 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal panoramic 3D outdoor datasets for place categorization
Apr 14, 2026We present two multi-modal panoramic 3D outdoor (MPO) datasets for semantic place categorization with six categories: forest, coast, residential area, urban area and indoor/outdoor parking lot. The first dataset consists of 650 static panoramic scans of dense (9,000,000 points) 3D color and reflectance point clouds obtained using a FARO laser scanner with synchronized color images. The second dataset consists of 34,200 real-time panoramic scans of sparse (70,000 points) 3D reflectance point clouds obtained using a Velodyne laser scanner while driving a car. The datasets were obtained in the city of Fukuoka, Japan and are publicly available in [1], [2]. In addition, we compare several approaches for semantic place categorization with best results of 96.42% (dense) and 89.67% (sparse).
DRUM: Diffusion-based Raydrop-aware Unpaired Mapping for Sim2Real LiDAR Segmentation
Mar 27, 2026LiDAR-based semantic segmentation is a key component for autonomous mobile robots, yet large-scale annotation of LiDAR point clouds is prohibitively expensive and time-consuming. Although simulators can provide labeled synthetic data, models trained on synthetic data often underperform on real-world data due to a data-level domain gap. To address this issue, we propose DRUM, a novel Sim2Real translation framework. We leverage a diffusion model pre-trained on unlabeled real-world data as a generative prior and translate synthetic data by reproducing two key measurement characteristics: reflectance intensity and raydrop noise. To improve sample fidelity, we introduce a raydrop-aware masked guidance mechanism that selectively enforces consistency with the input synthetic data while preserving realistic raydrop noise induced by the diffusion prior. Experimental results demonstrate that DRUM consistently improves Sim2Real performance across multiple representations of LiDAR data. The project page is available at https://miya-tomoya.github.io/drum.
Learning Geometric and Photometric Features from Panoramic LiDAR Scans for Outdoor Place Categorization
Mar 13, 2026Semantic place categorization, which is one of the essential tasks for autonomous robots and vehicles, allows them to have capabilities of self-decision and navigation in unfamiliar environments. In particular, outdoor places are more difficult targets than indoor ones due to perceptual variations, such as dynamic illuminance over twenty-four hours and occlusions by cars and pedestrians. This paper presents a novel method of categorizing outdoor places using convolutional neural networks (CNNs), which take omnidirectional depth/reflectance images obtained by 3D LiDARs as the inputs. First, we construct a large-scale outdoor place dataset named Multi-modal Panoramic 3D Outdoor (MPO) comprising two types of point clouds captured by two different LiDARs. They are labeled with six outdoor place categories: coast, forest, indoor/outdoor parking, residential area, and urban area. Second, we provide CNNs for LiDAR-based outdoor place categorization and evaluate our approach with the MPO dataset. Our results on the MPO dataset outperform traditional approaches and show the effectiveness in which we use both depth and reflectance modalities. To analyze our trained deep networks we visualize the learned features.
