 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate Inference for Adaptive Linear Models
Jun 20, 2018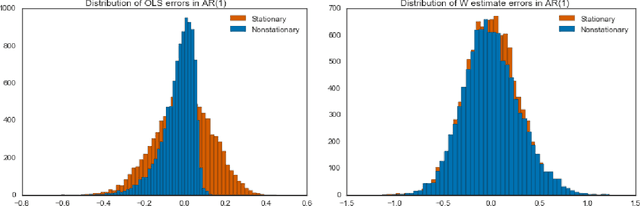
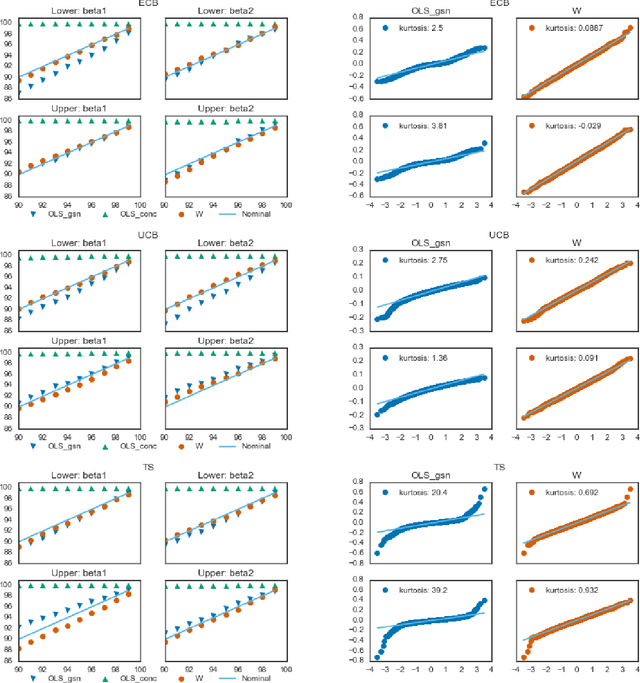
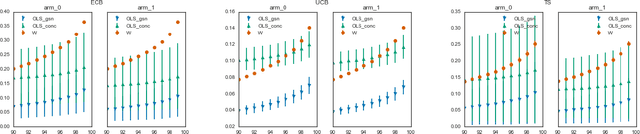
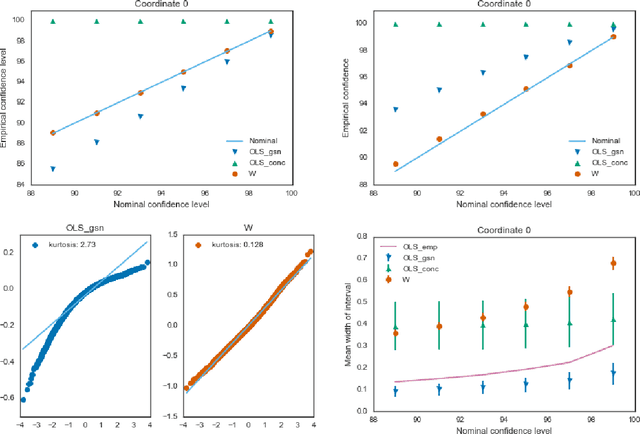
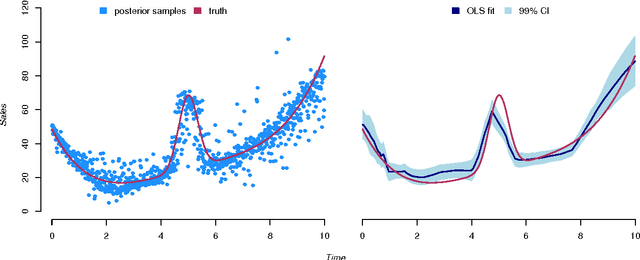
Estimators computed from adaptively collected data do not behave like their non-adaptive brethren. Rather, the sequential dependence of the collection policy can lead to severe distributional biases that persist even in the infinite data limit. We develop a general method -- $\mathbf{W}$-decorrelation -- for transforming the bias of adaptive linear regression estimators into variance. The method uses only coarse-grained information about the data collection policy and does not need access to propensity scores or exact knowledge of the policy. We bound the finite-sample bias and variance of the $\mathbf{W}$-estimator and develop asymptotically correct confidence intervals based on a novel martingale central limit theorem. We then demonstrate the empirical benefits of the generic $\mathbf{W}$-decorrelation procedure in two different adaptive data settings: the multi-armed bandit and the autoregressive time series.
