 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning Based Path Planning for Improved Rover Navigation (Pre-Print Version)
Nov 11, 2020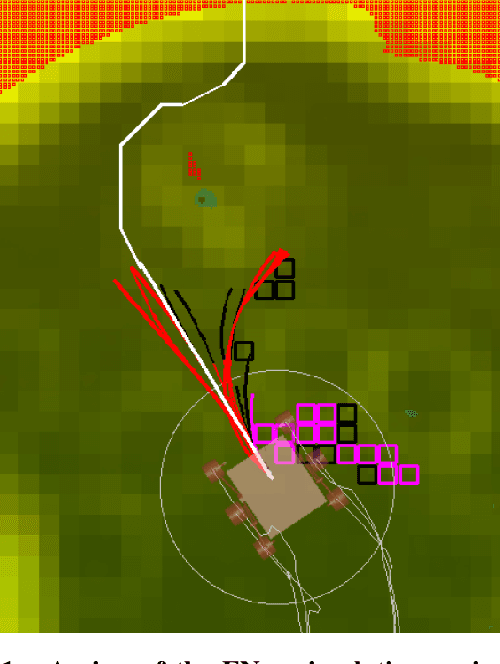
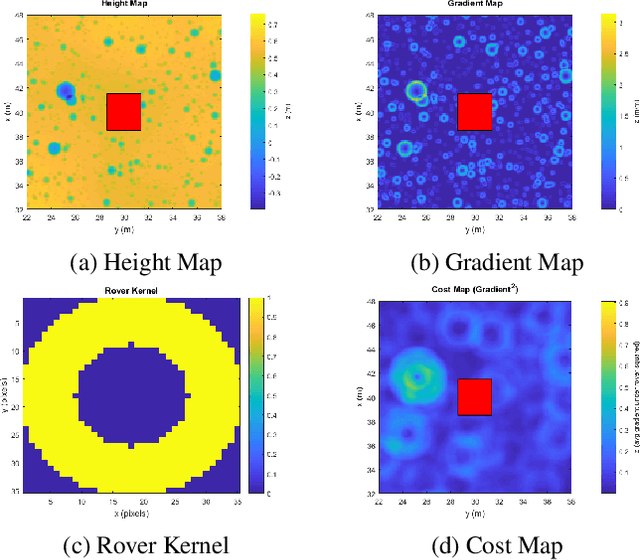

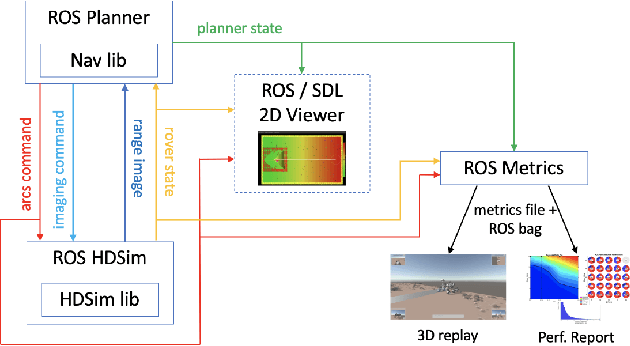
Enhanced AutoNav (ENav), the baseline surface navigation software for NASA's Perseverance rover, sorts a list of candidate paths for the rover to traverse, then uses the Approximate Clearance Evaluation (ACE) algorithm to evaluate whether the most highly ranked paths are safe. ACE is crucial for maintaining the safety of the rover, but is computationally expensive. If the most promising candidates in the list of paths are all found to be infeasible, ENav must continue to search the list and run time-consuming ACE evaluations until a feasible path is found. In this paper, we present two heuristics that, given a terrain heightmap around the rover, produce cost estimates that more effectively rank the candidate paths before ACE evaluation. The first heuristic uses Sobel operators and convolution to incorporate the cost of traversing high-gradient terrain. The second heuristic uses a machine learning (ML) model to predict areas that will be deemed untraversable by ACE. We used physics simulations to collect training data for the ML model and to run Monte Carlo trials to quantify navigation performance across a variety of terrains with various slopes and rock distributions. Compared to ENav's baseline performance, integrating the heuristics can lead to a significant reduction in ACE evaluations and average computation time per planning cycle, increase path efficiency, and maintain or improve the rate of successful traverses. This strategy of targeting specific bottlenecks with ML while maintaining the original ACE safety checks provides an example of how ML can be infused into planetary science missions and other safety-critical software.
