 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmented SBERT: Data Augmentation Method for Improving Bi-Encoders for Pairwise Sentence Scoring Tasks
Paper and Code
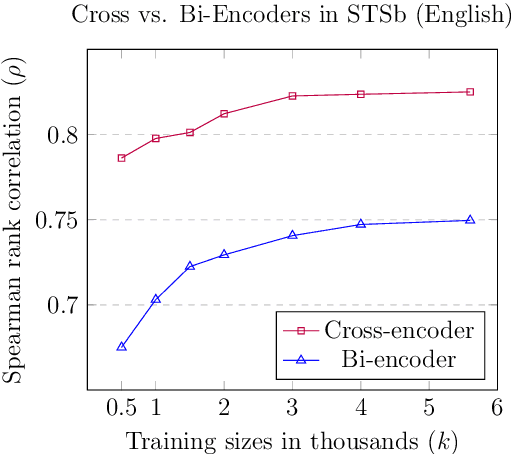

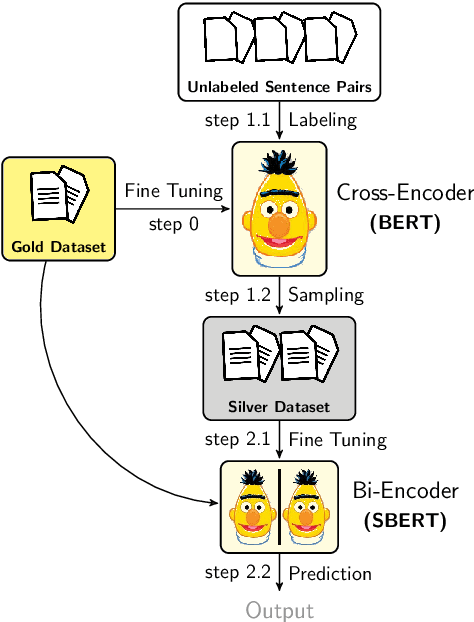

There are two approaches for pairwise sentence scoring: Cross-encoders, which perform full-attention over the input pair, and Bi-encoders, which map each input independently to a dense vector space. While cross-encoders often achieve higher performance, they are too slow for many practical use cases. Bi-encoders, on the other hand, require substantial training data and fine-tuning over the target task to achieve competitive performance. We present a simple yet efficient data augmentation strategy called Augmented SBERT, where we use the cross-encoder to label a larger set of input pairs to augment the training data for the bi-encoder. We show that, in this process, selecting the sentence pairs is non-trivial and crucial for the success of the method. We evaluate our approach on multiple tasks (in-domain) as well as on a domain adaptation task. Augmented SBERT achieves an improvement of up to 6 points for in-domain and of up to 37 points for domain adaptation tasks compared to the original bi-encoder performance.