 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Privacy Benefits of Redaction
Jan 30, 2025

We propose a novel redaction methodology that can be used to sanitize natural text data. Our new technique provides better privacy benefits than other state of the art techniques while maintaining lower redaction levels.
RLT4Rec: Reinforcement Learning Transformer for User Cold Start and Item Recommendation
Dec 10, 2024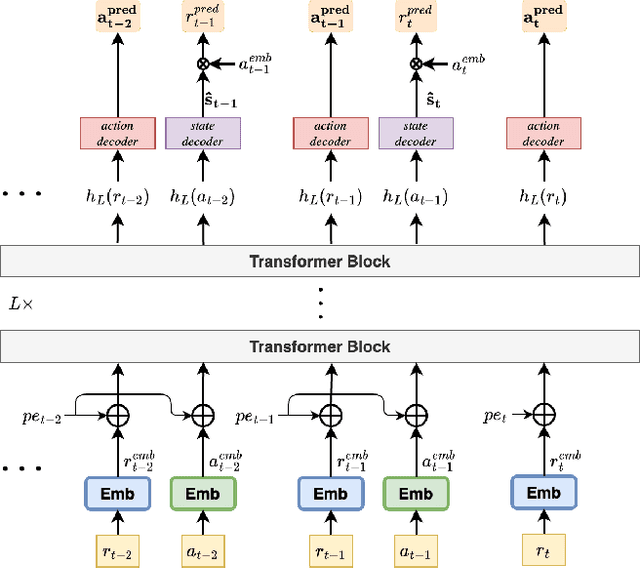



We introduce a new sequential transformer reinforcement learning architecture RLT4Rec and demonstrate that it achieves excellent performance in a range of item recommendation tasks. RLT4Rec uses a relatively simple transformer architecture that takes as input the user's (item,rating) history and outputs the next item to present to the user. Unlike existing RL approaches, there is no need to input a state observation or estimate. RLT4Rec handles new users and established users within the same consistent framework and automatically balances the "exploration" needed to discover the preferences of a new user with the "exploitation" that is more appropriate for established users. Training of RLT4Rec is robust and fast and is insensitive to the choice of training data, learning to generate "good" personalised sequences that the user tends to rate highly even when trained on "bad" data.
Towards Quantifying The Privacy Of Redacted Text
Oct 10, 2024In this paper we propose use of a k-anonymity-like approach for evaluating the privacy of redacted text. Given a piece of redacted text we use a state of the art transformer-based deep learning network to reconstruct the original text. This generates multiple full texts that are consistent with the redacted text, i.e. which are grammatical, have the same non-redacted words etc, and represents each of these using an embedding vector that captures sentence similarity. In this way we can estimate the number, diversity and quality of full text consistent with the redacted text and so evaluate privacy.
* Accepted in ECIR'23
Attack Detection Using Item Vector Shift in Matrix Factorisation Recommenders
Dec 01, 2023



This paper proposes a novel method for detecting shilling attacks in Matrix Factorization (MF)-based Recommender Systems (RS), in which attackers use false user-item feedback to promote a specific item. Unlike existing methods that use either use supervised learning to distinguish between attack and genuine profiles or analyse target item rating distributions to detect false ratings, our method uses an unsupervised technique to detect false ratings by examining shifts in item preference vectors that exploit rating deviations and user characteristics, making it a promising new direction. The experimental results demonstrate the effectiveness of our approach in various attack scenarios, including those involving obfuscation techniques.
Evaluating Impact of User-Cluster Targeted Attacks in Matrix Factorisation Recommenders
May 08, 2023
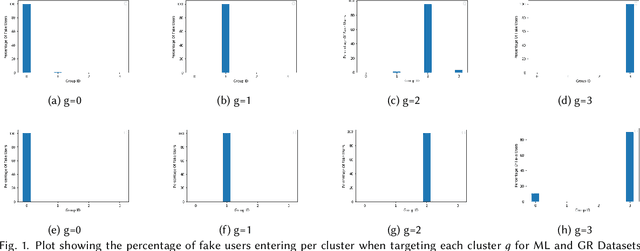


In practice, users of a Recommender System (RS) fall into a few clusters based on their preferences. In this work, we conduct a systematic study on user-cluster targeted data poisoning attacks on Matrix Factorisation (MF) based RS, where an adversary injects fake users with falsely crafted user-item feedback to promote an item to a specific user cluster. We analyse how user and item feature matrices change after data poisoning attacks and identify the factors that influence the effectiveness of the attack on these feature matrices. We demonstrate that the adversary can easily target specific user clusters with minimal effort and that some items are more susceptible to attacks than others. Our theoretical analysis has been validated by the experimental results obtained from two real-world datasets. Our observations from the study could serve as a motivating point to design a more robust RS.
Bandit Convex Optimisation Revisited: FTRL Achieves $\tilde{O}(t^{1/2})$ Regret
Feb 01, 2023We show that a kernel estimator using multiple function evaluations can be easily converted into a sampling-based bandit estimator with expectation equal to the original kernel estimate. Plugging such a bandit estimator into the standard FTRL algorithm yields a bandit convex optimisation algorithm that achieves $\tilde{O}(t^{1/2})$ regret against adversarial time-varying convex loss functions.