* Published in Advanced Robotics on 31 Jul 2018
Fast LiDAR Data Generation with Rectified Flows
Dec 03, 2024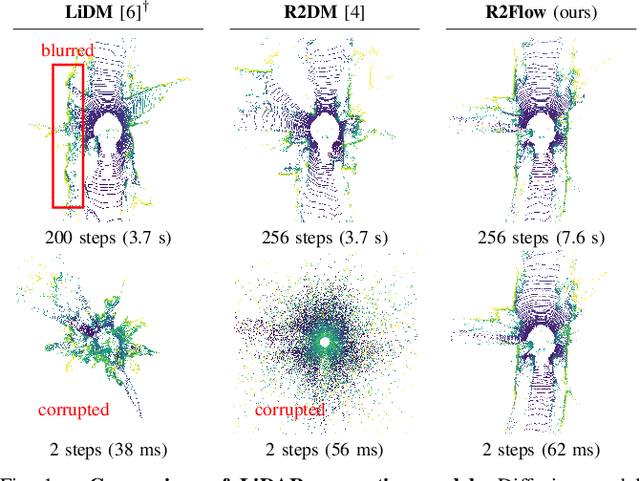
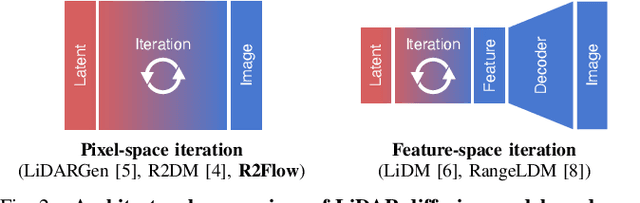

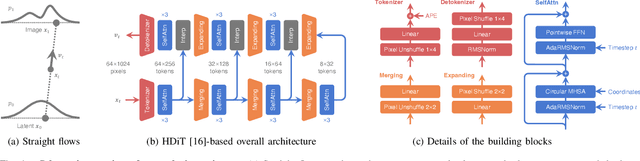
Building LiDAR generative models holds promise as powerful data priors for restoration, scene manipulation, and scalable simulation in autonomous mobile robots. In recent years, approaches using diffusion models have emerged, significantly improving training stability and generation quality. Despite the success of diffusion models, generating high-quality samples requires numerous iterations of running neural networks, and the increasing computational cost can pose a barrier to robotics applications. To address this challenge, this paper presents R2Flow, a fast and high-fidelity generative model for LiDAR data. Our method is based on rectified flows that learn straight trajectories, simulating data generation with much fewer sampling steps against diffusion models. We also propose a efficient Transformer-based model architecture for processing the image representation of LiDAR range and reflectance measurements. Our experiments on the unconditional generation of the KITTI-360 dataset demonstrate the effectiveness of our approach in terms of both efficiency and quality.
Gait Sequence Upsampling using Diffusion Models for single LiDAR sensors
Oct 11, 2024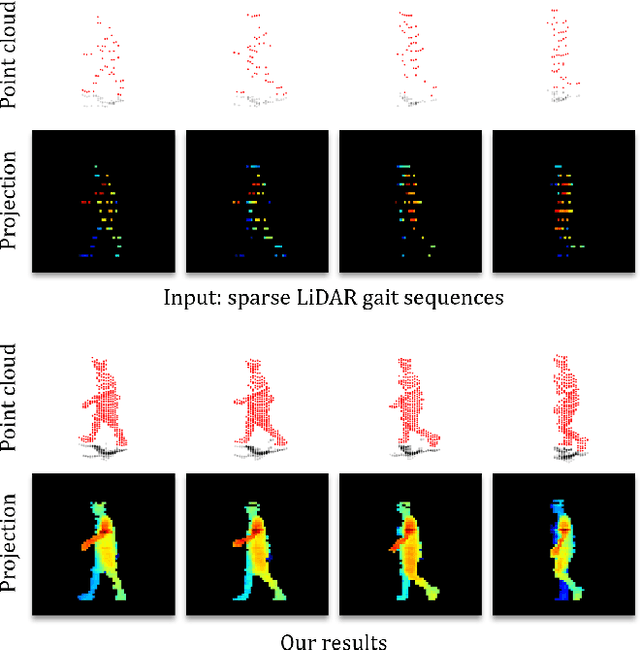
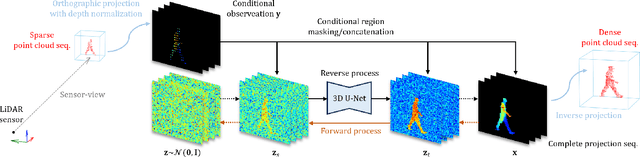

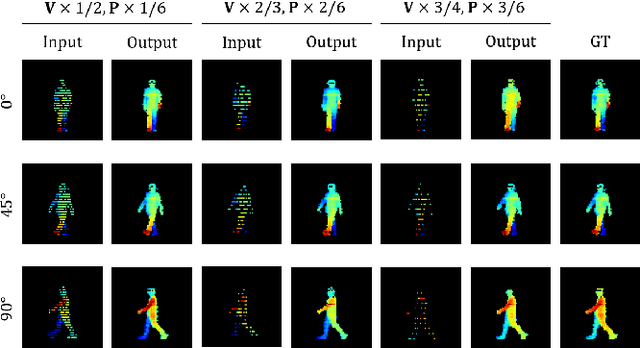
Recently, 3D LiDAR has emerged as a promising technique in the field of gait-based person identification, serving as an alternative to traditional RGB cameras, due to its robustness under varying lighting conditions and its ability to capture 3D geometric information. However, long capture distances or the use of low-cost LiDAR sensors often result in sparse human point clouds, leading to a decline in identification performance. To address these challenges, we propose a sparse-to-dense upsampling model for