The Geometry of Culture: Analyzing Meaning through Word Embeddings
Mar 25, 2018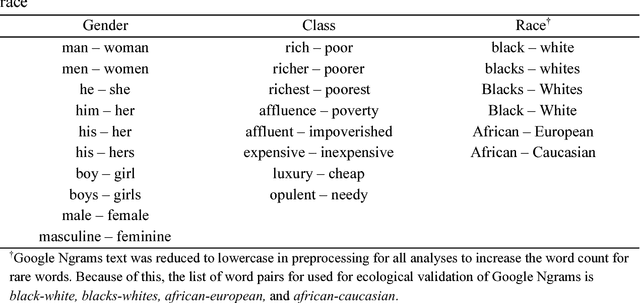
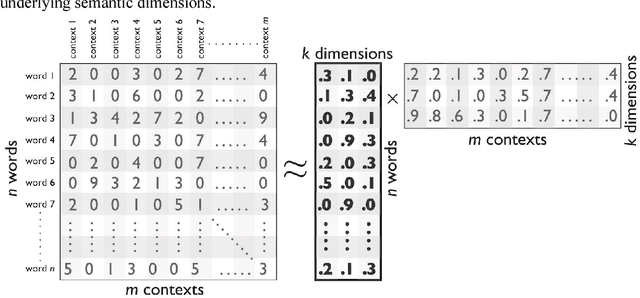
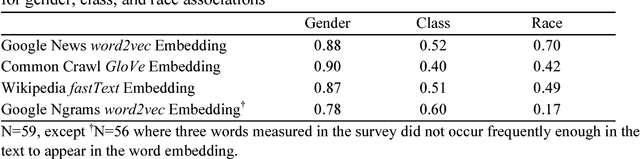
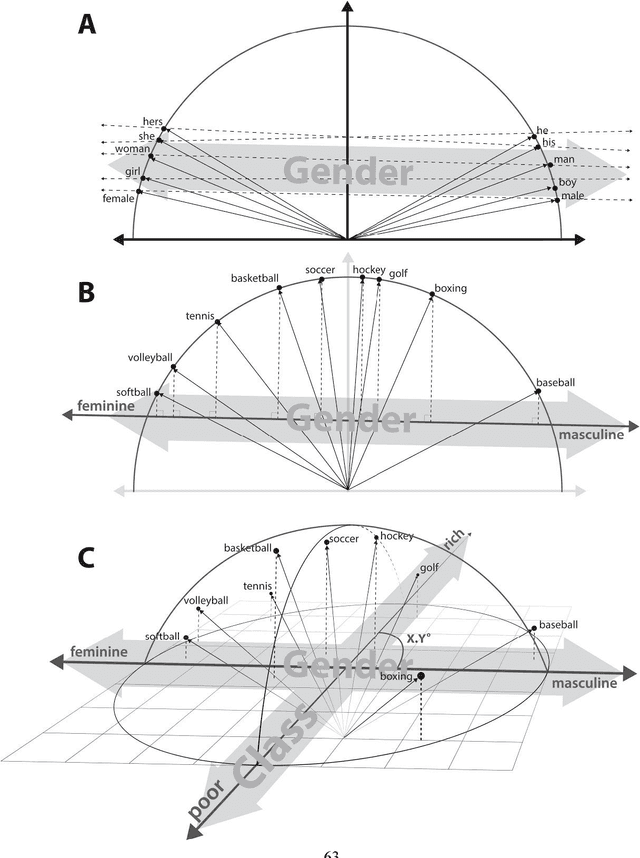
We demonstrate the utility of a new methodological tool, neural-network word embedding models, for large-scale text analysis, revealing how these models produce richer insights into cultural associations and categories than possible with prior methods. Word embeddings represent semantic relations between words as geometric relationships between vectors in a high-dimensional space, operationalizing a relational model of meaning consistent with contemporary theories of identity and culture. We show that dimensions induced by word differences (e.g. man - woman, rich - poor, black - white, liberal - conservative) in these vector spaces closely correspond to dimensions of cultural meaning, and the projection of words onto these dimensions reflects widely shared cultural connotations when compared to surveyed responses and labeled historical data. We pilot a method for testing the stability of these associations, then demonstrate applications of word embeddings for macro-cultural investigation with a longitudinal analysis of the coevolution of gender and class associations in the United States over the 20th century and a comparative analysis of historic distinctions between markers of gender and class in the U.S. and Britain. We argue that the success of these high-dimensional models motivates a move towards "high-dimensional theorizing" of meanings, identities and cultural processes.
