 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeH-TD2: Hybrid Temporal Difference Learning for Adaptive Urban Taxi Dispatch
Paper and Code
May 05, 2021
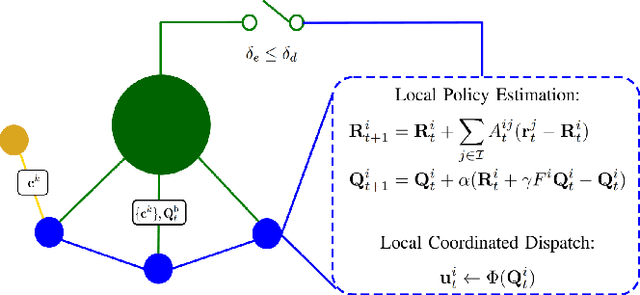
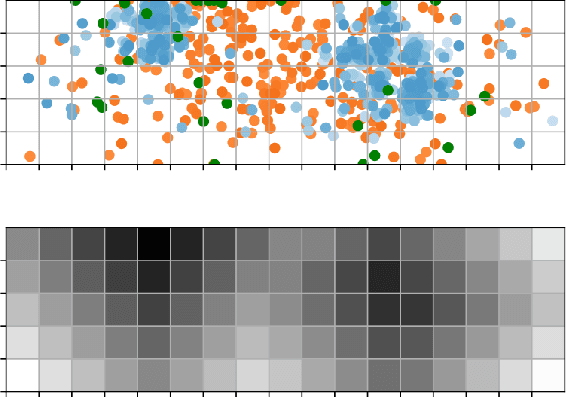
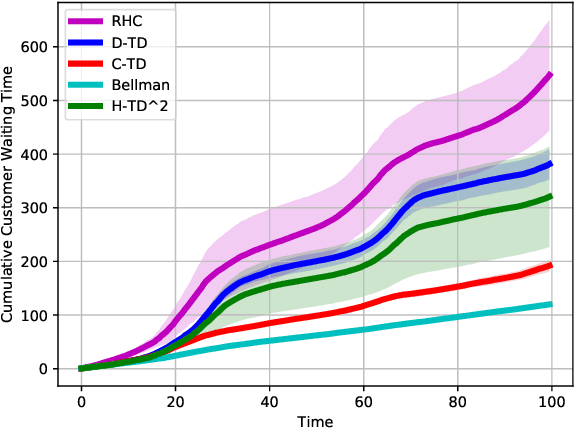
We present H-TD2: Hybrid Temporal Difference Learning for Taxi Dispatch, a model-free, adaptive decision-making algorithm to coordinate a large fleet of automated taxis in a dynamic urban environment to minimize expected customer waiting times. Our scalable algorithm exploits the natural transportation network company topology by switching between two behaviors: distributed temporal-difference learning computed locally at each taxi and infrequent centralized Bellman updates computed at the dispatch center. We derive a regret bound and design the trigger condition between the two behaviors to explicitly control the trade-off between computational complexity and the individual taxi policy's bounded sub-optimality; this advances the state of the art by enabling distributed operation with bounded-suboptimality. Additionally, unlike recent reinforcement learning dispatch methods, this policy estimation is adaptive and robust to out-of-training domain events. This result is enabled by a two-step modelling approach: the policy is learned on an agent-agnostic, cell-based Markov Decision Process and individual taxis are coordinated using the learned policy in a distributed game-theoretic task assignment. We validate our algorithm against a receding horizon control baseline in a Gridworld environment with a simulated customer dataset, where the proposed solution decreases average customer waiting time by 50% over a wide range of parameters. We also validate in a Chicago city environment with real customer requests from the Chicago taxi public dataset where the proposed solution decreases average customer waiting time by 26% over irregular customer distributions during a 2016 Major League Baseball World Series game.