 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGait Sequence Upsampling using Diffusion Models for single LiDAR sensors
Paper and Code
Oct 11, 2024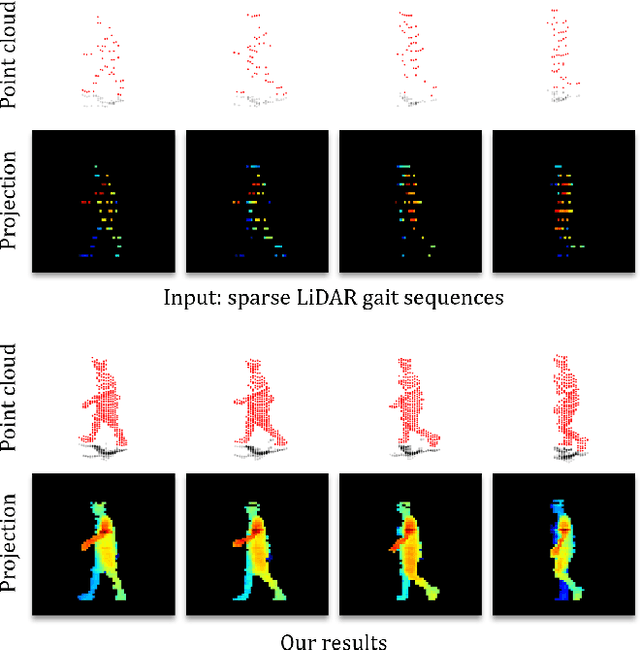
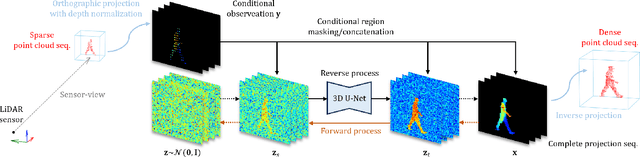

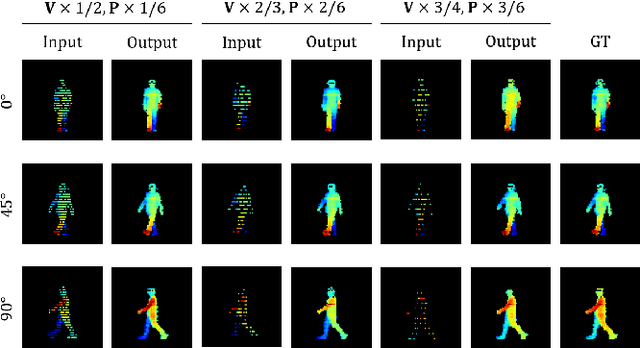
Recently, 3D LiDAR has emerged as a promising technique in the field of gait-based person identification, serving as an alternative to traditional RGB cameras, due to its robustness under varying lighting conditions and its ability to capture 3D geometric information. However, long capture distances or the use of low-cost LiDAR sensors often result in sparse human point clouds, leading to a decline in identification performance. To address these challenges, we propose a sparse-to-dense upsampling model for pedestrian point clouds in LiDAR-based gait recognition, named LidarGSU, which is designed to improve the generalization capability of existing identification models. Our method utilizes diffusion probabilistic models (DPMs), which have shown high fidelity in generative tasks such as image completion. In this work, we leverage DPMs on sparse sequential pedestrian point clouds as conditional masks in a video-to-video translation approach, applied in an inpainting manner. We conducted extensive experiments on the SUSTeck1K dataset to evaluate the generative quality and recognition performance of the proposed method. Furthermore, we demonstrate the applicability of our upsampling model using a real-world dataset, captured with a low-resolution sensor across varying measurement distances.