A General Large Neighborhood Search Framework for Solving Integer Programs
Mar 29, 2020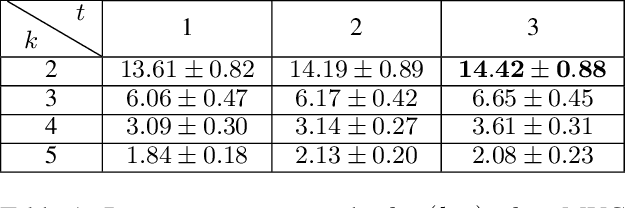
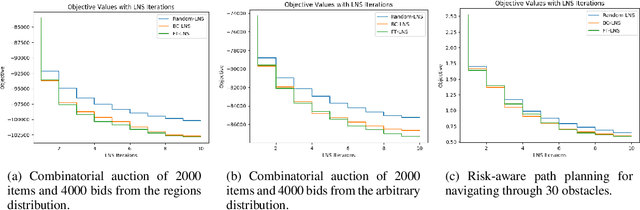
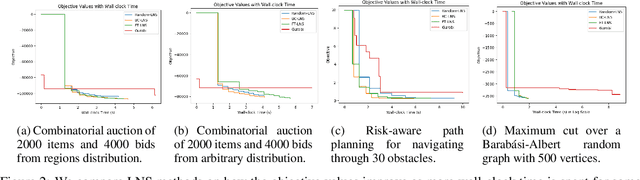

This paper studies how to design abstractions of large-scale combinatorial optimization problems that can leverage existing state-of-the-art solvers in general purpose ways, and that are amenable to data-driven design. The goal is to arrive at new approaches that can reliably outperform existing solvers in wall-clock time. We focus on solving integer programs, and ground our approach in the large neighborhood search (LNS) paradigm, which iteratively chooses a subset of variables to optimize while leaving the remainder fixed. The appeal of LNS is that it can easily use any existing solver as a subroutine, and thus can inherit the benefits of carefully engineered heuristic approaches and their software implementations. We also show that one can learn a good neighborhood selector from training data. Through an extensive empirical validation, we demonstrate that our LNS framework can significantly outperform, in wall-clock time, compared to state-of-the-art commercial solvers such as Gurobi.
Single Sample Feature Importance: An Interpretable Algorithm for Low-Level Feature Analysis
Nov 27, 2019


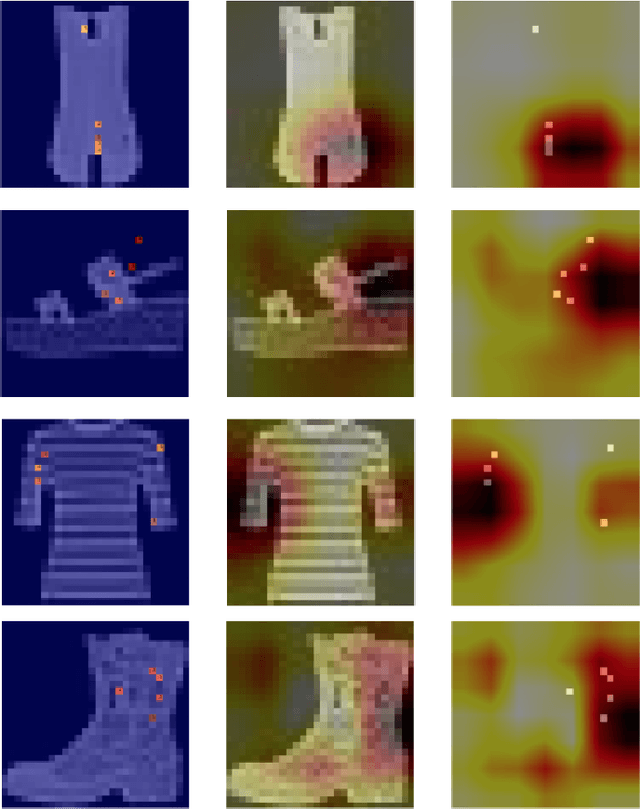
Have you ever wondered how your feature space is impacting the prediction of a specific sample in your dataset? In this paper, we introduce Single Sample Feature Importance (SSFI), which is an interpretable feature importance algorithm that allows for the identification of the most important features that contribute to the prediction of a single sample. When a dataset can be learned by a Random Forest classifier or regressor, SSFI shows how the Random Forest's prediction path can be utilized for low-level feature importance calculation. SSFI results in a relative ranking of features, highlighting those with the greatest impact on a data point's prediction. We demonstrate these results both numerically and visually on four different datasets.