Low-rank Bandit Methods for High-dimensional Dynamic Pricing
Jan 30, 2018
We consider high dimensional dynamic multi-product pricing with an evolving but low-dimensional linear demand model. Assuming the temporal variation in cross-elasticities exhibits low-rank structure based on fixed (latent) features of the products, we show that the revenue maximization problem reduces to an online bandit convex optimization with side information given by the observed demands. We design dynamic pricing algorithms whose revenue approaches that of the best fixed price vector in hindsight, at a rate that only depends on the intrinsic rank of the demand model and not the number of products. Our approach applies a bandit convex optimization algorithm in a projected low-dimensional space spanned by the latent product features, while simultaneously learning this span via online singular value decomposition of a carefully-crafted matrix containing the observed demands.
Orthogonal Machine Learning for Demand Estimation: High Dimensional Causal Inference in Dynamic Panels
Jan 10, 2018
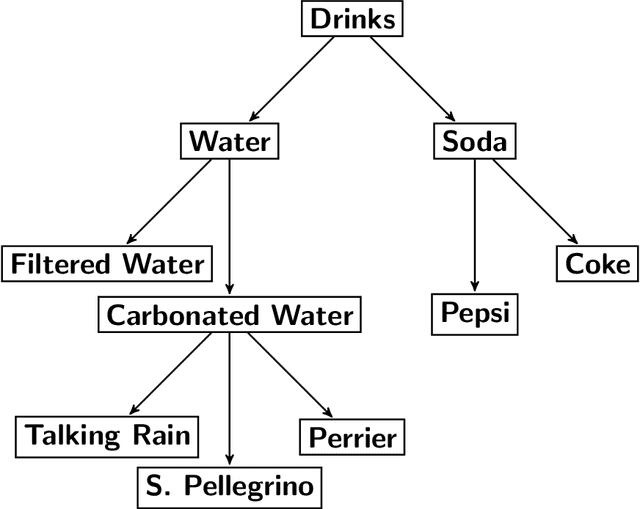

There has been growing interest in how economists can import machine learning tools designed for prediction to accelerate and automate the model selection process, while still retaining desirable inference properties for causal parameters. Focusing on partially linear models, we extend the Double ML framework to allow for (1) a number of treatments that may grow with the sample size and (2) the analysis of panel data under sequentially exogenous errors. Our low-dimensional treatment (LD) regime directly extends the work in [Chernozhukov et al., 2016], by showing that the coefficients from a second stage, ordinary least squares estimator attain root-n convergence and desired coverage even if the dimensionality of treatment is allowed to grow. In a high-dimensional sparse (HDS) regime, we show that second stage LASSO and debiased LASSO have asymptotic properties equivalent to oracle estimators with no upstream error. We argue that these advances make Double ML methods a desirable alternative for practitioners estimating short-term demand elasticities in non-contractual settings.
