 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Evaluation of Cultural-scale Claims in Light of Topic Model Sampling Effects
Feb 13, 2017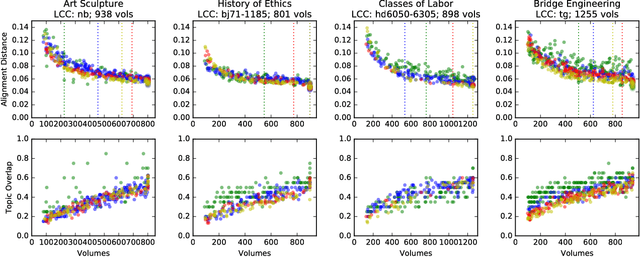
Cultural-scale models of full text documents are prone to over-interpretation by researchers making unintentionally strong socio-linguistic claims (Pechenick et al., 2015) without recognizing that even large digital libraries are merely samples of all the books ever produced. In this study, we test the sensitivity of the topic models to the sampling process by taking random samples of books in the Hathi Trust Digital Library from different areas of the Library of Congress Classification Outline. For each classification area, we train several topic models over the entire class with different random seeds, generating a set of spanning models. Then, we train topic models on random samples of books from the classification area, generating a set of sample models. Finally, we perform a topic alignment between each pair of models by computing the Jensen-Shannon distance (JSD) between the word probability distributions for each topic. We take two measures on each model alignment: alignment distance and topic overlap. We find that sample models with a large sample size typically have an alignment distance that falls in the range of the alignment distance between spanning models. Unsurprisingly, as sample size increases, alignment distance decreases. We also find that the topic overlap increases as sample size increases. However, the decomposition of these measures by sample size differs by number of topics and by classification area. We speculate that these measures could be used to find classes which have a common "canon" discussed among all books in the area, as shown by high topic overlap and low alignment distance even in small sample sizes.
Resource Sharing for Multi-Tenant NoSQL Data Store in Cloud
Jan 05, 2016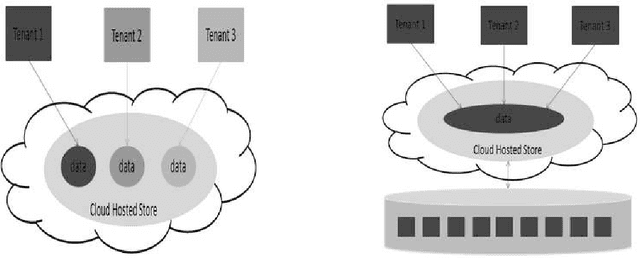
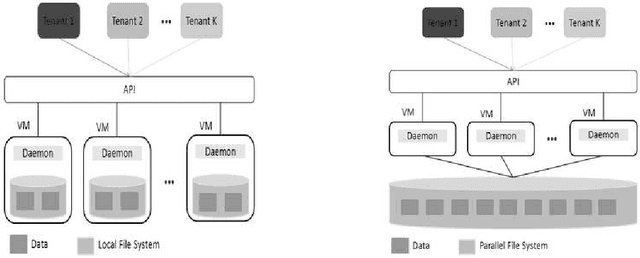
Multi-tenancy hosting of users in cloud NoSQL data stores is favored by cloud providers because it enables resource sharing at low operating cost. Multi-tenancy takes several forms depending on whether the back-end file system is a local file system (LFS) or a parallel file system (PFS), and on whether tenants are independent or share data across tenants. In this thesis I focus on and propose solutions to two cases: independent data-local file system, and shared data-parallel file system. In the independent data-local file system case, resource contention occurs under certain conditions in Cassandra and HBase, two state-of-the-art NoSQL stores, causing performance degradation for one tenant by another. We investigate the interference and propose two approaches. The first provides a scheduling scheme that can approximate resource consumption, adapt to workload dynamics and work in a distributed fashion. The second introduces a workload-aware resource reservation approach to prevent interference. The approach relies on a performance model obtained offline and plans the reservation according to different workload resource demands. Results show the approaches together can prevent interference and adapt to dynamic workloads under multi-tenancy. In the shared data-parallel file system case, it has been shown that running a distributed NoSQL store over PFS for shared data across tenants is not cost effective. Overheads are introduced due to the unawareness of the NoSQL store of PFS. This dissertation targets the key-value store (KVS), a specific form of NoSQL stores, and proposes a lightweight KVS over a parallel file system to improve efficiency. The solution is built on an embedded KVS for high performance but uses novel data structures to support concurrent writes. Results show the proposed system outperforms Cassandra and Voldemort in several different workloads.