 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Space Attacks against Random-Walk-based Anomaly Detection
Jul 26, 2023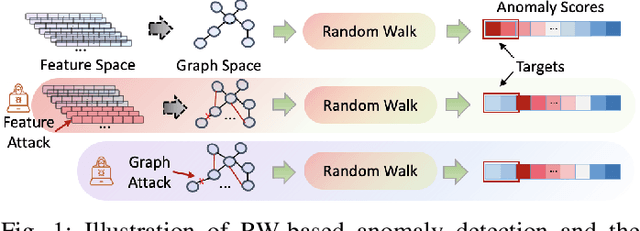
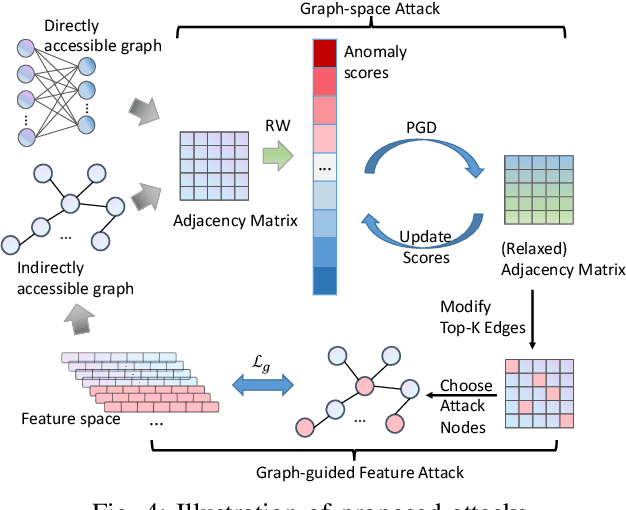
Random Walks-based Anomaly Detection (RWAD) is commonly used to identify anomalous patterns in various applications. An intriguing characteristic of RWAD is that the input graph can either be pre-existing or constructed from raw features. Consequently, there are two potential attack surfaces against RWAD: graph-space attacks and feature-space attacks. In this paper, we explore this vulnerability by designing practical dual-space attacks, investigating the interplay between graph-space and feature-space attacks. To this end, we conduct a thorough complexity analysis, proving that attacking RWAD is NP-hard. Then, we proceed to formulate the graph-space attack as a bi-level optimization problem and propose two strategies to solve it: alternative iteration (alterI-attack) or utilizing the closed-form solution of the random walk model (cf-attack). Finally, we utilize the results from the graph-space attacks as guidance to design more powerful feature-space attacks (i.e., graph-guided attacks). Comprehensive experiments demonstrate that our proposed attacks are effective in enabling the target nodes from RWAD with a limited attack budget. In addition, we conduct transfer attack experiments in a black-box setting, which show that our feature attack significantly decreases the anomaly scores of target nodes. Our study opens the door to studying the dual-space attack against graph anomaly detection in which the graph space relies on the feature space.
Human intuition as a defense against attribute inference
Apr 24, 2023Attribute inference - the process of analyzing publicly available data in order to uncover hidden information - has become a major threat to privacy, given the recent technological leap in machine learning. One way to tackle this threat is to strategically modify one's publicly available data in order to keep one's private information hidden from attribute inference. We evaluate people's ability to perform this task, and compare it against algorithms designed for this purpose. We focus on three attributes: the gender of the author of a piece of text, the country in which a set of photos was taken, and the link missing from a social network. For each of these attributes, we find that people's effectiveness is inferior to that of AI, especially when it comes to hiding the attribute in question. Moreover, when people are asked to modify the publicly available information in order to hide these attributes, they are less likely to make high-impact modifications compared to AI. This suggests that people are unable to recognize the aspects of the data that are critical to an inference algorithm. Taken together, our findings highlight the limitations of relying on human intuition to protect privacy in the age of AI, and emphasize the need for algorithmic support to protect private information from attribute inference.