 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphs RAG at Scale: Beyond Retrieval-Augmented Generation With Labeled Property Graphs and Resource Description Framework for Complex and Unknown Search Spaces
Mar 21, 2026Recent advances in Retrieval-Augmented Generation (RAG) have revolutionized knowledge-intensive tasks, yet traditional RAG methods struggle when the search space is unknown or when documents are semi-structured or structured. We introduce a novel end-to-end Graph RAG framework that leverages both Labeled Property Graph (LPG) and Resource Description Framework (RDF) architectures to overcome these limitations. Our approach enables dynamic document retrieval without the need to pre-specify the number of documents and eliminates inefficient reranking. We propose an innovative method for converting documents into RDF triplets using JSON key-value pairs, facilitating seamless integration of semi-structured data. Additionally, we present a text to Cypher framework for LPG, achieving over 90% accuracy in real-time translation of text queries to Cypher, enabling fast and reliable query generation suitable for online applications. Our empirical evaluation demonstrates that Graph RAG significantly outperforms traditional embedding-based RAG in accuracy, response quality, and reasoning, especially for complex, semi-structured tasks. These findings establish Graph RAG as a transformative solution for next-generation retrieval-augmented systems.
Causal Inference in Educational Systems: A Graphical Modeling Approach
Aug 02, 2021

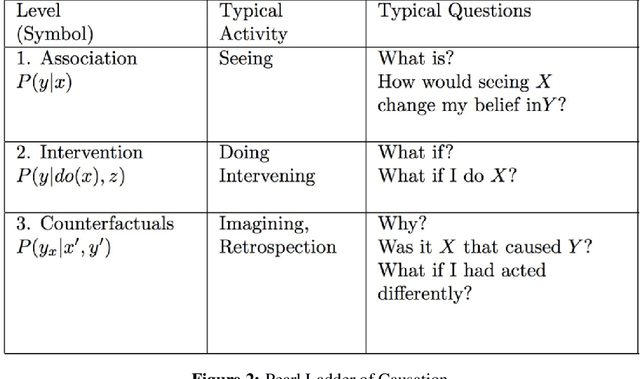
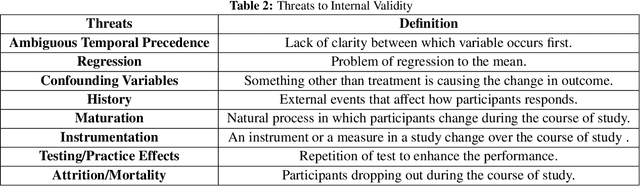
Educational systems have traditionally been evaluated using cross-sectional studies, namely, examining a pretest, posttest, and single intervention. Although this is a popular approach, it does not model valuable information such as confounding variables, feedback to students, and other real-world deviations of studies from ideal conditions. Moreover, learning inherently is a sequential process and should involve a sequence of interventions. In this paper, we propose various experimental and quasi-experimental designs for educational systems and quantify them using the graphical model and directed acyclic graph (DAG) language. We discuss the applications and limitations of each method in education. Furthermore, we propose to model the education system as time-varying treatments, confounders, and time-varying treatments-confounders feedback. We show that if we control for a sufficient set of confounders and use appropriate inference techniques such as the inverse probability of treatment weighting (IPTW) or g-formula, we can close the backdoor paths and derive the unbiased causal estimate of joint interventions on the outcome. Finally, we compare the g-formula and IPTW performance and discuss the pros and cons of using each method.
tsBNgen: A Python Library to Generate Time Series Data from an Arbitrary Dynamic Bayesian Network Structure
Sep 09, 2020
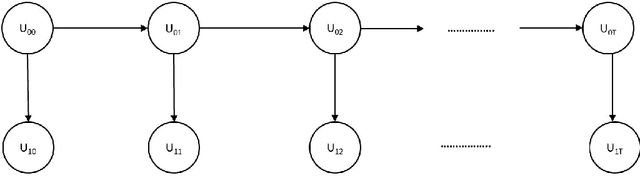
Synthetic data is widely used in various domains. This is because many modern algorithms require lots of data for efficient training, and data collection and labeling usually are a time-consuming process and are prone to errors. Furthermore, some real-world data, due to its nature, is confidential and cannot be shared. Bayesian networks are a type of probabilistic graphical model widely used to model the uncertainties in real-world processes. Dynamic Bayesian networks are a special class of Bayesian networks that model temporal and time series data. In this paper, we introduce the tsBNgen, a Python library to generate time series and sequential data based on an arbitrary dynamic Bayesian network. The package, documentation, and examples can be downloaded from https://github.com/manitadayon/tsBNgen.
