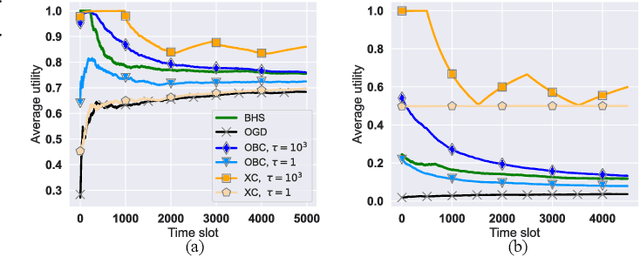
The design of effective online caching policies is an increasingly important problem for content distribution networks, online social networks and edge computing services, among other areas. This paper proposes a new algorithmic toolbox for tackling this problem through the lens of optimistic online learning. We build upon the Follow-the-Regularized-Leader (FTRL) framework which is developed further here to include predictions for the file requests, and we design online caching algorithms for bipartite networks with fixed-size caches or elastic leased caches subject to time-average budget constraints. The predictions are provided by a content recommendation system that influences the users viewing activity, and hence can naturally reduce the caching network's uncertainty about future requests. We prove that the proposed optimistic learning caching policies can achieve sub-zero performance loss (regret) for perfect predictions, and maintain the best achievable regret bound $O(\sqrt T)$ even for arbitrary-bad predictions. The performance of the proposed algorithms is evaluated with detailed trace-driven numerical tests.
Exploring Deep Reinforcement Learning-Assisted Federated Learning for Online Resource Allocation in EdgeIoT
Feb 15, 2022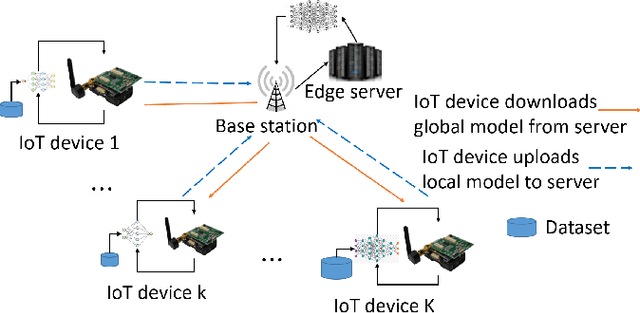
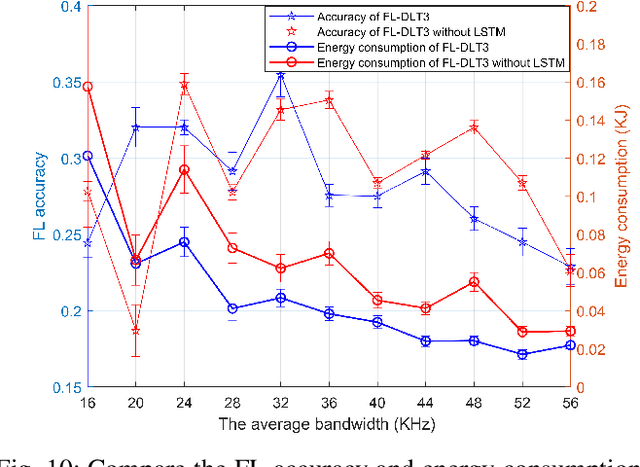
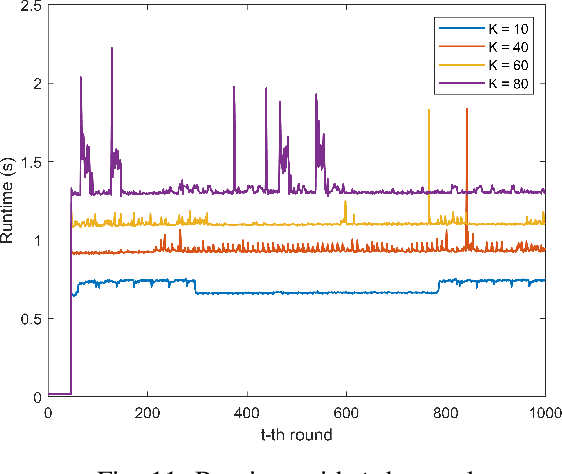
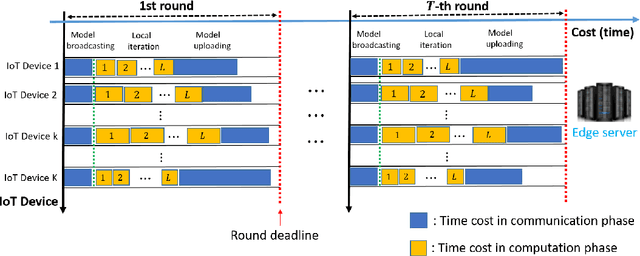
Federated learning (FL) has been increasingly considered to preserve data training privacy from eavesdropping attacks in mobile edge computing-based Internet of Thing (EdgeIoT). On the one hand, the learning accuracy of FL can be improved by selecting the IoT devices with large datasets for training, which gives rise to a higher energy consumption. On the other hand, the energy consumption can be reduced by selecting the IoT devices with small datasets for FL, resulting in a falling learning accuracy. In this paper, we formulate a new resource allocation problem for EdgeIoT to balance the learning accuracy of FL and the energy consumption of the IoT device. We propose a new federated learning-enabled twin-delayed deep deterministic policy gradient (FLDLT3) framework to achieve the optimal accuracy and energy balance in a continuous domain. Furthermore, long short term memory (LSTM) is leveraged in FL-DLT3 to predict the time-varying network state while FL-DLT3 is trained to select the IoT devices and allocate the transmit power. Numerical results demonstrate that the proposed FL-DLT3 achieves fast convergence (less than 100 iterations) while the FL accuracy-to-energy consumption ratio is improved by 51.8% compared to existing state-of-the-art benchmark.