 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Detection
Paper and Code
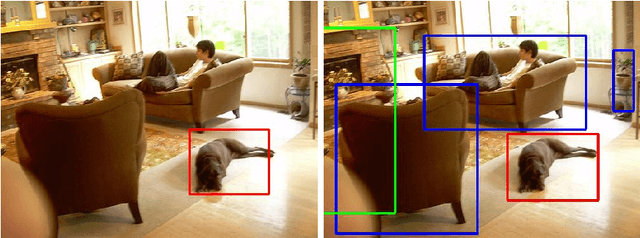


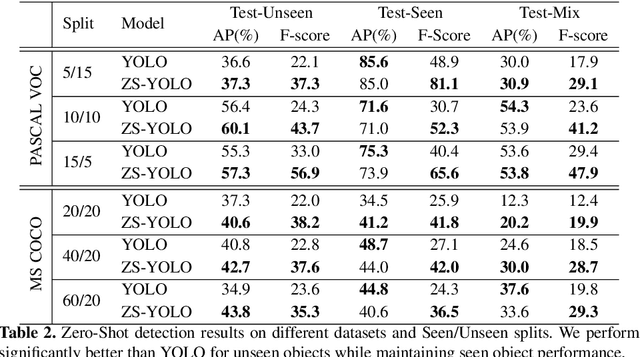
As we move towards large-scale object detection, it is unrealistic to expect annotated training data for all object classes at sufficient scale, and so methods capable of unseen object detection are required. We propose a novel zero-shot method based on training an end-to-end model that fuses semantic attribute prediction with visual features to propose object bounding boxes for seen and unseen classes. While we utilize semantic features during training, our method is agnostic to semantic information for unseen classes at test-time. Our method retains the efficiency and effectiveness of YOLO for objects seen during training, while improving its performance for novel and unseen objects. The ability of state-of-art detection methods to learn discriminative object features to reject background proposals also limits their performance for unseen objects. We posit that, to detect unseen objects, we must incorporate semantic information into the visual domain so that the learned visual features reflect this information and leads to improved recall rates for unseen objects. We test our method on PASCAL VOC and MS COCO dataset and observed significant improvements on the average precision of unseen classes.