 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCART: Collision Avoidance and Robust Tracking Augmentation in Learning-based Motion Planning for Multi-Agent Systems
Jul 13, 2023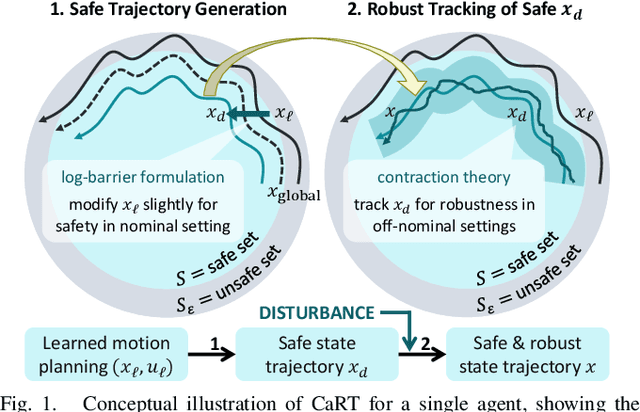
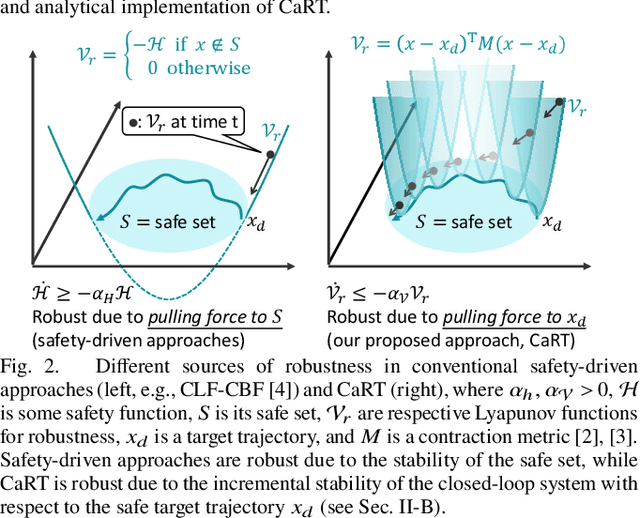
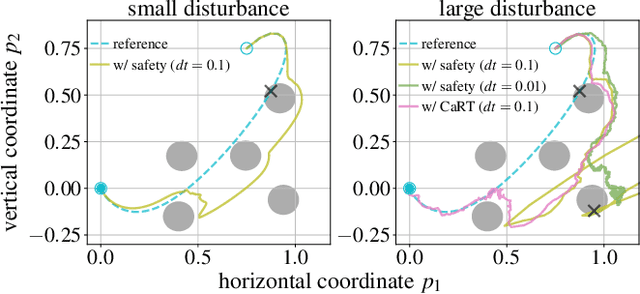

This paper presents CART, an analytical method to augment a learning-based, distributed motion planning policy of a nonlinear multi-agent system with real-time collision avoidance and robust tracking guarantees, independently of learning errors. We first derive an analytical form of an optimal safety filter for Lagrangian systems, which formally ensures a collision-free operation in a multi-agent setting in a disturbance-free environment, while allowing for its distributed implementation with minimal deviation from the learned policy. We then propose an analytical form of an optimal robust filter for Lagrangian systems to be used hierarchically with the learned collision-free target trajectory, which also enables distributed implementation and guarantees exponential boundedness of the trajectory tracking error for safety, even under the presence of deterministic and stochastic disturbance. These results are shown to extend further to general control-affine nonlinear systems using contraction theory. Our key contribution is to enhance the performance of the learned motion planning policy with collision avoidance and tracking-based robustness guarantees, independently of its original performance such as approximation errors and regret bounds in machine learning. We demonstrate the effectiveness of CART in motion planning and control of several examples of nonlinear systems, including spacecraft formation flying and rotor-failed UAV swarms.
H-TD2: Hybrid Temporal Difference Learning for Adaptive Urban Taxi Dispatch
May 05, 2021
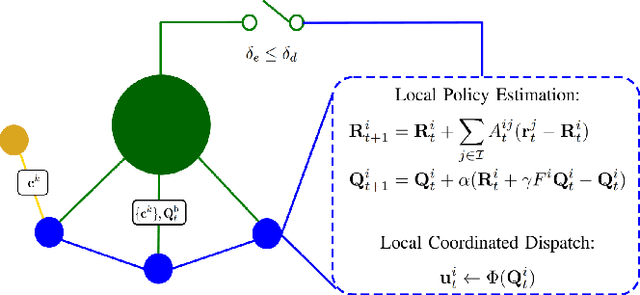
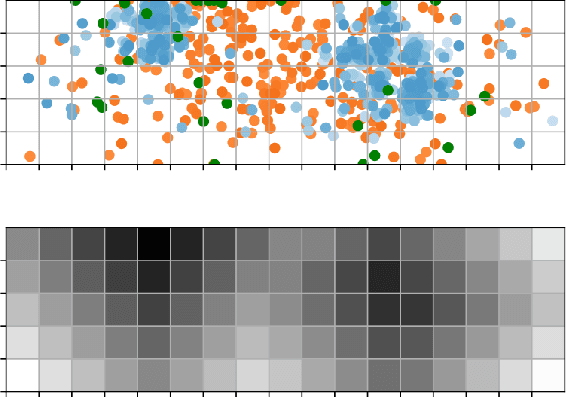
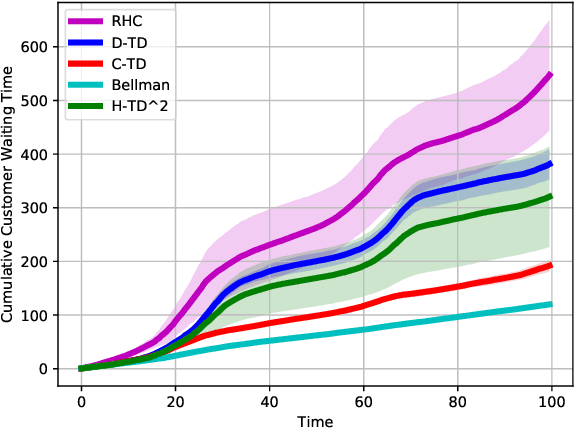
We present H-TD2: Hybrid Temporal Difference Learning for Taxi Dispatch, a model-free, adaptive decision-making algorithm to coordinate a large fleet of automated taxis in a dynamic urban environment to minimize expected customer waiting times. Our scalable algorithm exploits the natural transportation network company topology by switching between two behaviors: distributed temporal-difference learning computed locally at each taxi and infrequent centralized Bellman updates computed at the dispatch center. We derive a regret bound and design the