Comparative Analysis of the Hidden Markov Model and LSTM: A Simulative Approach
Aug 09, 2020Time series and sequential data have gained significant attention recently since many real-world processes in various domains such as finance, education, biology, and engineering can be modeled as time series. Although many algorithms and methods such as the Kalman filter, hidden Markov model, and long short term memory (LSTM) are proposed to make inferences and predictions for the data, their usage significantly depends on the application, type of the problem, available data, and sufficient accuracy or loss. In this paper, we compare the supervised and unsupervised hidden Markov model to LSTM in terms of the amount of data needed for training, complexity, and forecasting accuracy. Moreover, we propose various techniques to discretize the observations and convert the problem to a discrete hidden Markov model under stationary and non-stationary situations. Our results indicate that even an unsupervised hidden Markov model can outperform LSTM when a massive amount of labeled data is not available. Furthermore, we show that the hidden Markov model can still be an effective method to process the sequence data even when the first-order Markov assumption is not satisfied.
Comprehensive Analysis of Time Series Forecasting Using Neural Networks
Jan 27, 2020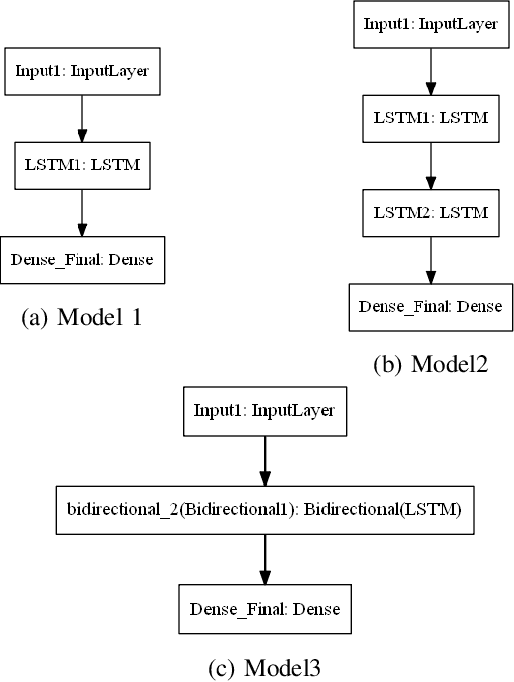
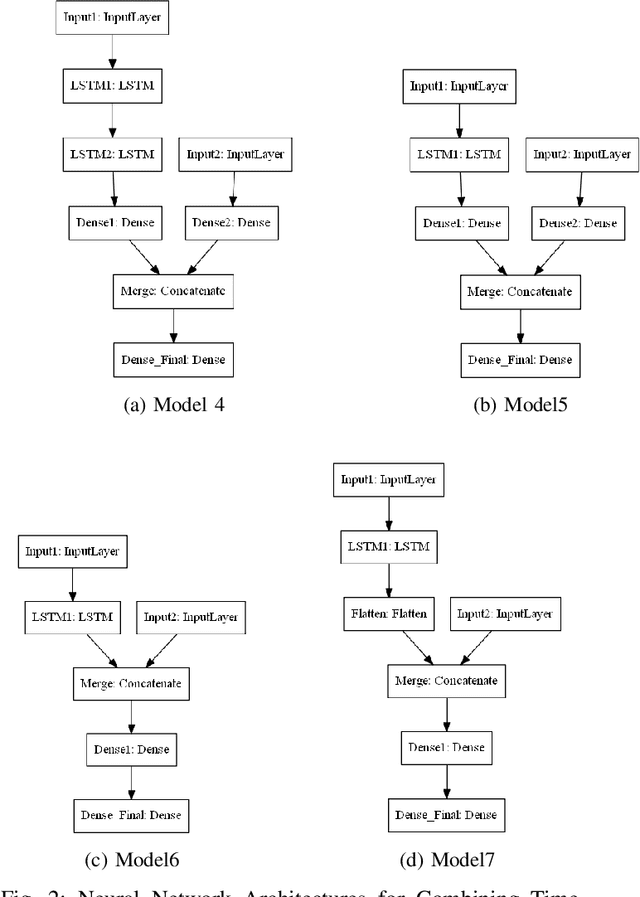
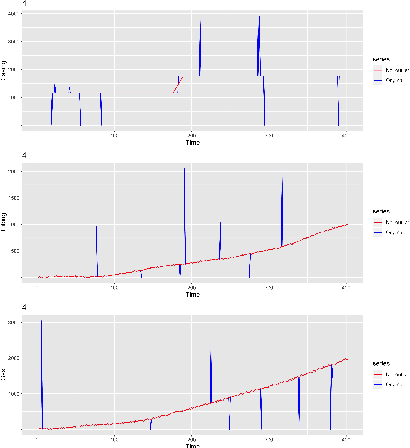
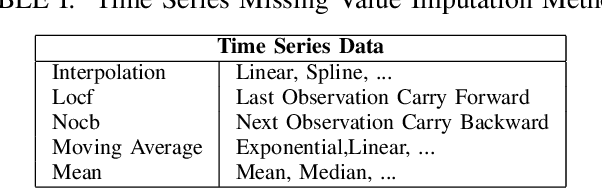
Time series forecasting has gained lots of attention recently; this is because many real-world phenomena can be modeled as time series. The massive volume of data and recent advancements in the processing power of the computers enable researchers to develop more sophisticated machine learning algorithms such as neural networks to forecast the time series data. In this paper, we propose various neural network architectures to forecast the time series data using the dynamic measurements; moreover, we introduce various architectures on how to combine static and dynamic measurements for forecasting. We also investigate the importance of performing techniques such as anomaly detection and clustering on forecasting accuracy. Our results indicate that clustering can improve the overall prediction time as well as improve the forecasting performance of the neural network. Furthermore, we show that feature-based clustering can outperform the distance-based clustering in terms of speed and efficiency. Finally, our results indicate that adding more predictors to forecast the target variable will not necessarily improve the forecasting accuracy.