Co-training for Policy Learning
Jul 03, 2019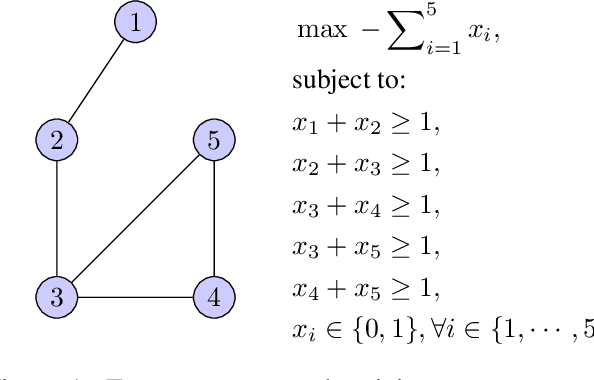
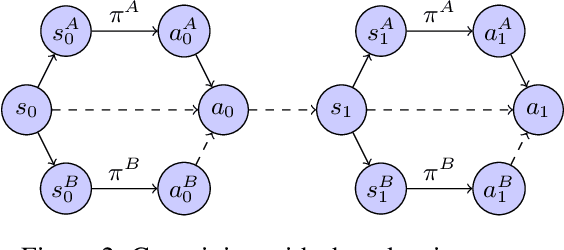
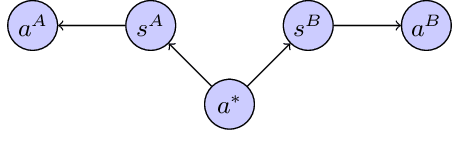
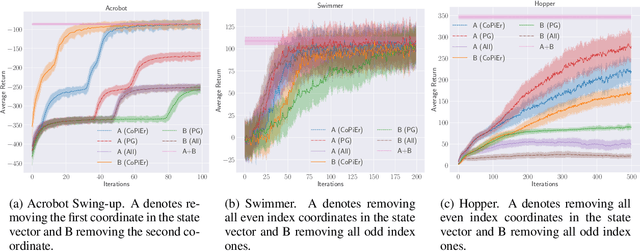
We study the problem of learning sequential decision-making policies in settings with multiple state-action representations. Such settings naturally arise in many domains, such as planning (e.g., multiple integer programming formulations) and various combinatorial optimization problems (e.g., those with both integer programming and graph-based formulations). Inspired by the classical co-training framework for classification, we study the problem of co-training for policy learning. We present sufficient conditions under which learning from two views can improve upon learning from a single view alone. Motivated by these theoretical insights, we present a meta-algorithm for co-training for sequential decision making. Our framework is compatible with both reinforcement learning and imitation learning. We validate the effectiveness of our approach across a wide range of tasks, including discrete/continuous control and combinatorial optimization.
