 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Stealing Graph Neural Network Models
Nov 13, 2025Current graph neural network (GNN) model-stealing methods rely heavily on queries to the victim model, assuming no hard query limits. However, in reality, the number of allowed queries can be severely limited. In this paper, we demonstrate how an adversary can extract a GNN with very limited interactions with the model. Our approach first enables the adversary to obtain the model backbone without making direct queries to the victim model and then to strategically utilize a fixed query limit to extract the most informative data. The experiments on eight real-world datasets demonstrate the effectiveness of the attack, even under a very restricted query limit and under defense against model extraction in place. Our findings underscore the need for robust defenses against GNN model extraction threats.
Graph Anomaly Detection at Group Level: A Topology Pattern Enhanced Unsupervised Approach
Aug 02, 2023



Graph anomaly detection (GAD) has achieved success and has been widely applied in various domains, such as fraud detection, cybersecurity, finance security, and biochemistry. However, existing graph anomaly detection algorithms focus on distinguishing individual entities (nodes or graphs) and overlook the possibility of anomalous groups within the graph. To address this limitation, this paper introduces a novel unsupervised framework for a new task called Group-level Graph Anomaly Detection (Gr-GAD). The proposed framework first employs a variant of Graph AutoEncoder (GAE) to locate anchor nodes that belong to potential anomaly groups by capturing long-range inconsistencies. Subsequently, group sampling is employed to sample candidate groups, which are then fed into the proposed Topology Pattern-based Graph Contrastive Learning (TPGCL) method. TPGCL utilizes the topology patterns of groups as clues to generate embeddings for each candidate group and thus distinct anomaly groups. The experimental results on both real-world and synthetic datasets demonstrate that the proposed framework shows superior performance in identifying and localizing anomaly groups, highlighting it as a promising solution for Gr-GAD. Datasets and codes of the proposed framework are at the github repository https://anonymous.4open.science/r/Topology-Pattern-Enhanced-Unsupervised-Group-level-Graph-Anomaly-Detection.
Dual-Space Attacks against Random-Walk-based Anomaly Detection
Jul 26, 2023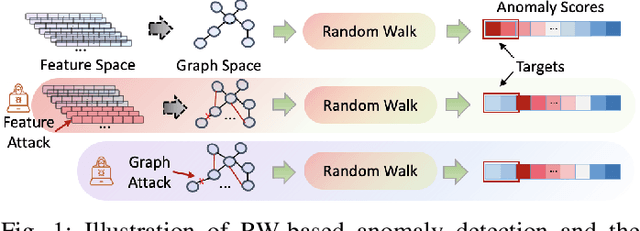
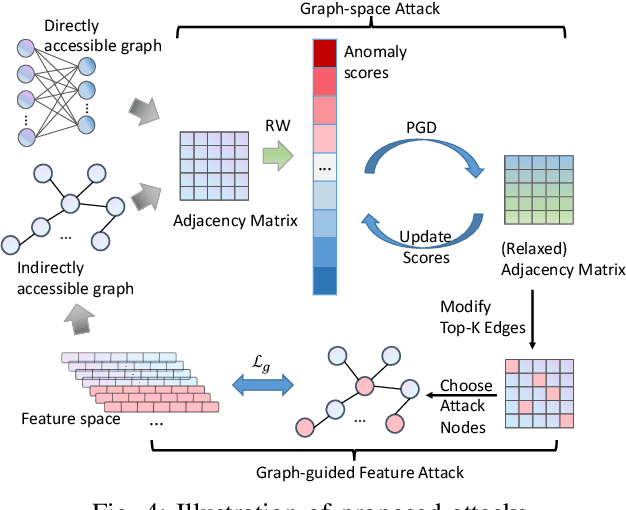
Random Walks-based Anomaly Detection (RWAD) is commonly used to identify anomalous patterns in various applications. An intriguing characteristic of RWAD is that the input graph can either be pre-existing or constructed from raw features. Consequently, there are two potential attack surfaces against RWAD: graph-space attacks and feature-space attacks. In this paper, we explore this vulnerability by designing practical dual-space attacks, investigating the interplay between graph-space and feature-space attacks. To this end, we conduct a thorough complexity analysis, proving that attacking RWAD is NP-hard. Then, we proceed to formulate the graph-space attack as a bi-level optimization problem and propose two strategies to solve it: alternative iteration (alterI-attack) or utilizing the closed-form solution of the random walk model (cf-attack). Finally, we utilize the results from the graph-space attacks as guidance to design more powerful feature-space attacks (i.e., graph-guided attacks). Comprehensive experiments demonstrate that our proposed attacks are effective in enabling the target nodes from RWAD with a limited attack budget. In addition, we conduct transfer attack experiments in a black-box setting, which show that our feature attack significantly decreases the anomaly scores of target nodes. Our study opens the door to studying the dual-space attack against graph anomaly detection in which the graph space relies on the feature space.
