 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiamond Maps: Efficient Reward Alignment via Stochastic Flow Maps
Feb 05, 2026Flow and diffusion models produce high-quality samples, but adapting them to user preferences or constraints post-training remains costly and brittle, a challenge commonly called reward alignment. We argue that efficient reward alignment should be a property of the generative model itself, not an afterthought, and redesign the model for adaptability. We propose "Diamond Maps", stochastic flow map models that enable efficient and accurate alignment to arbitrary rewards at inference time. Diamond Maps amortize many simulation steps into a single-step sampler, like flow maps, while preserving the stochasticity required for optimal reward alignment. This design makes search, sequential Monte Carlo, and guidance scalable by enabling efficient and consistent estimation of the value function. Our experiments show that Diamond Maps can be learned efficiently via distillation from GLASS Flows, achieve stronger reward alignment performance, and scale better than existing methods. Our results point toward a practical route to generative models that can be rapidly adapted to arbitrary preferences and constraints at inference time.
Beyond the final layer: Attentive multilayer fusion for vision transformers
Jan 14, 2026With the rise of large-scale foundation models, efficiently adapting them to downstream tasks remains a central challenge. Linear probing, which freezes the backbone and trains a lightweight head, is computationally efficient but often restricted to last-layer representations. We show that task-relevant information is distributed across the network hierarchy rather than solely encoded in any of the last layers. To leverage this distribution of information, we apply an attentive probing mechanism that dynamically fuses representations from all layers of a Vision Transformer. This mechanism learns to identify the most relevant layers for a target task and combines low-level structural cues with high-level semantic abstractions. Across 20 diverse datasets and multiple pretrained foundation models, our method achieves consistent, substantial gains over standard linear probes. Attention heatmaps further reveal that tasks different from the pre-training domain benefit most from intermediate representations. Overall, our findings underscore the value of intermediate layer information and demonstrate a principled, task aware approach for unlocking their potential in probing-based adaptation.
Noise Hypernetworks: Amortizing Test-Time Compute in Diffusion Models
Aug 13, 2025The new paradigm of test-time scaling has yielded remarkable breakthroughs in Large Language Models (LLMs) (e.g. reasoning models) and in generative vision models, allowing models to allocate additional computation during inference to effectively tackle increasingly complex problems. Despite the improvements of this approach, an important limitation emerges: the substantial increase in computation time makes the process slow and impractical for many applications. Given the success of this paradigm and its growing usage, we seek to preserve its benefits while eschewing the inference overhead. In this work we propose one solution to the critical problem of integrating test-time scaling knowledge into a model during post-training. Specifically, we replace reward guided test-time noise optimization in diffusion models with a Noise Hypernetwork that modulates initial input noise. We propose a theoretically grounded framework for learning this reward-tilted distribution for distilled generators, through a tractable noise-space objective that maintains fidelity to the base model while optimizing for desired characteristics. We show that our approach recovers a substantial portion of the quality gains from explicit test-time optimization at a fraction of the computational cost. Code is available at https://github.com/ExplainableML/HyperNoise
Disentangled Representation Learning through Geometry Preservation with the Gromov-Monge Gap
Jul 10, 2024



Learning disentangled representations in an unsupervised manner is a fundamental challenge in machine learning. Solving it may unlock other problems, such as generalization, interpretability, or fairness. While remarkably difficult to solve in general, recent works have shown that disentanglement is provably achievable under additional assumptions that can leverage geometrical constraints, such as local isometry. To use these insights, we propose a novel perspective on disentangled representation learning built on quadratic optimal transport. Specifically, we formulate the problem in the Gromov-Monge setting, which seeks isometric mappings between distributions supported on different spaces. We propose the Gromov-Monge-Gap (GMG), a regularizer that quantifies the geometry-preservation of an arbitrary push-forward map between two distributions supported on different spaces. We demonstrate the effectiveness of GMG regularization for disentanglement on four standard benchmarks. Moreover, we show that geometry preservation can even encourage unsupervised disentanglement without the standard reconstruction objective - making the underlying model decoder-free, and promising a more practically viable and scalable perspective on unsupervised disentanglement.
