 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaTeS: Latent Space Distillation for Teacher-Student Driving Policy Learning
Paper and Code


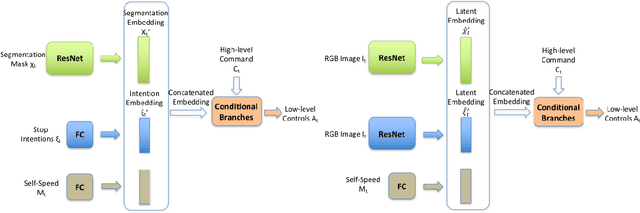

We describe a policy learning approach to map visual inputs to driving controls that leverages side information on semantics and affordances of objects in the scene from a secondary teacher model. While the teacher receives semantic segmentation and stop "intention" values as inputs and produces an estimate of the driving controls, the primary student model only receives images as inputs, and attempts to imitate the controls while being biased towards the latent representation of the teacher model. The latent representation encodes task-relevant information in the inputs of the teacher model, which are semantic segmentation of the image, and intention values for driving controls in the presence of objects in the scene such as vehicles, pedestrians and traffic lights. Our student model does not attempt to infer semantic segmentation or intention values from its inputs, nor to mimic the output behavior of the teacher. It instead attempts to capture the representation of the teacher inputs that are relevant for driving. Our training does not require laborious annotations such as maps or objects in three dimensions; even the teacher model just requires two-dimensional segmentation and intention values. Moreover, our model runs in real time of 59 FPS. We test our approach on recent simulated and real-world driving datasets, and introduce a more challenging but realistic evaluation protocol that considers a run that reaches the destination successful only if it does not violate common traffic rules.