 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiDb-A*: Iterative Search and Optimization for Optimal Kinodynamic Motion Planning
Nov 06, 2023



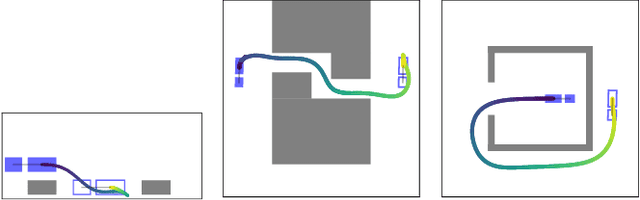
Motion planning for robotic systems with complex dynamics is a challenging problem. While recent sampling-based algorithms achieve asymptotic optimality by propagating random control inputs, their empirical convergence rate is often poor, especially in high-dimensional systems such as multirotors. An alternative approach is to first plan with a simplified geometric model and then use trajectory optimization to follow the reference path while accounting for the true dynamics. However, this approach may fail to produce a valid trajectory if the initial guess is not close to a dynamically feasible trajectory. In this paper, we present Iterative Discontinuity Bounded A* (iDb-A*), a novel kinodynamic motion planner that combines search and optimization iteratively. The search step utilizes a finite set of short trajectories (motion primitives) that are interconnected while allowing for a bounded discontinuity between them. The optimization step locally repairs the discontinuities with trajectory optimization. By progressively reducing the allowed discontinuity and incorporating more motion primitives, our algorithm achieves asymptotic optimality with excellent any-time performance. We provide a benchmark of 43 problems across eight different dynamical systems, including different versions of unicycles and multirotors. Compared to state-of-the-art methods, iDb-A* consistently solves more problem instances and finds lower-cost solutions more rapidly.
A Remote Sim2real Aerial Competition: Fostering Reproducibility and Solutions' Diversity in Robotics Challenges
Aug 31, 2023

Shared benchmark problems have historically been a fundamental driver of progress for scientific communities. In the context of academic conferences, competitions offer the opportunity to researchers with different origins, backgrounds, and levels of seniority to quantitatively compare their ideas. In robotics, a hot and challenging topic is sim2real-porting approaches that work well