pedestrian point clouds in LiDAR-based gait recognition, named LidarGSU, which is designed to improve the generalization capability of existing identification models. Our method utilizes diffusion probabilistic models (DPMs), which have shown high fidelity in generative tasks such as image completion. In this work, we leverage DPMs on sparse sequential pedestrian point clouds as conditional masks in a video-to-video translation approach, applied in an inpainting manner. We conducted extensive experiments on the SUSTeck1K dataset to evaluate the generative quality and recognition performance of the proposed method. Furthermore, we demonstrate the applicability of our upsampling model using a real-world dataset, captured with a low-resolution sensor across varying measurement distances.
Stress Propagation in Human-Robot Teams Based on Computational Logic Model
Nov 08, 2022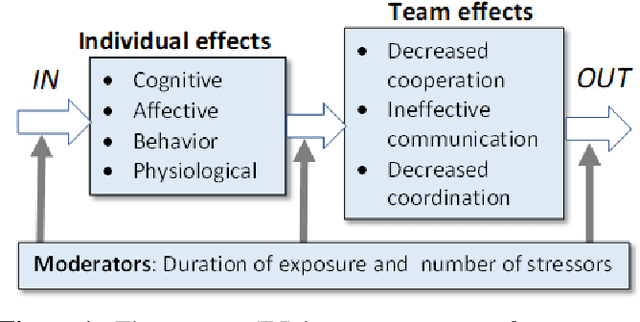
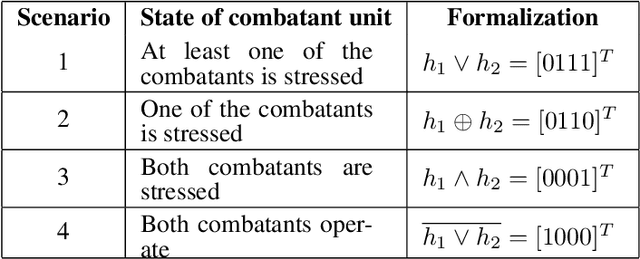
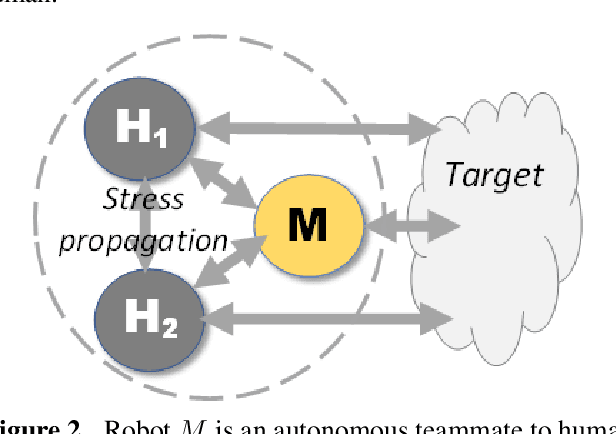
Mission teams are exposed to the emotional toll of life and death decisions. These are small groups of specially trained people supported by intelligent machines for dealing with stressful environments and scenarios. We developed a composite model for stress monitoring in such teams of human and autonomous machines. This modelling aims to identify the conditions that may contribute to mission failure. The proposed model is composed of three parts: 1) a computational logic part that statically describes the stress states of teammates; 2) a decision part that manifests the mission status at any time; 3) a stress propagation part based on standard Susceptible-Infected-Susceptible (SIS) paradigm. In contrast to the approaches such as agent-based, random-walk and game models, the proposed model combines various mechanisms to satisfy the conditions of stress propagation in small groups. Our core approach involves data structures such as decision tables and decision diagrams. These tools are adaptable to human-machine teaming as well.
