 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast LiDAR Data Generation with Rectified Flows
Dec 03, 2024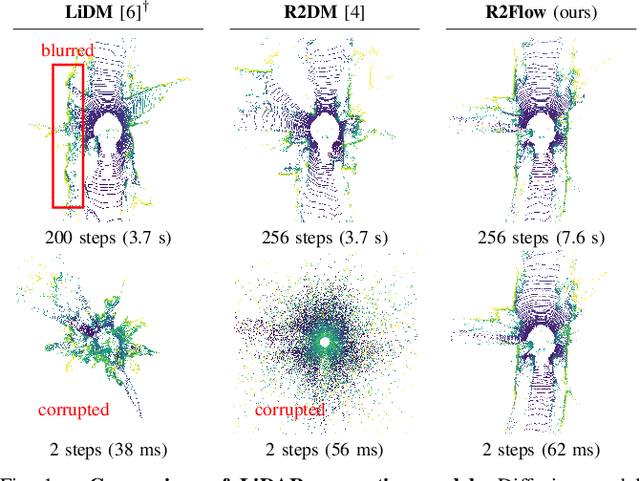
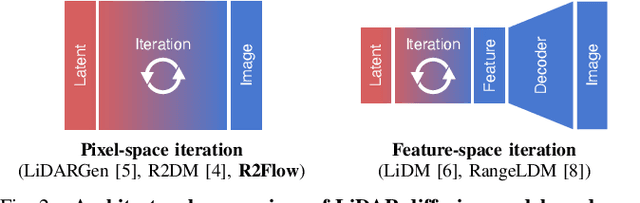

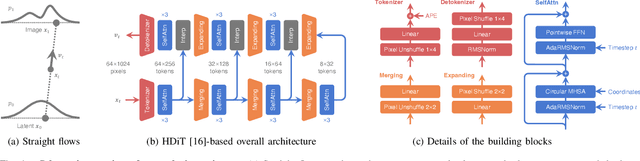
Building LiDAR generative models holds promise as powerful data priors for restoration, scene manipulation, and scalable simulation in autonomous mobile robots. In recent years, approaches using diffusion models have emerged, significantly improving training stability and generation quality. Despite the success of diffusion models, generating high-quality samples requires numerous iterations of running neural networks, and the increasing computational cost can pose a barrier to robotics applications. To address this challenge, this paper presents R2Flow, a fast and high-fidelity generative model for LiDAR data. Our method is based on rectified flows that learn straight trajectories, simulating data generation with much fewer sampling steps against diffusion models. We also propose a efficient Transformer-based model architecture for processing the image representation of LiDAR range and reflectance measurements. Our experiments on the unconditional generation of the KITTI-360 dataset demonstrate the effectiveness of our approach in terms of both efficiency and quality.
Gait Sequence Upsampling using Diffusion Models for single LiDAR sensors
Oct 11, 2024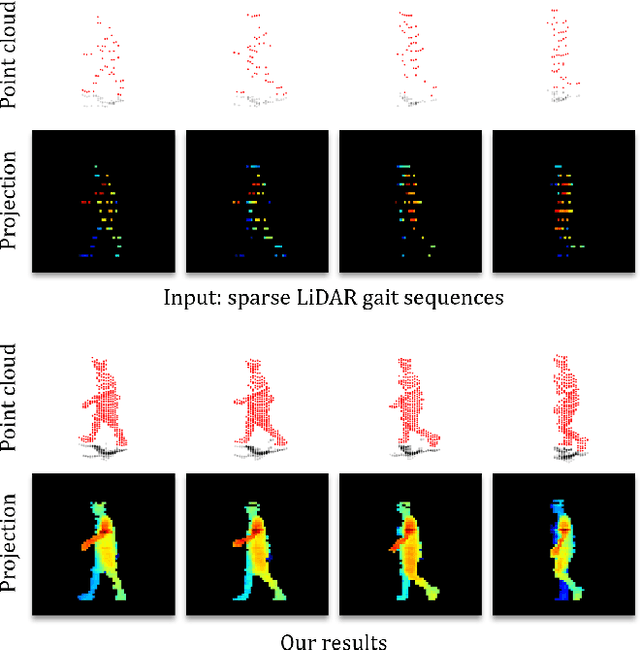
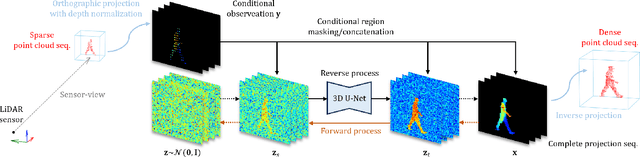