in simulation to real robot hardware. In our case, creating a hybrid competition with both simulation and real robot components was also dictated by the uncertainties around travel and logistics in the post-COVID-19 world. Hence, this article motivates and describes an aerial sim2real robot competition that ran during the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems, from the specification of the competition task, to the details of the software infrastructure supporting simulation and real-life experiments, to the approaches of the top-placed teams and the lessons learned by participants and organizers.
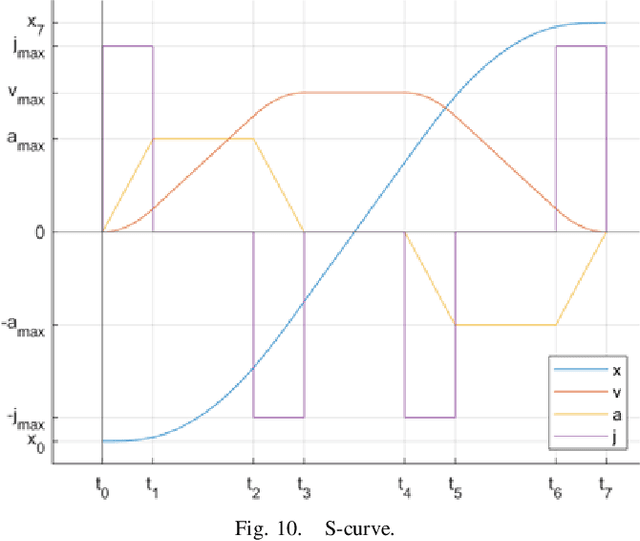
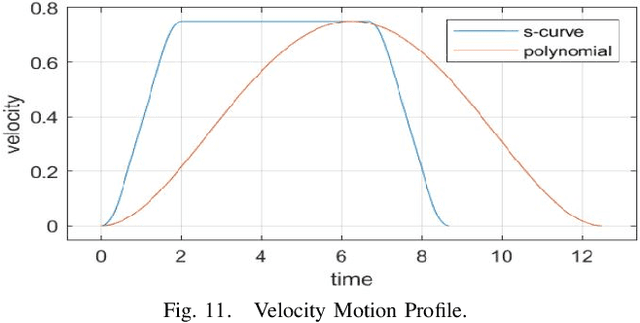
db-A*: Discontinuity-bounded Search for Kinodynamic Mobile Robot Motion Planning
Mar 21, 2022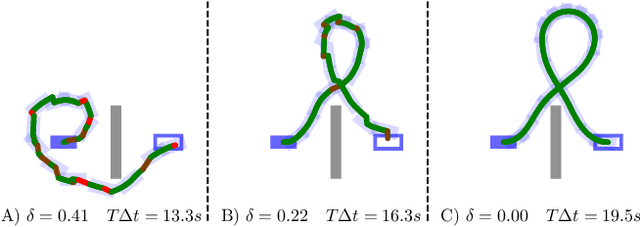
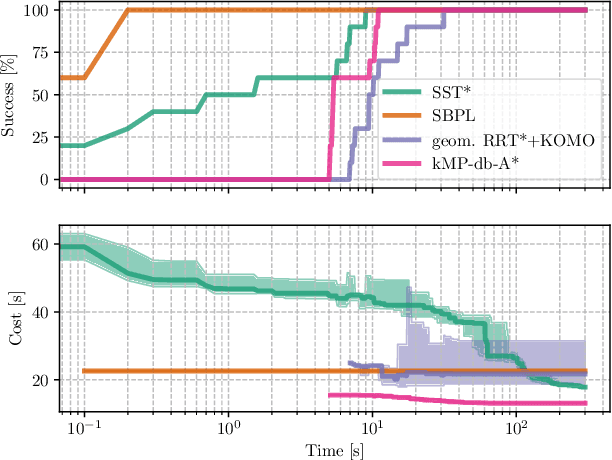
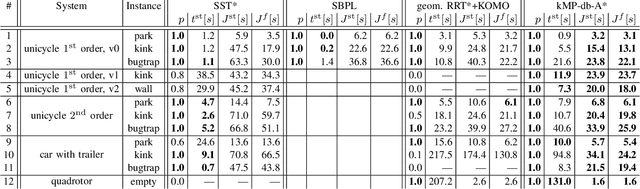
We consider time-optimal motion planning for dynamical systems that are translation-invariant, a property that holds for many mobile robots, such as differential-drives, cars, airplanes, and multirotors. Our key insight is that we can extend graph-search algorithms to the continuous case when used symbiotically with optimization. For the graph search, we introduce discontinuity-bounded A* (db-A*), a generalization of the A* algorithm that uses concepts and data structures from sampling-based planners. Db-A* reuses short trajectories, so-called motion primitives, as edges and allows a maximum user-specified discontinuity at the vertices. These trajectories are locally repaired with trajectory optimization, which also provides new improved motion primitives. Our novel kinodynamic motion planner, kMP-db-A*, has almost surely asymptotic optimal behavior and computes near-optimal solutions quickly. For our empirical validation, we provide the first benchmark that compares search-, sampling-, and optimization-based time-optimal motion planning on multiple dynamical systems in different settings. Compared to the baselines, kMP-db-A* consistently solves more problem instances, finds lower-cost initial solutions, and converges more quickly.