Adversarial Robustness of Similarity-Based Link Prediction
Sep 03, 2019
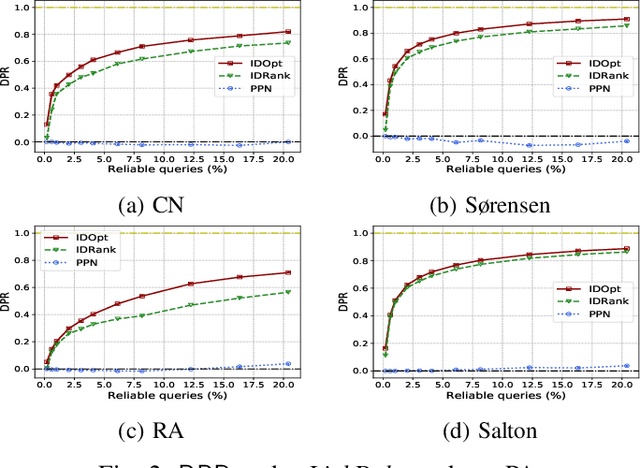
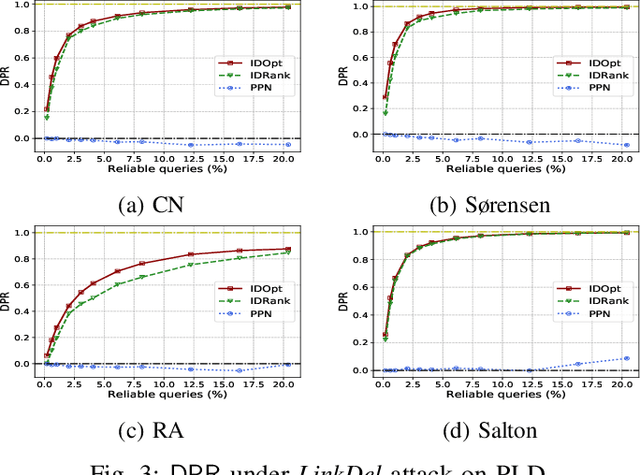
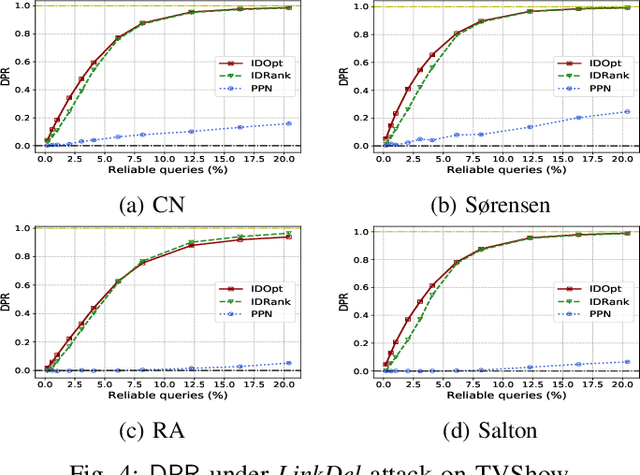
Link prediction is one of the fundamental problems in social network analysis. A common set of techniques for link prediction rely on similarity metrics which use the topology of the observed subnetwork to quantify the likelihood of unobserved links. Recently, similarity metrics for link prediction have been shown to be vulnerable to attacks whereby observations about the network are adversarially modified to hide target links. We propose a novel approach for increasing robustness of similarity-based link prediction by endowing the analyst with a restricted set of reliable queries which accurately measure the existence of queried links. The analyst aims to robustly predict a collection of possible links by optimally allocating the reliable queries. We formalize the analyst problem as a Bayesian Stackelberg game in which they first choose the reliable queries, followed by an adversary who deletes a subset of links among the remaining (unreliable) queries by the analyst. The analyst in our model is uncertain about the particular target link the adversary attempts to hide, whereas the adversary has full information about the analyst and the network. Focusing on similarity metrics using only local information, we show that the problem is NP-Hard for both players, and devise two principled and efficient approaches for solving it approximately. Extensive experiments with real and synthetic networks demonstrate the effectiveness of our approach.
Game-theoretic Network Centrality: A Review
Dec 31, 2017
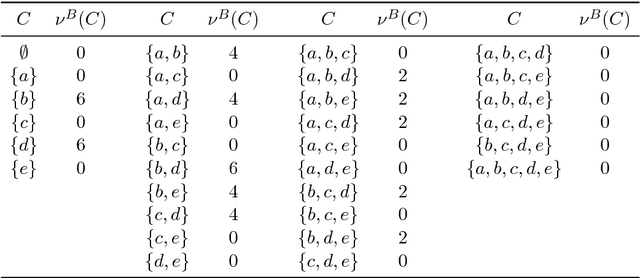