Learning to Search via Retrospective Imitation
Oct 05, 2018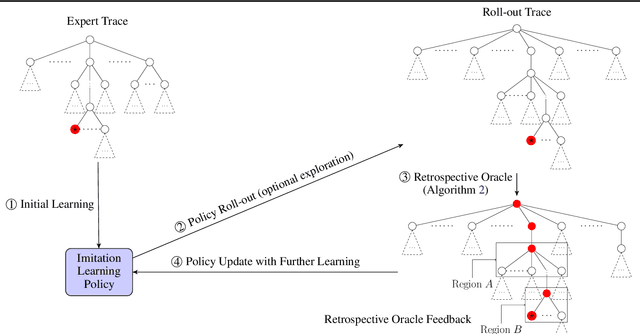
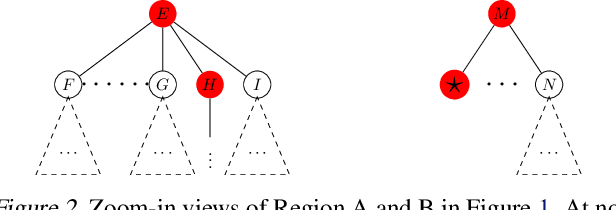
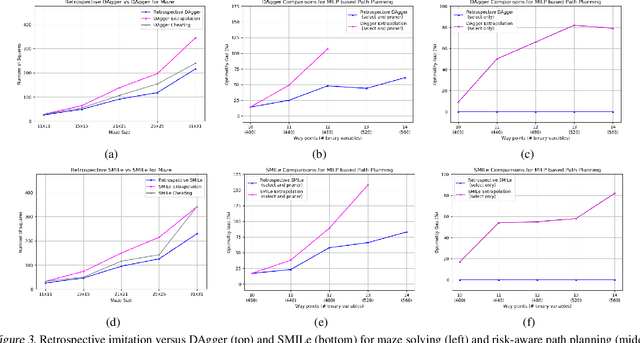

We study the problem of learning a good search policy from demonstrations for combinatorial search spaces. We propose retrospective imitation learning, which, after initial training by an expert, improves itself by learning from its own retrospective solutions. That is, when the policy eventually reaches a feasible solution in a search tree after making mistakes and backtracks, it retrospectively constructs an improved search trace to the solution by removing backtracks, which is then used to further train the policy. A key feature of our approach is that it can iteratively scale up, or transfer, to larger problem sizes than the initial expert demonstrations, thus dramatically expanding its applicability beyond that of conventional imitation learning. We showcase the effectiveness of our approach on two tasks: synthetic maze solving, and integer program based risk-aware path planning.
PURE: Scalable Phase Unwrapping with Spatial Redundant Arcs
May 03, 2018
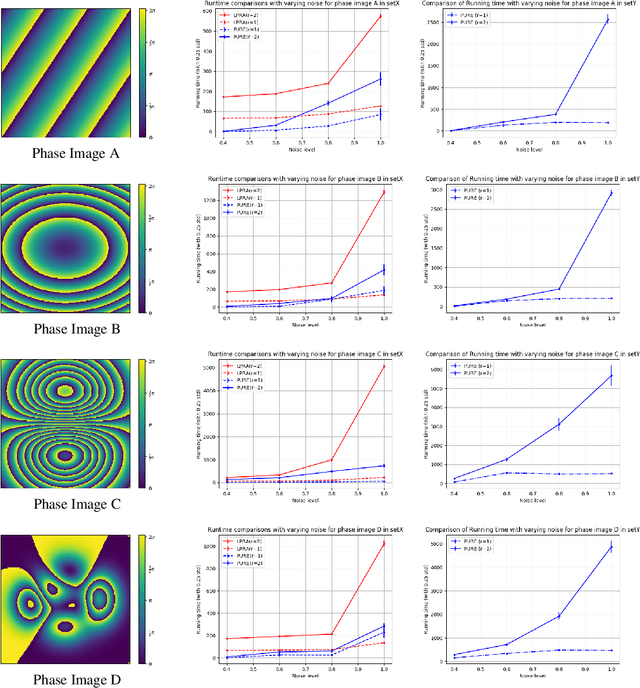

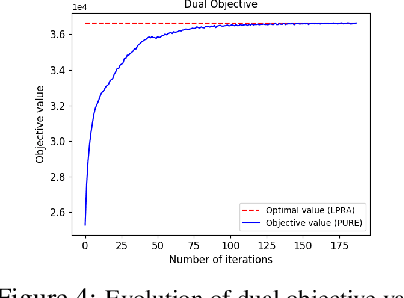
Phase unwrapping is a key problem in many coherent imaging systems, such as synthetic aperture radar (SAR) interferometry. A general formulation for redundant integration of finite differences for phase unwrapping (Costantini et al., 2010) was shown to produce a more reliable solution by exploiting redundant differential estimates. However, this technique requires a commercial linear programming solver for large-scale problems. For a linear cost function, we propose a method based on Dual Decomposition that breaks the given problem defined over a non-planar graph into tractable sub-problems over planar subgraphs. We also propose a decomposition technique that exploits the underlying graph structure for solving the sub-problems efficiently and guarantees asymptotic convergence to the globally optimal solution. The experimental results demonstrate that the proposed approach is comparable to the existing state-of-the-art methods in terms of the estimate with a better runtime and memory footprint.