Neural Tree Expansion for Multi-Robot Planning in Non-Cooperative Environments
Apr 20, 2021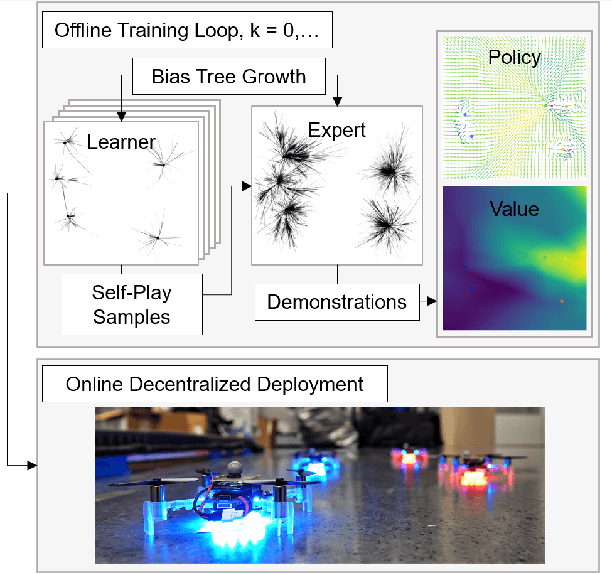
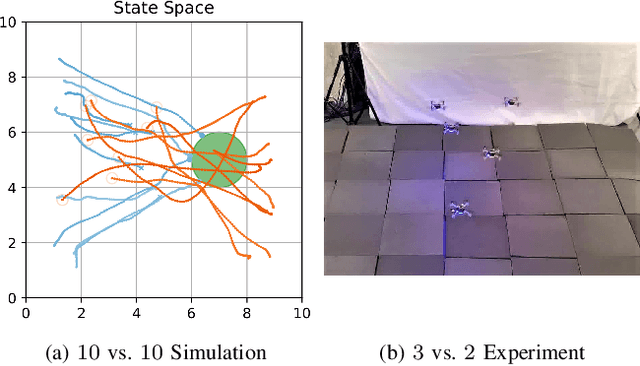
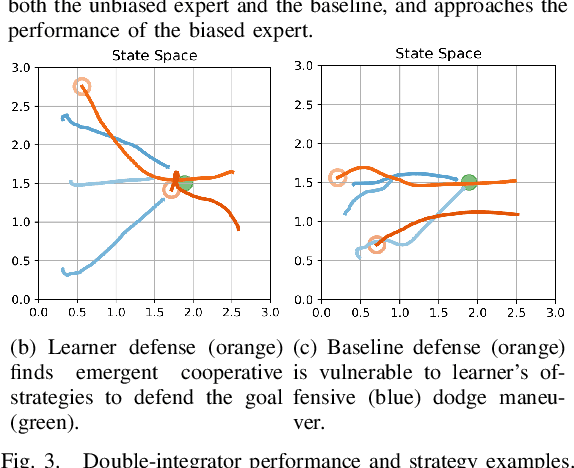
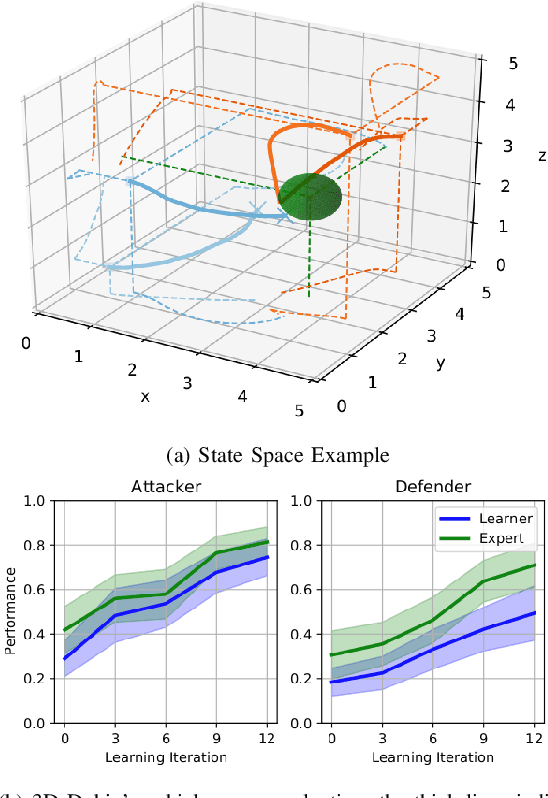
We present a self-improving, neural tree expansion method for multi-robot online planning in non-cooperative environments, where each robot tries to maximize its cumulative reward while interacting with other self-interested robots. Our algorithm adapts the centralized, perfect information, discrete-action space method from Alpha Zero to a decentralized, partial information, continuous action space setting for multi-robot applications. Our method has three interacting components: (i) a centralized, perfect-information `expert' Monte Carlo Tree Search (MCTS) with large computation resources that provides expert demonstrations, (ii) a decentralized, partial-information `learner' MCTS with small computation resources that runs in real-time and provides self-play examples, and (iii) policy & value neural networks that are trained with the expert demonstrations and bias both the expert and the learner tree growth. Our numerical experiments demonstrate neural expansion generates compact search trees with better solution quality and 20 times less computational expense compared to MCTS without neural expansion. The resulting policies are dynamically sophisticated, demonstrate coordination between robots, and play the Reach-Target-Avoid differential game significantly better than the state-of-the-art control-theoretic baseline for multi-robot, double-integrator systems. Our hardware experiments on an aerial swarm demonstrate the computational advantage of neural tree expansion, enabling online planning at 20Hz with effective policies in complex scenarios.
