 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAMULUS: Interactive Annotation and Feedback Generation for Teaching Diagnostic Reasoning
Aug 29, 2019
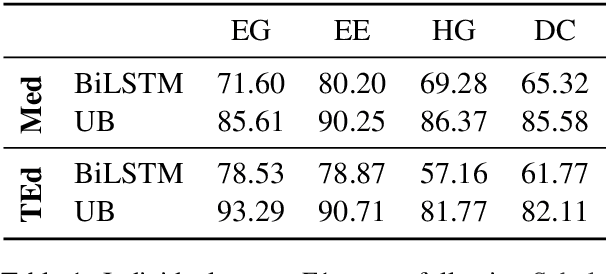

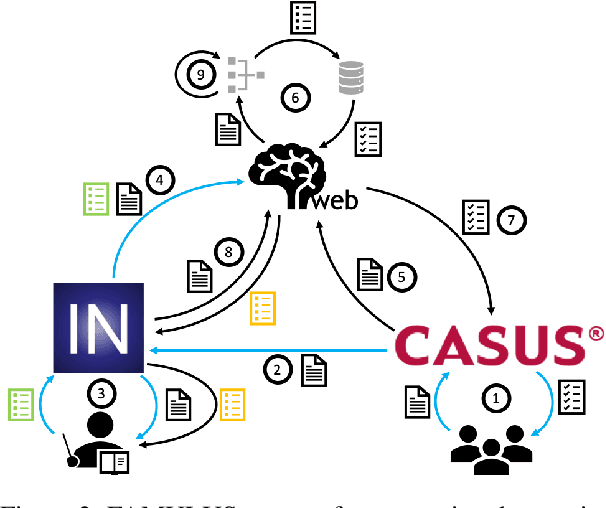
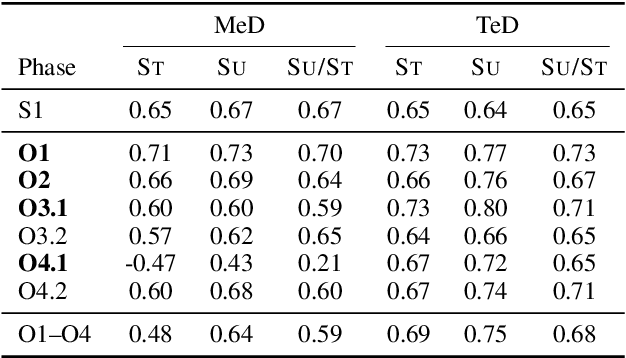
Our proposed system FAMULUS helps students learn to diagnose based on automatic feedback in virtual patient simulations, and it supports instructors in labeling training data. Diagnosing is an exceptionally difficult skill to obtain but vital for many different professions (e.g., medical doctors, teachers). Previous case simulation systems are limited to multiple-choice questions and thus cannot give constructive individualized feedback on a student's diagnostic reasoning process. Given initially only limited data, we leverage a (replaceable) NLP model to both support experts in their further data annotation with automatic suggestions, and we provide automatic feedback for students. We argue that because the central model consistently improves, our interactive approach encourages both students and instructors to recurrently use the tool, and thus accelerate the speed of data creation and annotation. We show results from two user studies on diagnostic reasoning in medicine and teacher education and outline how our system can be extended to further use cases.
Analysis of Automatic Annotation Suggestions for Hard Discourse-Level Tasks in Expert Domains
Jun 06, 2019
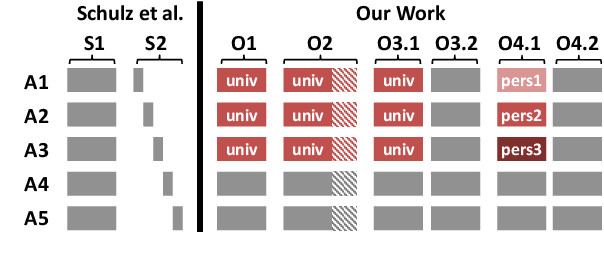
Many complex discourse-level tasks can aid domain experts in their work but require costly expert annotations for data creation. To speed up and ease annotations, we investigate the viability of automatically generated annotation suggestions for such tasks. As an example, we choose a task that is particularly hard for both humans and machines: the segmentation and classification of epistemic activities in diagnostic reasoning texts. We create and publish a new dataset covering two domains and carefully analyse the suggested annotations. We find that suggestions have positive effects on annotation speed and performance, while not introducing noteworthy biases. Envisioning suggestion models that improve with newly annotated texts, we contrast methods for continuous model adjustment and suggest the most effective setup for suggestions in future expert tasks.
