 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle Sample Feature Importance: An Interpretable Algorithm for Low-Level Feature Analysis
Paper and Code
Nov 27, 2019


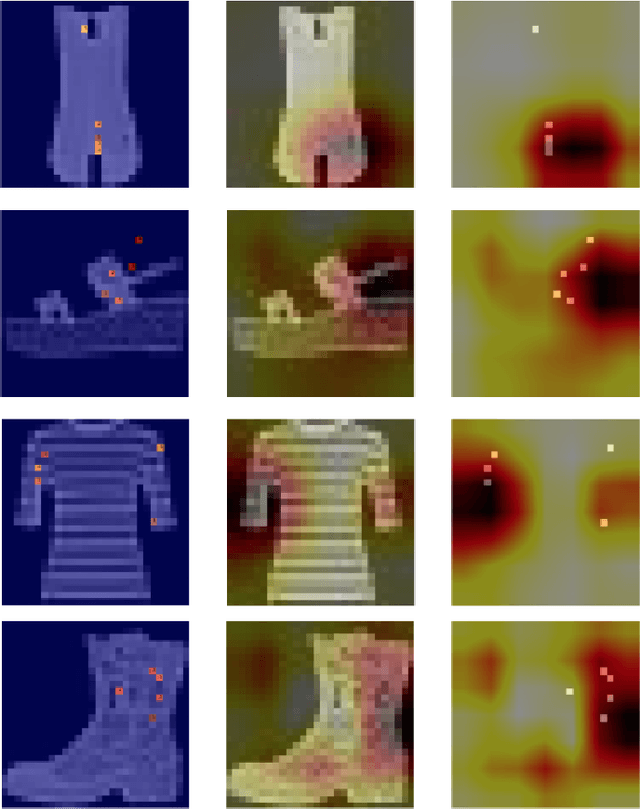
Have you ever wondered how your feature space is impacting the prediction of a specific sample in your dataset? In this paper, we introduce Single Sample Feature Importance (SSFI), which is an interpretable feature importance algorithm that allows for the identification of the most important features that contribute to the prediction of a single sample. When a dataset can be learned by a Random Forest classifier or regressor, SSFI shows how the Random Forest's prediction path can be utilized for low-level feature importance calculation. SSFI results in a relative ranking of features, highlighting those with the greatest impact on a data point's prediction. We demonstrate these results both numerically and visually on four different datasets.