Two Models are Better than One: Federated Learning Is Not Private For Google GBoard Next Word Prediction
Oct 30, 2022In this paper we present new attacks against federated learning when used to train natural language text models. We illustrate the effectiveness of the attacks against the next word prediction model used in Google's GBoard app, a widely used mobile keyboard app that has been an early adopter of federated learning for production use. We demonstrate that the words a user types on their mobile handset, e.g. when sending text messages, can be recovered with high accuracy under a wide range of conditions and that counter-measures such a use of mini-batches and adding local noise are ineffective. We also show that the word order (and so the actual sentences typed) can be reconstructed with high fidelity. This raises obvious privacy concerns, particularly since GBoard is in production use.
Online Caching with no Regret: Optimistic Learning via Recommendations
Apr 20, 2022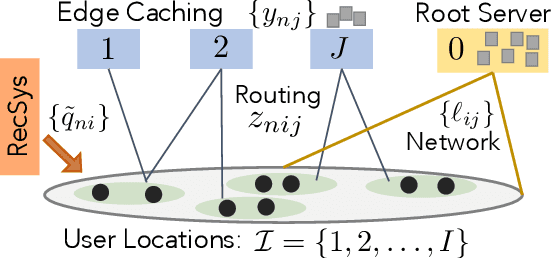
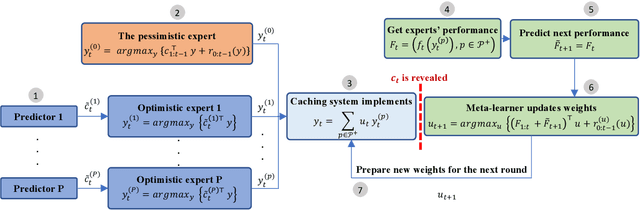
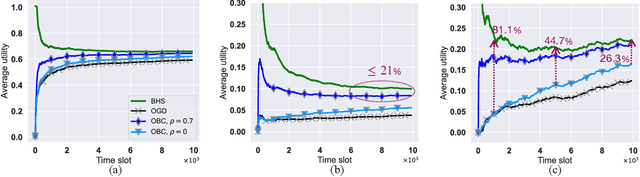
The design of effective online caching policies is an increasingly important problem for content distribution networks, online social networks and edge computing services, among other areas. This paper proposes a new algorithmic toolbox for tackling this problem through the lens of optimistic online learning. We build upon the Follow-the-Regularized-Leader (FTRL) framework, which is developed further here to include predictions for the file requests, and we design online caching algorithms for bipartite networks with fixed-size caches or elastic leased caches subject to time-average budget constraints. The predictions are provided by a content recommendation system that influences the users viewing activity and hence can naturally reduce the caching network's uncertainty about future requests. We also extend the framework to learn and utilize the best request predictor in cases where many are available. We prove that the proposed {optimistic} learning caching policies can achieve sub-zero performance loss (regret) for perfect predictions, and maintain the sub-linear regret bound $O(\sqrt T)$, which is the best achievable bound for policies that do not use predictions, even for arbitrary-bad predictions. The performance of the proposed algorithms is evaluated with detailed trace-driven numerical tests.
Online Caching with Optimistic Learning
Feb 22, 2022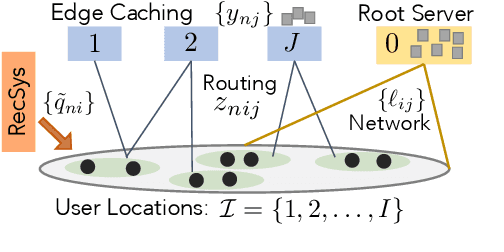
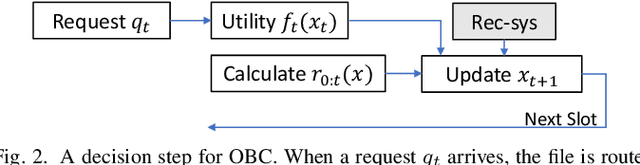
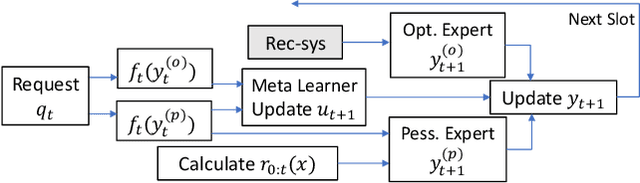
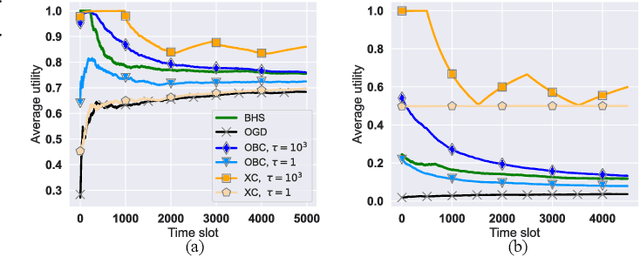
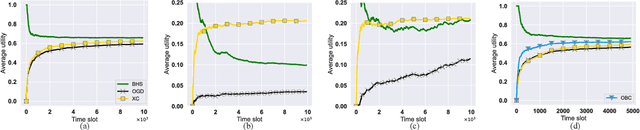
The design of effective online caching policies is an increasingly important problem for content distribution networks, online social networks and edge computing services, among other areas. This paper proposes a new algorithmic toolbox for tackling this problem through the lens of optimistic online learning. We build upon the Follow-the-Regularized-Leader (FTRL) framework which is developed further here to include predictions for the file requests, and we design online caching algorithms for bipartite networks with fixed-size caches or elastic leased caches subject to time-average budget constraints. The predictions are provided by a content recommendation system that influences the users viewing activity, and hence can naturally reduce the caching network's uncertainty about future requests. We prove that the proposed optimistic learning caching policies can achieve sub-zero performance loss (regret) for perfect predictions, and maintain the best achievable regret bound $O(\sqrt T)$ even for arbitrary-bad predictions. The performance of the proposed algorithms is evaluated with detailed trace-driven numerical tests.