"The Michael Jordan of Greatness": Extracting Vossian Antonomasia from Two Decades of the New York Times, 1987-2007
Feb 18, 2019
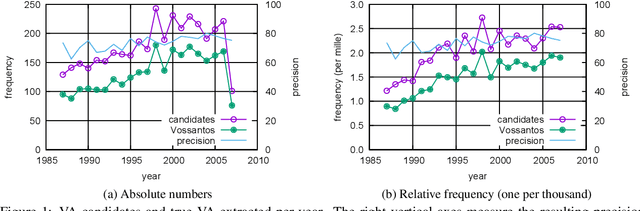


Vossian Antonomasia is a prolific stylistic device, in use since antiquity. It can compress the introduction or description of a person or another named entity into a terse, poignant formulation and can best be explained by an example: When Norwegian world champion Magnus Carlsen is described as "the Mozart of chess", it is Vossian Antonomasia we are dealing with. The pattern is simple: A source (Mozart) is used to describe a target (Magnus Carlsen), the transfer of meaning is reached via a modifier ("of chess"). This phenomenon has been discussed before (as 'metaphorical antonomasia' or, with special focus on the source object, as 'paragons'), but no corpus-based approach has been undertaken as yet to explore its breadth and variety. We are looking into a full-text newspaper corpus (The New York Times, 1987-2007) and describe a new method for the automatic extraction of Vossian Antonomasia based on Wikidata entities. Our analysis offers new insights into the occurrence of popular paragons and their distribution.
Challenges in the Automatic Analysis of Students' Diagnostic Reasoning
Nov 26, 2018


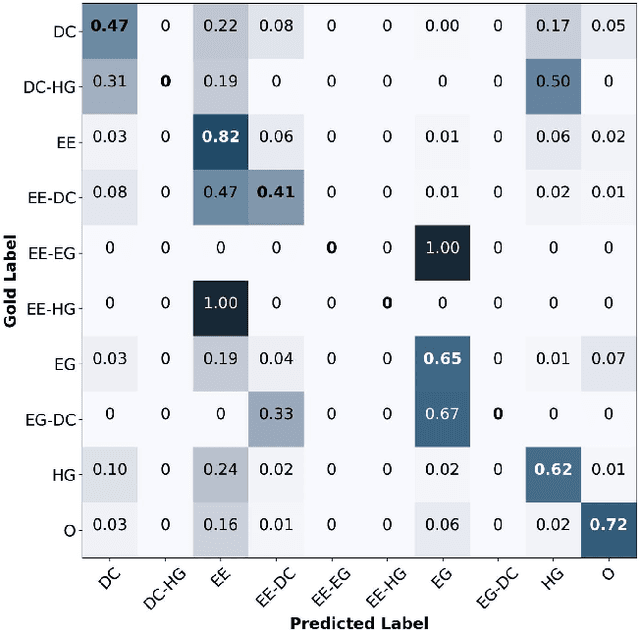
Diagnostic reasoning is a key component of many professions. To improve students' diagnostic reasoning skills, educational psychologists analyse and give feedback on epistemic activities used by these students while diagnosing, in particular, hypothesis generation, evidence generation, evidence evaluation, and drawing conclusions. However, this manual analysis is highly time-consuming. We aim to enable the large-scale adoption of diagnostic reasoning analysis and feedback by automating the epistemic activity identification. We create the first corpus for this task, comprising diagnostic reasoning self-explanations of students from two domains annotated with epistemic activities. Based on insights from the corpus creation and the task's characteristics, we discuss three challenges for the automatic identification of epistemic activities using AI methods: the correct identification of epistemic activity spans, the reliable distinction of similar epistemic activities, and the detection of overlapping epistemic activities. We propose a separate performance metric for each challenge and thus provide an evaluation framework for future research. Indeed, our evaluation of various state-of-the-art recurrent neural network architectures reveals that current techniques fail to address some of these challenges.