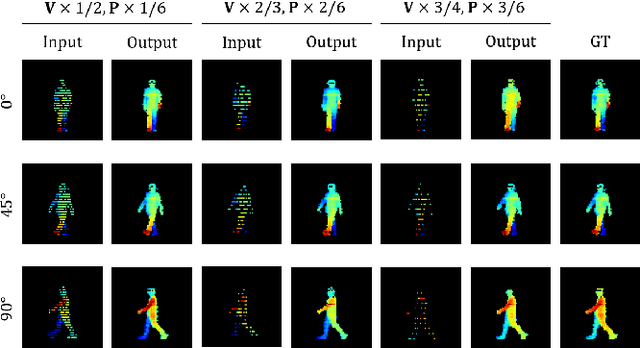
Recently, 3D LiDAR has emerged as a promising technique in the field of gait-based person identification, serving as an alternative to traditional RGB cameras, due to its robustness under varying lighting conditions and its ability to capture 3D geometric information. However, long capture distances or the use of low-cost LiDAR sensors often result in sparse human point clouds, leading to a decline in identification performance. To address these challenges, we propose a sparse-to-dense upsampling model for pedestrian point clouds in LiDAR-based gait recognition, named LidarGSU, which is designed to improve the generalization capability of existing identification models. Our method utilizes diffusion probabilistic models (DPMs), which have shown high fidelity in generative tasks such as image completion. In this work, we leverage DPMs on sparse sequential pedestrian point clouds as conditional masks in a video-to-video translation approach, applied in an inpainting manner. We conducted extensive experiments on the SUSTeck1K dataset to evaluate the generative quality and recognition performance of the proposed method. Furthermore, we demonstrate the applicability of our upsampling model using a real-world dataset, captured with a low-resolution sensor across varying measurement distances.
Fast LiDAR Upsampling using Conditional Diffusion Models
May 08, 2024The search for refining 3D LiDAR data has attracted growing interest motivated by recent techniques such as supervised learning or generative model-based methods. Existing approaches have shown the possibilities for using diffusion models to generate refined LiDAR data with high fidelity, although the performance and speed of such methods have been limited. These limitations make it difficult to execute in real-time, causing the approaches to struggle in real-world tasks such as autonomous navigation and human-robot interaction. In this work, we introduce a novel approach based on conditional diffusion models for fast and high-quality sparse-to-dense upsampling of 3D scene point clouds through an image representation. Our method employs denoising diffusion probabilistic models trained with conditional inpainting masks, which have been shown to give high performance on image completion tasks. We introduce a series of experiments, including multiple datasets, sampling steps, and conditional masks, to determine the ideal configuration, striking a balance between performance and inference speed. This paper illustrates that our method outperforms the baselines in sampling speed and quality on upsampling tasks using the KITTI-360 dataset. Furthermore, we illustrate the generalization ability of our approach by simultaneously training on real-world and synthetic datasets, introducing variance in quality and environments.
LiDAR Data Synthesis with Denoising Diffusion Probabilistic Models
Sep 17, 2023