Beyond Bilingual: Multi-sense Word Embeddings using Multilingual Context
Jun 25, 2017
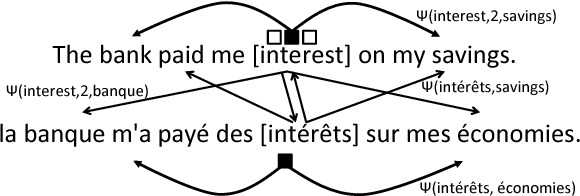
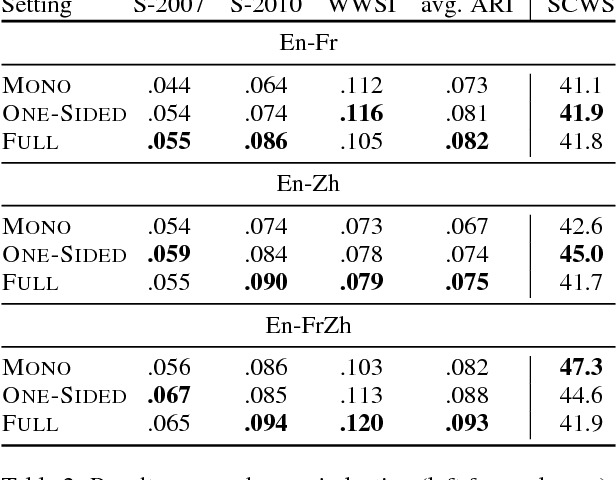
Word embeddings, which represent a word as a point in a vector space, have become ubiquitous to several NLP tasks. A recent line of work uses bilingual (two languages) corpora to learn a different vector for each sense of a word, by exploiting crosslingual signals to aid sense identification. We present a multi-view Bayesian non-parametric algorithm which improves multi-sense word embeddings by (a) using multilingual (i.e., more than two languages) corpora to significantly improve sense embeddings beyond what one achieves with bilingual information, and (b) uses a principled approach to learn a variable number of senses per word, in a data-driven manner. Ours is the first approach with the ability to leverage multilingual corpora efficiently for multi-sense representation learning. Experiments show that multilingual training significantly improves performance over monolingual and bilingual training, by allowing us to combine different parallel corpora to leverage multilingual context. Multilingual training yields comparable performance to a state of the art mono-lingual model trained on five times more training data.
Counterfactual Prediction with Deep Instrumental Variables Networks
Dec 30, 2016
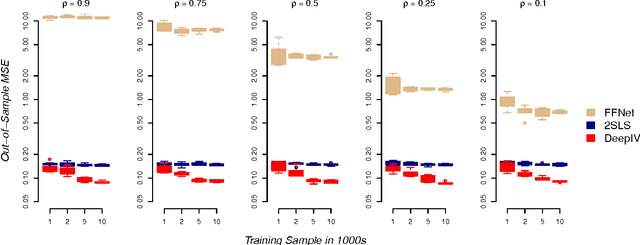
We are in the middle of a remarkable rise in the use and capability of artificial intelligence. Much of this growth has been fueled by the success of deep learning architectures: models that map from observables to outputs via multiple layers of latent representations. These deep learning algorithms are effective tools for unstructured prediction, and they can be combined in AI systems to solve complex automated reasoning problems. This paper provides a recipe for combining ML algorithms to solve for causal effects in the presence of instrumental variables -- sources of treatment randomization that are conditionally independent from the response. We show that a flexible IV specification resolves into two prediction tasks that can be solved with deep neural nets: a first-stage network for treatment prediction and a second-stage network whose loss function involves integration over the conditional treatment distribution. This Deep IV framework imposes some specific structure on the stochastic gradient descent routine used for training, but it is general enough that we can take advantage of off-the-shelf ML capabilities and avoid extensive algorithm customization. We outline how to obtain out-of-sample causal validation in order to avoid over-fit. We also introduce schemes for both Bayesian and frequentist inference: the former via a novel adaptation of dropout training, and the latter via a data splitting routine.
Document Classification by Inversion of Distributed Language Representations
Jul 24, 2015

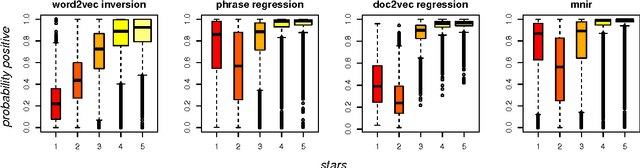
There have been many recent advances in the structure and measurement of distributed language models: those that map from words to a vector-space that is rich in information about word choice and composition. This vector-space is the distributed language representation. The goal of this note is to point out that any distributed representation can be turned into a classifier through inversion via Bayes rule. The approach is simple and modular, in that it will work with any language representation whose training can be formulated as optimizing a probability model. In our application to 2 million sentences from Yelp reviews, we also find that it performs as well as or better than complex purpose-built algorithms.