 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBabyVLM: Data-Efficient Pretraining of VLMs Inspired by Infant Learning
Paper and Code
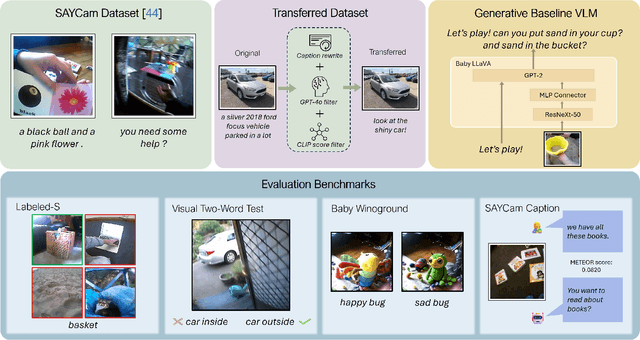

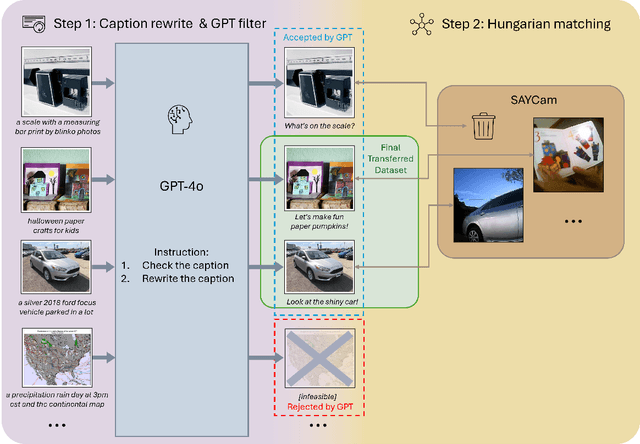

Human infants rapidly develop visual reasoning skills from minimal input, suggesting that developmentally inspired pretraining could significantly enhance the efficiency of vision-language models (VLMs). Although recent efforts have leveraged infant-inspired datasets like SAYCam, existing evaluation benchmarks remain misaligned--they are either too simplistic, narrowly scoped, or tailored for large-scale pretrained models. Additionally, training exclusively on infant data overlooks the broader, diverse input from which infants naturally learn. To address these limitations, we propose BabyVLM, a novel framework comprising comprehensive in-domain evaluation benchmarks and a synthetic training dataset created via child-directed transformations of existing datasets. We demonstrate that VLMs trained with our synthetic dataset achieve superior performance on BabyVLM tasks compared to models trained solely on SAYCam or general-purpose data of the SAYCam size. BabyVLM thus provides a robust, developmentally aligned evaluation tool and illustrates how compact models trained on carefully curated data can generalize effectively, opening pathways toward data-efficient vision-language learning paradigms.