GLAS: Global-to-Local Safe Autonomy Synthesis for Multi-Robot Motion Planning with End-to-End Learning
Feb 26, 2020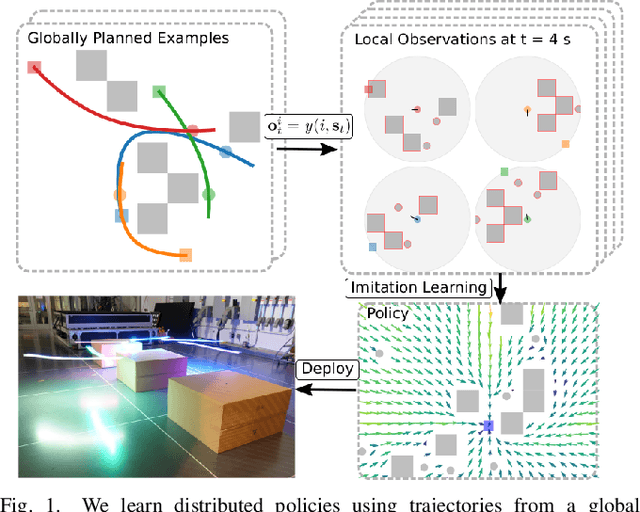

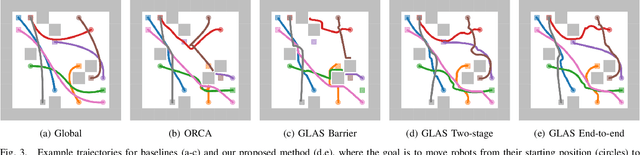
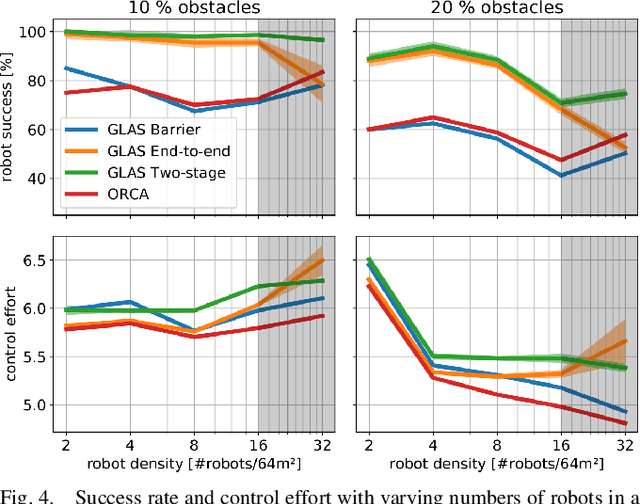
We present GLAS: Global-to-Local Autonomy Synthesis, a provably-safe, automated distributed policy generation for multi-robot motion planning. Our approach combines the advantage of centralized planning of avoiding local minima with the advantage of decentralized controllers of scalability and distributed computation. In particular, our synthesized policies only require relative state information of nearby neighbors and obstacles, and compute a provably-safe action. Our approach has three major components: i) we generate demonstration trajectories using a global planner and extract local observations from them, ii) we use deep imitation learning to learn a decentralized policy that can run efficiently online, and iii) we introduce a novel differentiable safety module to ensure collision-free operation, enabling end-to-end policy training. Our numerical experiments demonstrate that our policies have a 20% higher success rate than ORCA across a wide range of robot and obstacle densities. We demonstrate our method on an aerial swarm, executing the policy on low-end microcontrollers in real-time.
Overview: Generalizations of Multi-Agent Path Finding to Real-World Scenarios
Feb 17, 2017
Multi-agent path finding (MAPF) is well-studied in artificial intelligence, robotics, theoretical computer science and operations research. We discuss issues that arise when generalizing MAPF methods to real-world scenarios and four research directions that address them. We emphasize the importance of addressing these issues as opposed to developing faster methods for the standard formulation of the MAPF problem.