trigger condition between the two behaviors to explicitly control the trade-off between computational complexity and the individual taxi policy's bounded sub-optimality; this advances the state of the art by enabling distributed operation with bounded-suboptimality. Additionally, unlike recent reinforcement learning dispatch methods, this policy estimation is adaptive and robust to out-of-training domain events. This result is enabled by a two-step modelling approach: the policy is learned on an agent-agnostic, cell-based Markov Decision Process and individual taxis are coordinated using the learned policy in a distributed game-theoretic task assignment. We validate our algorithm against a receding horizon control baseline in a Gridworld environment with a simulated customer dataset, where the proposed solution decreases average customer waiting time by 50% over a wide range of parameters. We also validate in a Chicago city environment with real customer requests from the Chicago taxi public dataset where the proposed solution decreases average customer waiting time by 26% over irregular customer distributions during a 2016 Major League Baseball World Series game.
GLAS: Global-to-Local Safe Autonomy Synthesis for Multi-Robot Motion Planning with End-to-End Learning
Feb 26, 2020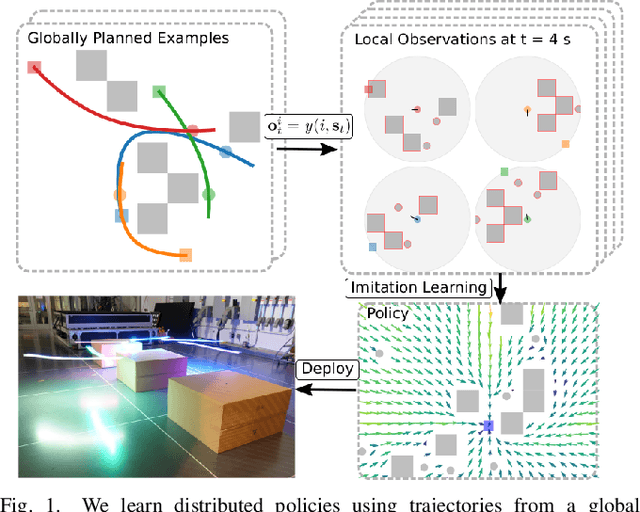

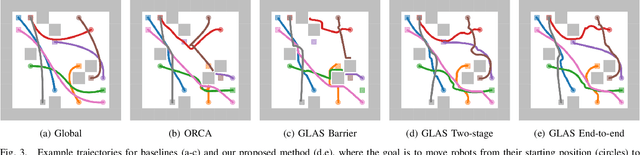
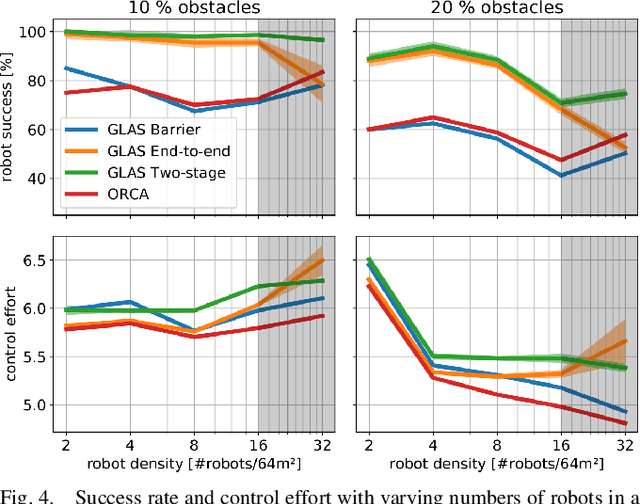
We present GLAS: Global-to-Local Autonomy Synthesis, a provably-safe, automated distributed policy generation for multi-robot motion planning. Our approach combines the advantage of centralized planning of avoiding local minima with the advantage of decentralized controllers of scalability and distributed computation. In particular, our synthesized policies only require relative state information of nearby neighbors and obstacles, and compute a provably-safe action. Our approach has three major components: i) we generate demonstration trajectories using a global planner and extract local observations from them, ii) we use deep imitation learning to learn a decentralized policy that can run efficiently online, and iii) we introduce a novel differentiable safety module to ensure collision-free operation, enabling end-to-end policy training. Our numerical experiments demonstrate that our policies have a 20% higher success rate than ORCA across a wide range of robot and obstacle densities. We demonstrate our method on an aerial swarm, executing the policy on low-end microcontrollers in real-time.