Comprehensive Analysis of Time Series Forecasting Using Neural Networks
Jan 27, 2020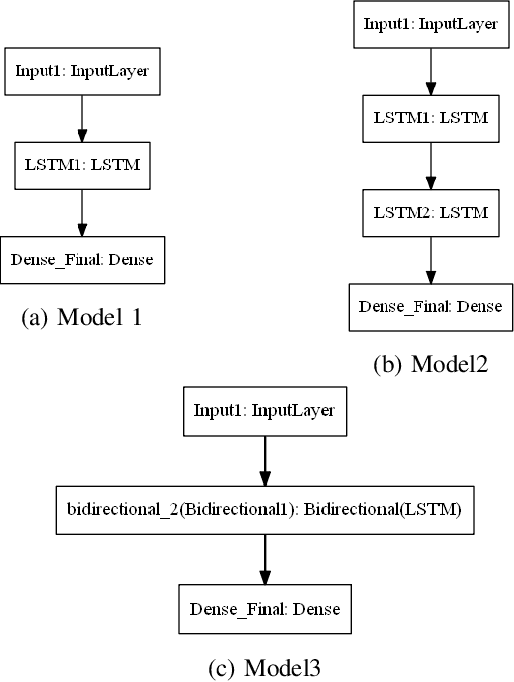
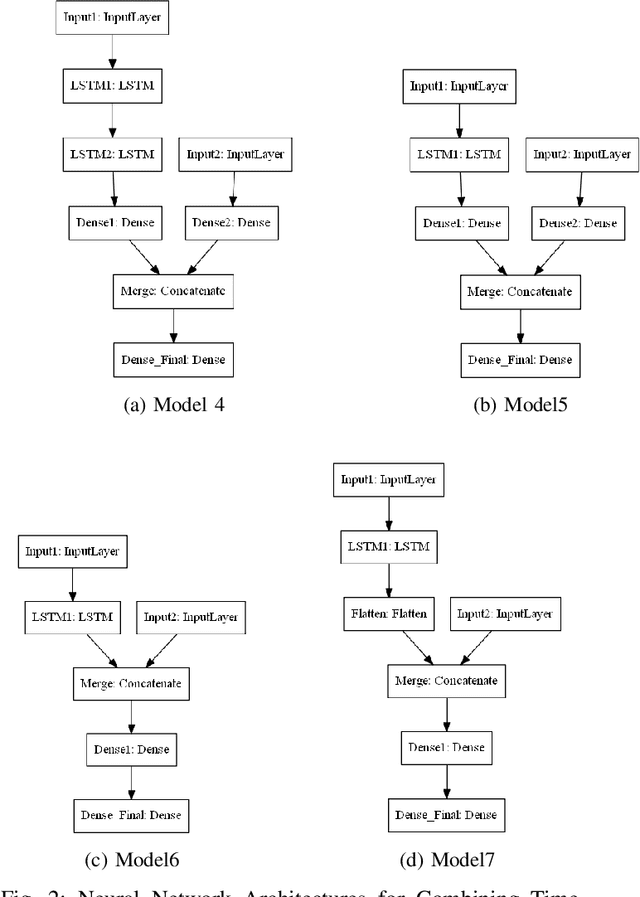
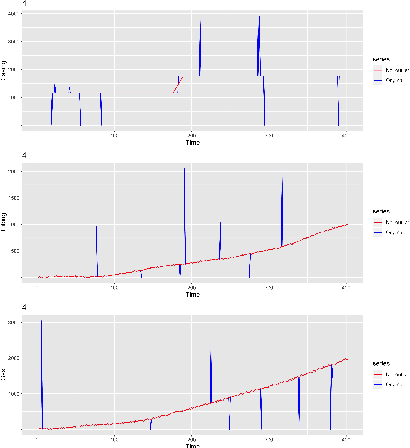
Time series forecasting has gained lots of attention recently; this is because many real-world phenomena can be modeled as time series. The massive volume of data and recent advancements in the processing power of the computers enable researchers to develop more sophisticated machine learning algorithms such as neural networks to forecast the time series data. In this paper, we propose various neural network architectures to forecast the time series data using the dynamic measurements; moreover, we introduce various architectures on how to combine static and dynamic measurements for forecasting. We also investigate the importance of performing techniques such as anomaly detection and clustering on forecasting accuracy. Our results indicate that clustering can improve the overall prediction time as well as improve the forecasting performance of the neural network. Furthermore, we show that feature-based