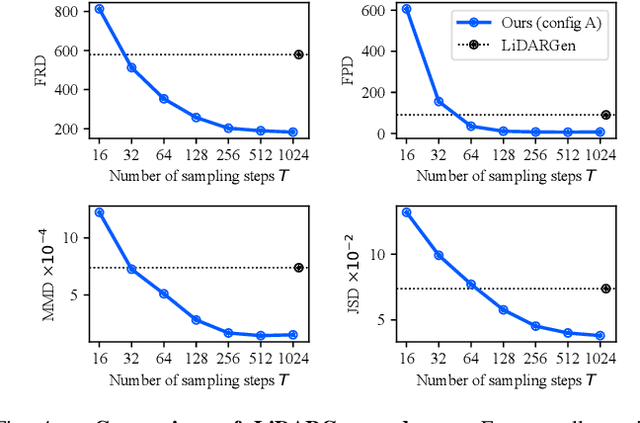

Generative modeling of 3D LiDAR data is an emerging task with promising applications for autonomous mobile robots, such as scalable simulation, scene manipulation, and sparse-to-dense completion of LiDAR point clouds. Existing approaches have shown the feasibility of image-based LiDAR data generation using deep generative models while still struggling with the fidelity of generated data and training instability. In this work, we present R2DM, a novel generative model for LiDAR data that can generate diverse and high-fidelity 3D scene point clouds based on the image representation of range and reflectance intensity. Our method is based on the denoising diffusion probabilistic models (DDPMs), which have demonstrated impressive results among generative model frameworks and have been significantly progressing in recent years. To effectively train DDPMs on the LiDAR domain, we first conduct an in-depth analysis regarding data representation, training objective, and spatial inductive bias. Based on our designed model R2DM, we also introduce a flexible LiDAR completion pipeline using the powerful properties of DDPMs. We demonstrate that our method outperforms the baselines on the generation task of KITTI-360 and KITTI-Raw datasets and the upsampling task of KITTI-360 datasets. Our code and pre-trained weights will be available at https://github.com/kazuto1011/r2dm.
Learning to Drop Points for LiDAR Scan Synthesis
Feb 23, 2021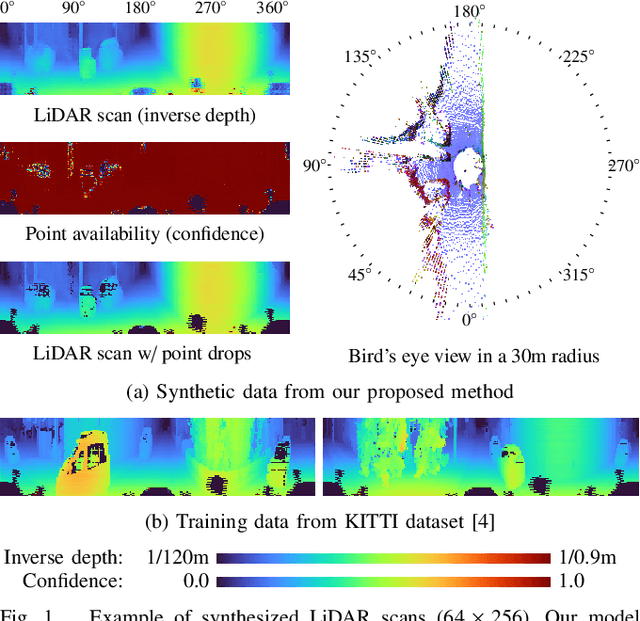


Generative modeling of 3D scenes is a crucial topic for aiding mobile robots to improve unreliable observations. However, despite the rapid progress in the natural image domain, building generative models is still challenging for 3D data, such as point clouds. Most existing studies on point clouds have focused on small and uniform-density data. In contrast, 3D LiDAR point clouds widely used in mobile robots are non-trivial to be handled because of the large number of points and varying-density. To circumvent this issue, 3D-to-2D projected representation such as a cylindrical depth map has been studied in existing LiDAR processing tasks but susceptible to discrete lossy pixels caused by failures of laser reflection. This paper proposes a novel framework based on generative adversarial networks to synthesize realistic LiDAR data as an improved 2D representation. Our generative architectures are designed to learn a distribution of inverse depth maps and simultaneously simulate the lossy pixels, which enables us to decompose an underlying smooth geometry and the corresponding uncertainty of laser reflection. To simulate the lossy pixels, we propose a differentiable framework to learn to produce sample-dependent binary masks using the Gumbel-Sigmoid reparametrization trick. We demonstrate the effectiveness of our approach in synthesis and reconstruction tasks on two LiDAR datasets. We further showcase potential applications by recovering various corruptions in LiDAR data.