 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Multimodal Multivariate Learning
Jun 14, 2022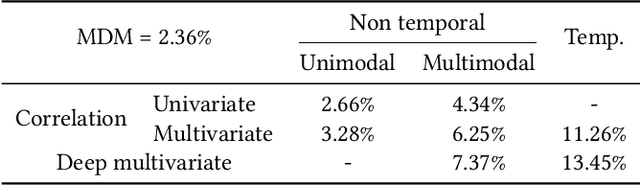
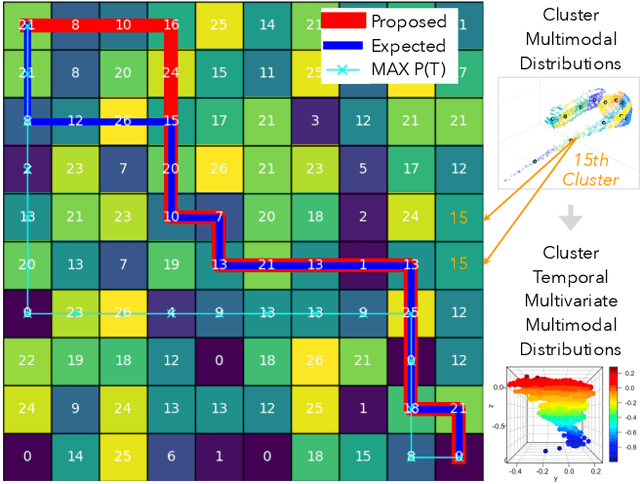
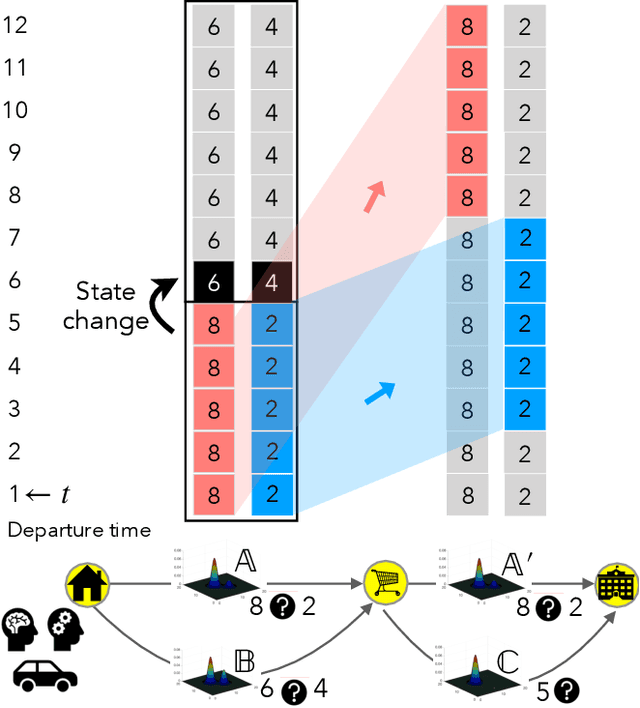
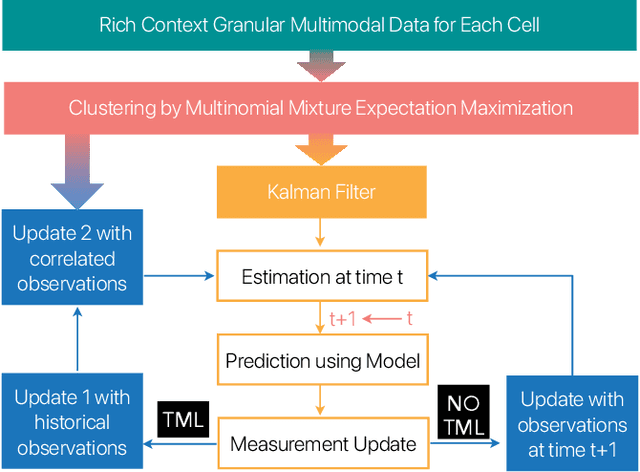
We introduce temporal multimodal multivariate learning, a new family of decision making models that can indirectly learn and transfer online information from simultaneous observations of a probability distribution with more than one peak or more than one outcome variable from one time stage to another. We approximate the posterior by sequentially removing additional uncertainties across different variables and time, based on data-physics driven correlation, to address a broader class of challenging time-dependent decision-making problems under uncertainty. Extensive experiments on real-world datasets ( i.e., urban traffic data and hurricane ensemble forecasting data) demonstrate the superior performance of the proposed targeted decision-making over the state-of-the-art baseline prediction methods across various settings.