clustering can outperform the distance-based clustering in terms of speed and efficiency. Finally, our results indicate that adding more predictors to forecast the target variable will not necessarily improve the forecasting accuracy.
Single Sample Feature Importance: An Interpretable Algorithm for Low-Level Feature Analysis
Nov 27, 2019


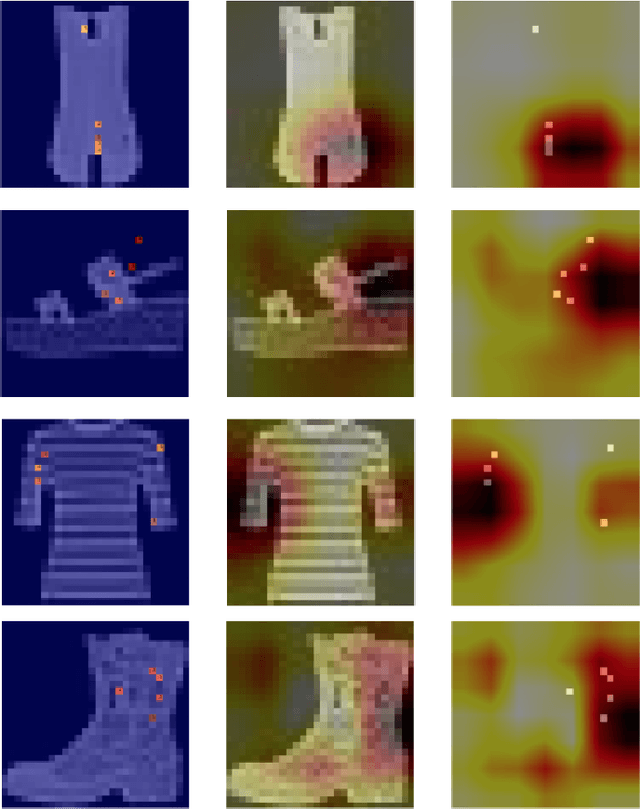
Have you ever wondered how your feature space is impacting the prediction of a specific sample in your dataset? In this paper, we introduce Single Sample Feature Importance (SSFI), which is an interpretable feature importance algorithm that allows for the identification of the most important features that contribute to the prediction of a single sample. When a dataset can be learned by a Random Forest classifier or regressor, SSFI shows how the Random Forest's prediction path can be utilized for low-level feature importance calculation. SSFI results in a relative ranking of features, highlighting those with the greatest impact on a data point's prediction. We demonstrate these results both numerically and visually on four different datasets.