Universal Algorithms: Beyond the Simplex
Apr 03, 2020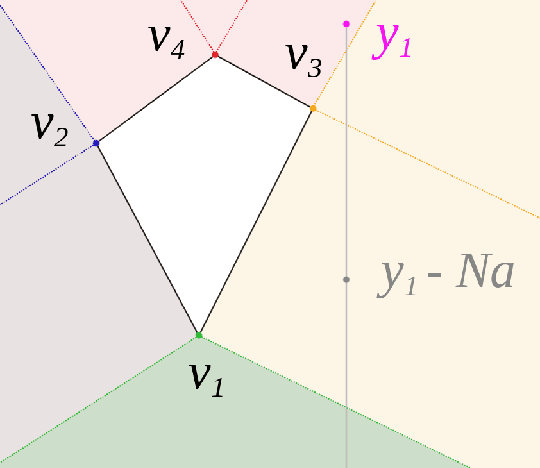
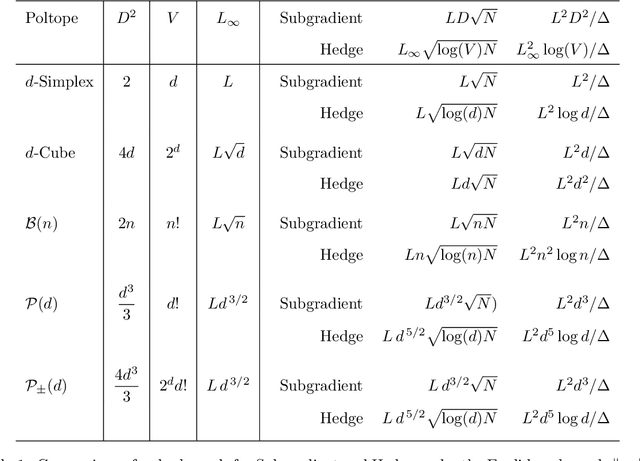
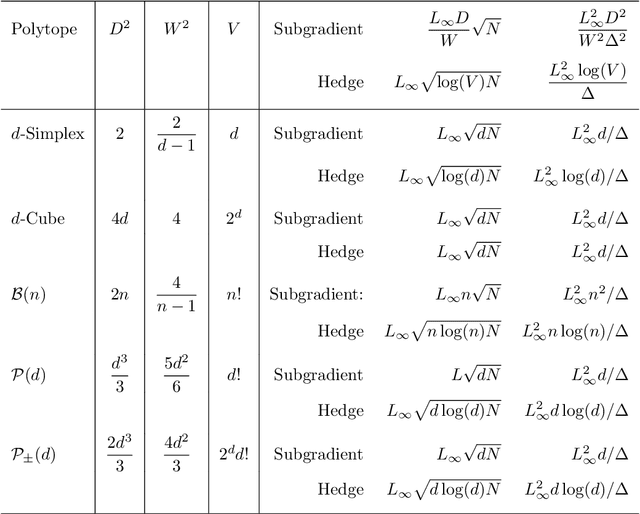
The bulk of universal algorithms in the online convex optimisation literature are variants of the Hedge (exponential weights) algorithm on the simplex. While these algorithms extend to polytope domains by assigning weights to the vertices, this process is computationally unfeasible for many important classes of polytopes where the number $V$ of vertices depends exponentially on the dimension $d$. In this paper we show the Subgradient algorithm is universal, meaning it has $O(\sqrt N)$ regret in the antagonistic setting and $O(1)$ pseudo-regret in the i.i.d setting, with two main advantages over Hedge: (1) The update step is more efficient as the action vectors have length only $d$ rather than $V$; and (2) Subgradient gives better performance if the cost vectors satisfy Euclidean rather than sup-norm bounds. This paper extends the authors' recent results for Subgradient on the simplex. We also prove the same $O(\sqrt N)$ and $O(1)$ bounds when the domain is the unit ball. To the authors' knowledge this is the first instance of these bounds on a domain other than a polytope.