Game-theoretic centrality is a flexible and sophisticated approach to identify the most important nodes in a network. It builds upon the methods from cooperative game theory and network theory. The key idea is to treat nodes as players in a cooperative game, where the value of each coalition is determined by certain graph-theoretic properties. Using solution concepts from cooperative game theory, it is then possible to measure how responsible each node is for the worth of the network. The literature on the topic is already quite large, and is scattered among game-theoretic and computer science venues. We review the main game-theoretic network centrality measures from both bodies of literature and organize them into two categories: those that are more focused on the connectivity of nodes, and those that are more focused on the synergies achieved by nodes in groups. We present and explain each centrality, with a focus on algorithms and complexity.
How good is the Shapley value-based approach to the influence maximization problem?
Sep 27, 2014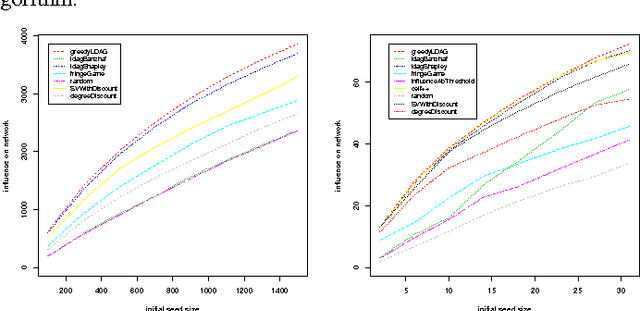
The Shapley value has been recently advocated as a method to choose the seed nodes for the process of information diffusion. Intuitively, since the Shapley value evaluates the average marginal contribution of a player to the coalitional game, it can be used in the network context to evaluate the marginal contribution of a node in the process of information diffusion given various groups of already 'infected' nodes. Although the above direction of research seems promising, the current liter- ature is missing a throughout assessment of its performance. The aim of this work is to provide such an assessment of the existing Shapley value-based approaches to information diffusion.