Deep Reinforcement Learning Algorithm for Dynamic Pricing of Express Lanes with Multiple Access Locations
Sep 10, 2019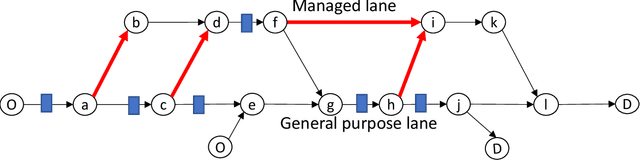
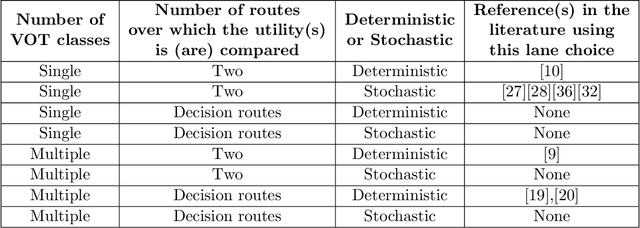
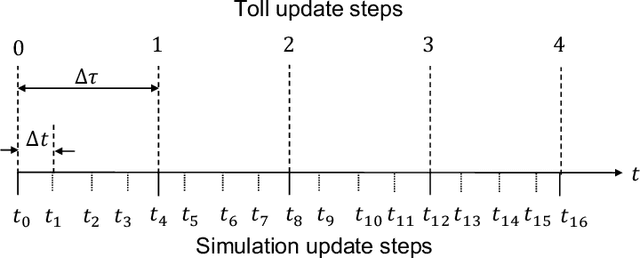
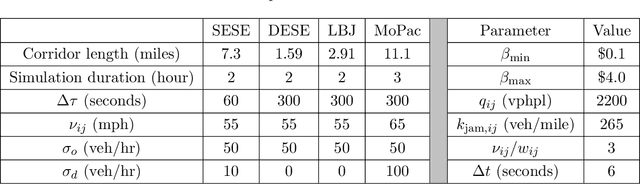
This article develops a deep reinforcement learning (Deep-RL) framework for dynamic pricing on managed lanes with multiple access locations and heterogeneity in travelers' value of time, origin, and destination. This framework relaxes assumptions in the literature by considering multiple origins and destinations, multiple access locations to the managed lane, en route diversion of travelers, partial observability of the sensor readings, and stochastic demand and observations. The problem is formulated as a partially observable Markov decision process (POMDP) and policy gradient methods are used to determine tolls as a function of real-time observations. Tolls are modeled as continuous and stochastic variables, and are determined using a feedforward neural network. The method is compared against a feedback control method used for dynamic pricing. We show that Deep-RL is effective in learning toll policies for maximizing revenue, minimizing total system travel time, and other joint weighted objectives, when tested on real-world transportation networks. The Deep-RL toll policies outperform the feedback control heuristic for the revenue maximization objective by generating revenues up to 9.5% higher than the heuristic and for the objective minimizing total system travel time (TSTT) by generating TSTT up to 10.4% lower than the heuristic. We also propose reward shaping methods for the POMDP to overcome the undesired behavior of toll policies, like the jam-and-harvest behavior of revenue-maximizing policies. Additionally, we test transferability of the algorithm trained on one set of inputs for new input distributions and offer recommendations on real-time implementations of Deep-RL algorithms. The source code for our experiments is available online at https://github.com/venktesh22/ExpressLanes_Deep-RL