Predicting Student Performance in an Educational Game Using a Hidden Markov Model
Apr 24, 2019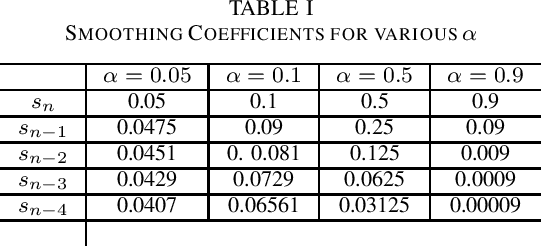
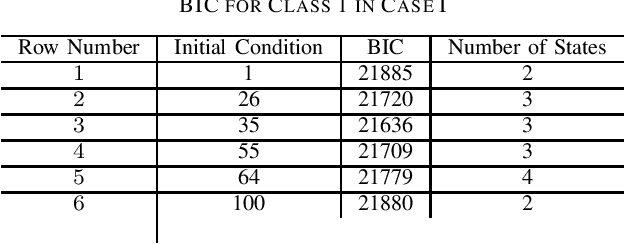
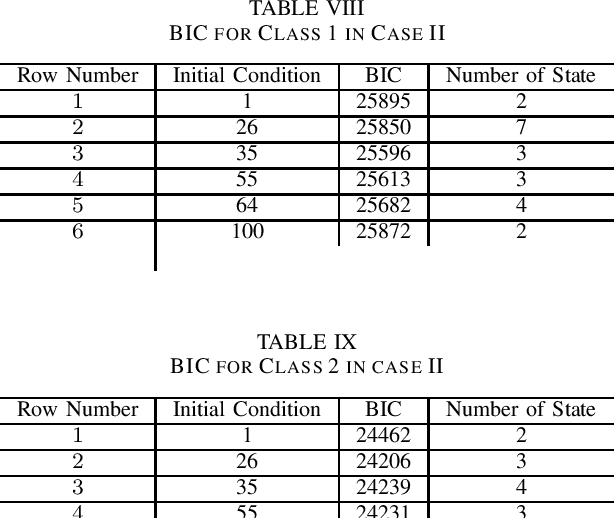
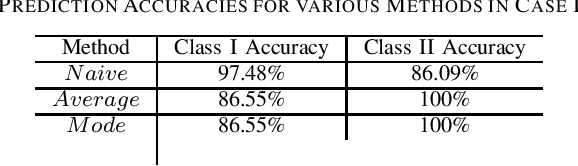
Contributions: Prior studies on education have mostly followed the model of the cross sectional study, namely, examining the pretest and the posttest scores. This paper shows that students' knowledge throughout the intervention can be estimated by time series analysis using a hidden Markov model. Background: Analyzing time series and the interaction between the students and the game data can result in valuable information that cannot be gained by only cross sectional studies of the exams. Research Questions: Can a hidden Markov model be used to analyze the educational games? Can a hidden Markov model be used to make a prediction of the students' performance? Methodology: The study was conducted on (N=854) students who played the Save Patch game. Students were divided into class 1 and class 2. Class 1 students are those who scored lower in the test than class 2 students. The analysis is done by choosing various features of the game as the observations. Findings: The state trajectories can predict the students' performance accurately for both class 1 and class 2.