 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonte Carlo Tree Search with Spectral Expansion for Planning with Dynamical Systems
Dec 15, 2024The ability of a robot to plan complex behaviors with real-time computation, rather than adhering to predesigned or offline-learned routines, alleviates the need for specialized algorithms or training for each problem instance. Monte Carlo Tree Search is a powerful planning algorithm that strategically explores simulated future possibilities, but it requires a discrete problem representation that is irreconcilable with the continuous dynamics of the physical world. We present Spectral Expansion Tree Search (SETS), a real-time, tree-based planner that uses the spectrum of the locally linearized system to construct a low-complexity and approximately equivalent discrete representation of the continuous world. We prove SETS converges to a bound of the globally optimal solution for continuous, deterministic and differentiable Markov Decision Processes, a broad class of problems that includes underactuated nonlinear dynamics, non-convex reward functions, and unstructured environments. We experimentally validate SETS on drone, spacecraft, and ground vehicle robots and one numerical experiment, each of which is not directly solvable with existing methods. We successfully show SETS automatically discovers a diverse set of optimal behaviors and motion trajectories in real time.
* The first two authors contributed equally to this article
Joint-Space Multi-Robot Motion Planning with Learned Decentralized Heuristics
Nov 21, 2023In this paper, we present a method of multi-robot motion planning by biasing centralized, sampling-based tree search with decentralized, data-driven steer and distance heuristics. Over a range of robot and obstacle densities, we evaluate the plain Rapidly-expanding Random Trees (RRT), and variants of our method for double integrator dynamics. We show that whereas plain RRT fails in every instance to plan for $4$ robots, our method can plan for up to 16 robots, corresponding to searching through a very large 65-dimensional space, which validates the effectiveness of data-driven heuristics at combating exponential search space growth. We also find that the heuristic information is complementary; using both heuristics produces search trees with lower failure rates, nodes, and path costs when compared to using each in isolation. These results illustrate the effective decomposition of high-dimensional joint-space motion planning problems into local problems.
Neural Tree Expansion for Multi-Robot Planning in Non-Cooperative Environments
Apr 20, 2021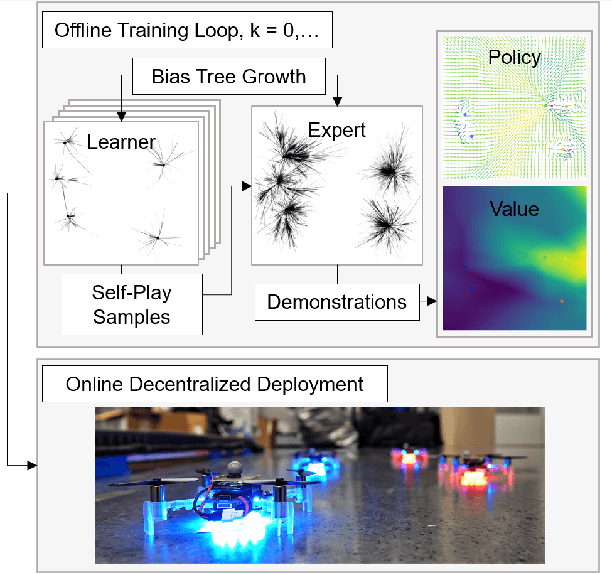
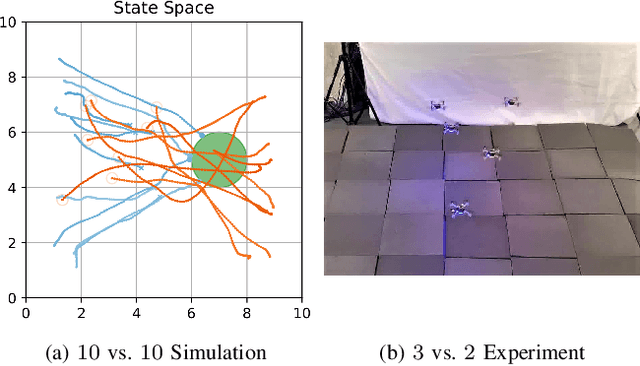
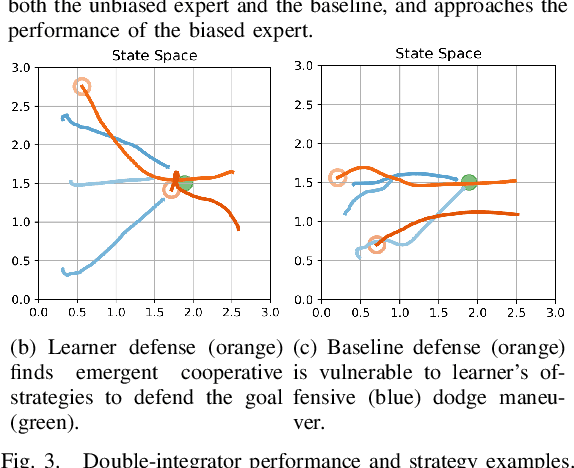
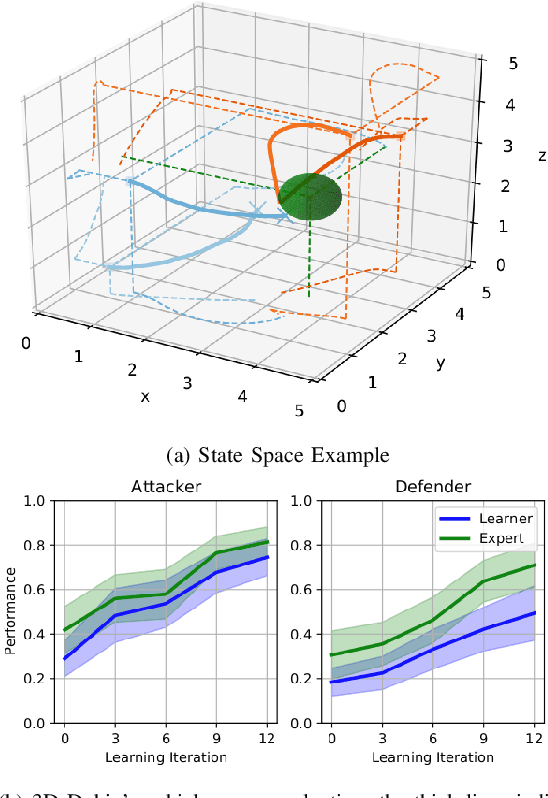
We present a self-improving, neural tree expansion method for multi-robot online planning in non-cooperative environments, where each robot tries to maximize its cumulative reward while interacting with other self-interested robots. Our algorithm adapts the centralized, perfect information, discrete-action space method from Alpha Zero to a decentralized, partial information, continuous action space setting for multi-robot applications. Our method has three interacting components: (i) a centralized, perfect-information `expert' Monte Carlo Tree Search (MCTS) with large computation resources that provides expert demonstrations, (ii) a decentralized, partial-information `learner' MCTS with small computation resources that runs in real-time and provides self-play examples, and (iii) policy & value neural networks that are trained with the expert demonstrations and bias both the expert and the learner tree growth. Our numerical experiments demonstrate neural expansion generates compact search trees with better solution quality and 20 times less computational expense compared to MCTS without neural expansion. The resulting policies are dynamically sophisticated, demonstrate coordination between robots, and play the Reach-Target-Avoid differential game significantly better than the state-of-the-art control-theoretic baseline for multi-robot, double-integrator systems. Our hardware experiments on an aerial swarm demonstrate the computational advantage of neural tree expansion, enabling online planning at 20Hz with effective policies in complex scenarios.