World Literature According to Wikipedia: Introduction to a DBpedia-Based Framework
Jan 04, 2017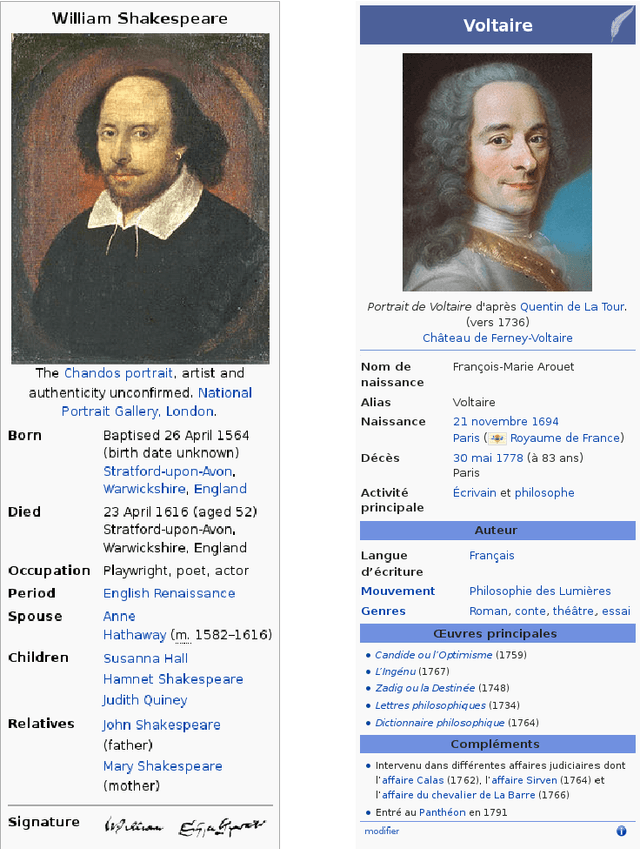
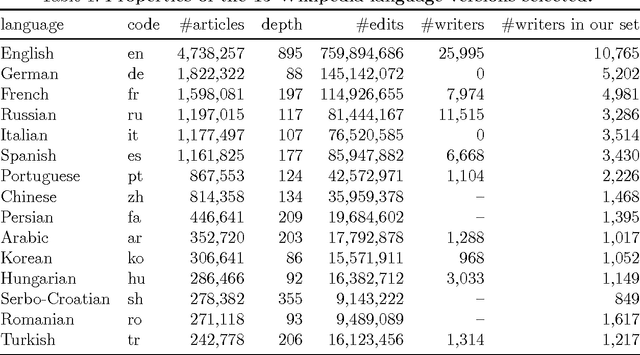
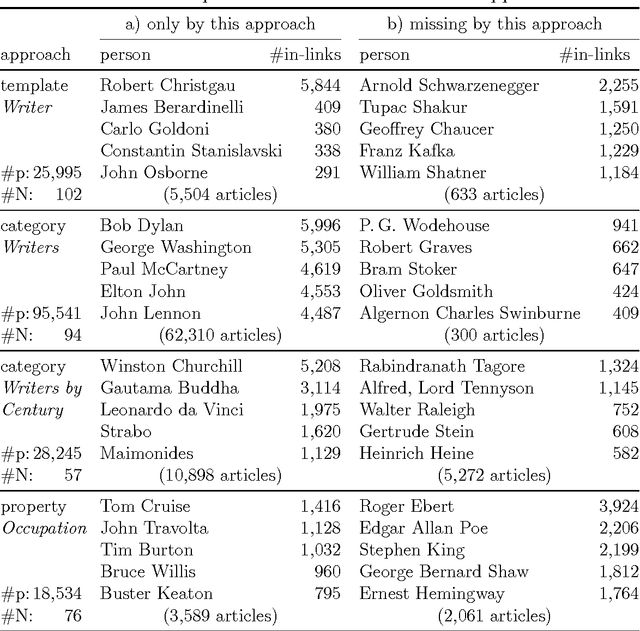
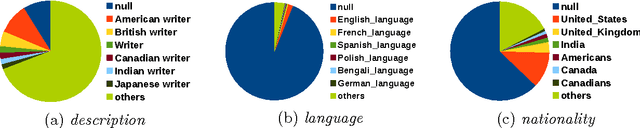
Among the manifold takes on world literature, it is our goal to contribute to the discussion from a digital point of view by analyzing the representation of world literature in Wikipedia with its millions of articles in hundreds of languages. As a preliminary, we introduce and compare three different approaches to identify writers on Wikipedia using data from DBpedia, a community project with the goal of extracting and providing structured information from Wikipedia. Equipped with our basic set of writers, we analyze how they are represented throughout the 15 biggest Wikipedia language versions. We combine intrinsic measures (mostly examining the connectedness of articles) with extrinsic ones (analyzing how often articles are frequented by readers) and develop methods to evaluate our results. The better part of our findings seems to convey a rather conservative, old-fashioned version of world literature, but a version derived from reproducible facts revealing an implicit literary canon based on the editing and reading behavior of millions of people. While still having to solve some known issues, the introduced methods will help us build an observatory of world literature to further investigate its representativeness and biases.