 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Learning for Argumentation Mining
Apr 23, 2019Multi-task learning has recently become a very active field in deep learning research. In contrast to learning a single task in isolation, multiple tasks are learned at the same time, thereby utilizing the training signal of related tasks to improve the performance on the respective machine learning tasks. Related work shows various successes in different domains when applying this paradigm and this thesis extends the existing empirical results by evaluating multi-task learning in four different scenarios: argumentation mining, epistemic segmentation, argumentation component segmentation, and grapheme-to-phoneme conversion. We show that multi-task learning can, indeed, improve the performance compared to single-task learning in all these scenarios, but may also hurt the performance. Therefore, we investigate the reasons for successful and less successful applications of this paradigm and find that dataset properties such as entropy or the size of the label inventory are good indicators for a potential multi-task learning success and that multi-task learning is particularly useful if the task at hand suffers from data sparsity, i.e. a lack of training data. Moreover, multi-task learning is particularly effective for long input sequences in our experiments. We have observed this trend in all evaluated scenarios. Finally, we develop a highly configurable and extensible sequence tagging framework which supports multi-task learning to conduct our empirical experiments and to aid future research regarding the multi-task learning paradigm and natural language processing.
Multi-Task Learning for Argumentation Mining in Low-Resource Settings
May 04, 2018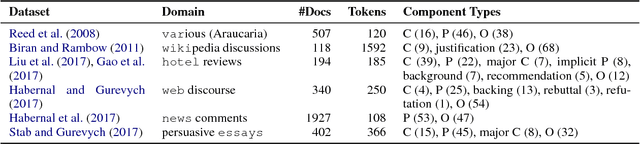
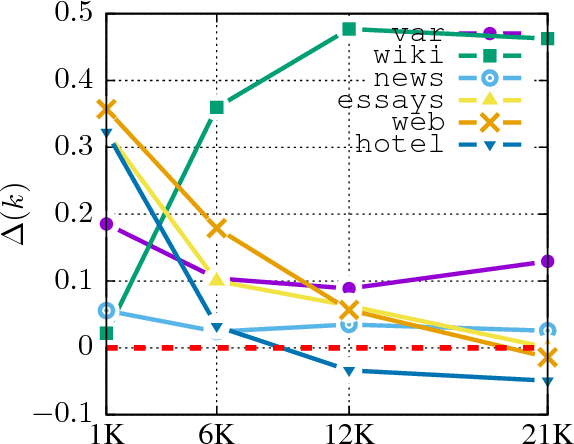
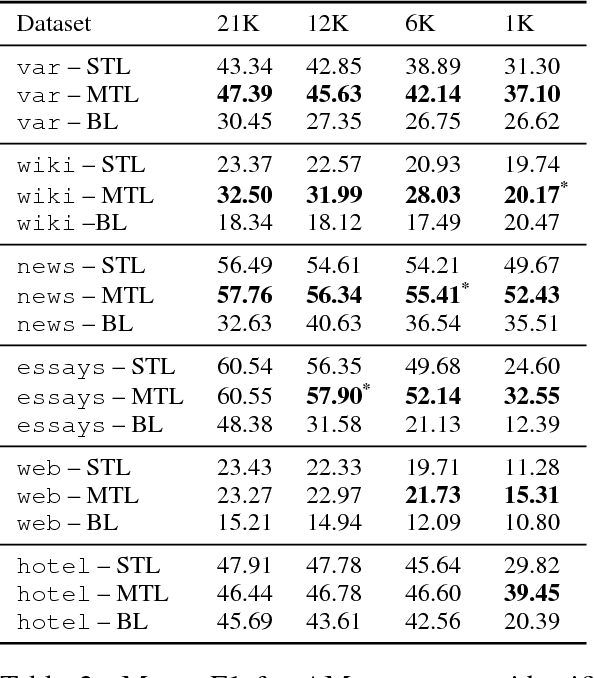
We investigate whether and where multi-task learning (MTL) can improve performance on NLP problems related to argumentation mining (AM), in particular argument component identification. Our results show that MTL performs particularly well (and better than single-task learning) when little training data is available for the main task, a common scenario in AM. Our findings challenge previous assumptions that conceptualizations across AM datasets are divergent and that MTL is difficult for semantic or higher-level tasks.