ReNO: Enhancing One-step Text-to-Image Models through Reward-based Noise Optimization
Jun 06, 2024
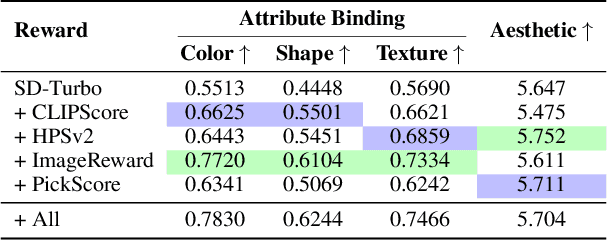

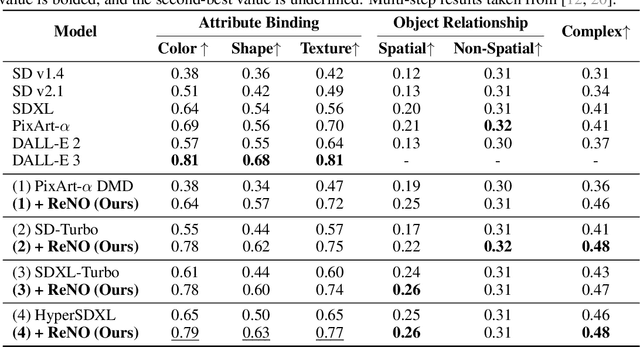
Text-to-Image (T2I) models have made significant advancements in recent years, but they still struggle to accurately capture intricate details specified in complex compositional prompts. While fine-tuning T2I models with reward objectives has shown promise, it suffers from "reward hacking" and may not generalize well to unseen prompt distributions. In this work, we propose Reward-based Noise Optimization (ReNO), a novel approach that enhances T2I models at inference by optimizing the initial noise based on the signal from one or multiple human preference reward models. Remarkably, solving this optimization problem with gradient ascent for 50 iterations yields impressive results on four different one-step models across two competitive benchmarks, T2I-CompBench and GenEval. Within a computational budget of 20-50 seconds, ReNO-enhanced one-step models consistently surpass the performance of all current open-source Text-to-Image models. Extensive user studies demonstrate that our model is preferred nearly twice as often compared to the popular SDXL model and is on par with the proprietary Stable Diffusion 3 with 8B parameters. Moreover, given the same computational resources, a ReNO-optimized one-step model outperforms widely-used open-source models such as SDXL and PixArt-$\alpha$, highlighting the efficiency and effectiveness of ReNO in enhancing T2I model performance at inference time. Code is available at https://github.com/ExplainableML/ReNO.
Unbalancedness in Neural Monge Maps Improves Unpaired Domain Translation
Nov 25, 2023In optimal transport (OT), a Monge map is known as a mapping that transports a source distribution to a target distribution in the most cost-efficient way. Recently, multiple neural estimators for Monge maps have been developed and applied in diverse unpaired domain translation tasks, e.g. in single-cell biology and computer vision. However, the classic OT framework enforces mass conservation, which makes it prone to outliers and limits its applicability in real-world scenarios. The latter can be particularly harmful in OT domain translation tasks, where the relative position of a sample within a distribution is explicitly taken into account. While unbalanced OT tackles this challenge in the discrete setting, its integration into neural Monge map estimators has received limited attention. We propose a theoretically grounded method to incorporate unbalancedness into any Monge map estimator. We improve existing estimators to model cell trajectories over time and to predict cellular responses to perturbations. Moreover, our approach seamlessly integrates with the OT flow matching (OT-FM) framework. While we show that OT-FM performs competitively in image translation, we further improve performance by incorporating unbalancedness (UOT-FM), which better preserves relevant features. We hence establish UOT-FM as a principled method for unpaired image translation.