 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptation for Memory-Efficient Dense Retrieval
Paper and Code

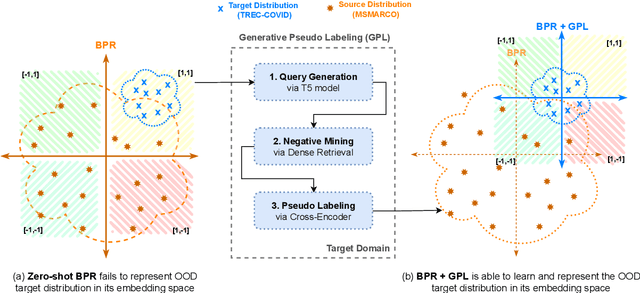


Dense retrievers encode documents into fixed dimensional embeddings. However, storing all the document embeddings within an index produces bulky indexes which are expensive to serve. Recently, BPR (Yamada et al., 2021) and JPQ (Zhan et al., 2021a) have been proposed which train the model to produce binary document vectors, which reduce the index 32x and more. The authors showed these binary embedding models significantly outperform more traditional index compression techniques like Product Quantization (PQ). Previous work evaluated these approaches just in-domain, i.e. the methods were evaluated on tasks for which training data is available. In practice, retrieval models are often used in an out-of-domain setting, where they have been trained on a publicly available dataset, like MS MARCO, but are then used for some custom dataset for which no training data is available. In this work, we show that binary embedding models like BPR and JPQ can perform significantly worse than baselines once there is a domain-shift involved. We propose a modification to the training procedure of BPR and JPQ and combine it with a corpus specific generative procedure which allow the adaptation of BPR and JPQ to any corpus without requiring labeled training data. Our domain-adapted strategy known as GPL is model agnostic, achieves an improvement by up-to 19.3 and 11.6 points in nDCG@10 across the BEIR benchmark in comparison to BPR and JPQ while maintaining its 32x memory efficiency. JPQ+GPL even outperforms our upper baseline: uncompressed TAS-B model on average by 2.0 points.