 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Robustness of Cover Version Identification Models: A Study Using Cover Versions from YouTube
Jan 02, 2025Recent advances in cover song identification have shown great success. However, models are usually tested on a fixed set of datasets which are relying on the online cover song database SecondHandSongs. It is unclear how well models perform on cover songs on online video platforms, which might exhibit alterations that are not expected. In this paper, we annotate a subset of songs from YouTube sampled by a multi-modal uncertainty sampling approach and evaluate state-of-the-art models. We find that existing models achieve significantly lower ranking performance on our dataset compared to a community dataset. We additionally measure the performance of different types of versions (e.g., instrumental versions) and find several types that are particularly hard to rank. Lastly, we provide a taxonomy of alterations in cover versions on the web.
Leveraging User-Generated Metadata of Online Videos for Cover Song Identification
Dec 16, 2024YouTube is a rich source of cover songs. Since the platform itself is organized in terms of videos rather than songs, the retrieval of covers is not trivial. The field of cover song identification addresses this problem and provides approaches that usually rely on audio content. However, including the user-generated video metadata available on YouTube promises improved identification results. In this paper, we propose a multi-modal approach for cover song identification on online video platforms. We combine the entity resolution models with audio-based approaches using a ranking model. Our findings implicate that leveraging user-generated metadata can stabilize cover song identification performance on YouTube.
A Benchmark and Robustness Study of In-Context-Learning with Large Language Models in Music Entity Detection
Dec 16, 2024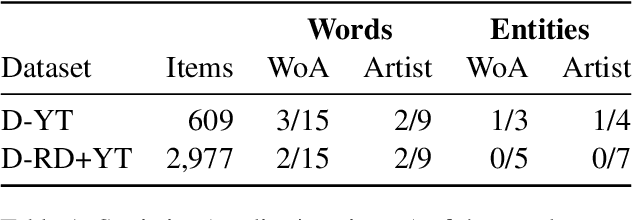
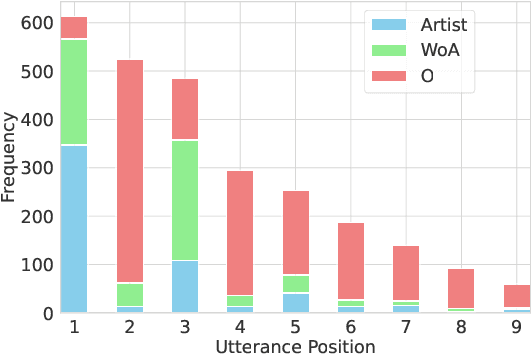


Detecting music entities such as song titles or artist names is a useful application to help use cases like processing music search queries or analyzing music consumption on the web. Recent approaches incorporate smaller language models (SLMs) like BERT and achieve high results. However, further research indicates a high influence of entity exposure during pre-training on the performance of the models. With the advent of large language models (LLMs), these outperform SLMs in a variety of downstream tasks. However, researchers are still divided if this is applicable to tasks like entity detection in texts due to issues like hallucination. In this paper, we provide a novel dataset of user-generated metadata and conduct a benchmark and a robustness study using recent LLMs with in-context-learning (ICL). Our results indicate that LLMs in the ICL setting yield higher performance than SLMs. We further uncover the large impact of entity exposure on the best performing LLM in our study.
A Repository for Formal Contexts
Apr 05, 2024Data is always at the center of the theoretical development and investigation of the applicability of formal concept analysis. It is therefore not surprising that a large number of data sets are repeatedly used in scholarly articles and software tools, acting as de facto standard data sets. However, the distribution of the data sets poses a problem for the sustainable development of the research field. There is a lack of a central location that provides and describes FCA data sets and links them to already known analysis results. This article analyses the current state of the dissemination of FCA data sets, presents the requirements for a central FCA repository, and highlights the challenges for this.
"The Michael Jordan of Greatness": Extracting Vossian Antonomasia from Two Decades of the New York Times, 1987-2007
Feb 18, 2019
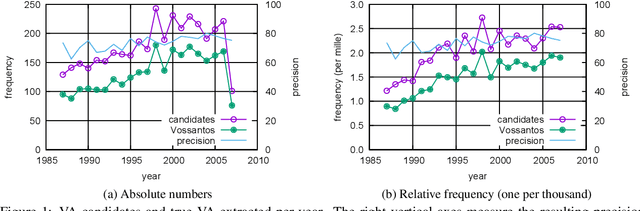


Vossian Antonomasia is a prolific stylistic device, in use since antiquity. It can compress the introduction or description of a person or another named entity into a terse, poignant formulation and can best be explained by an example: When Norwegian world champion Magnus Carlsen is described as "the Mozart of chess", it is Vossian Antonomasia we are dealing with. The pattern is simple: A source (Mozart) is used to describe a target (Magnus Carlsen), the transfer of meaning is reached via a modifier ("of chess"). This phenomenon has been discussed before (as 'metaphorical antonomasia' or, with special focus on the source object, as 'paragons'), but no corpus-based approach has been undertaken as yet to explore its breadth and variety. We are looking into a full-text newspaper corpus (The New York Times, 1987-2007) and describe a new method for the automatic extraction of Vossian Antonomasia based on Wikidata entities. Our analysis offers new insights into the occurrence of popular paragons and their distribution.
World Literature According to Wikipedia: Introduction to a DBpedia-Based Framework
Jan 04, 2017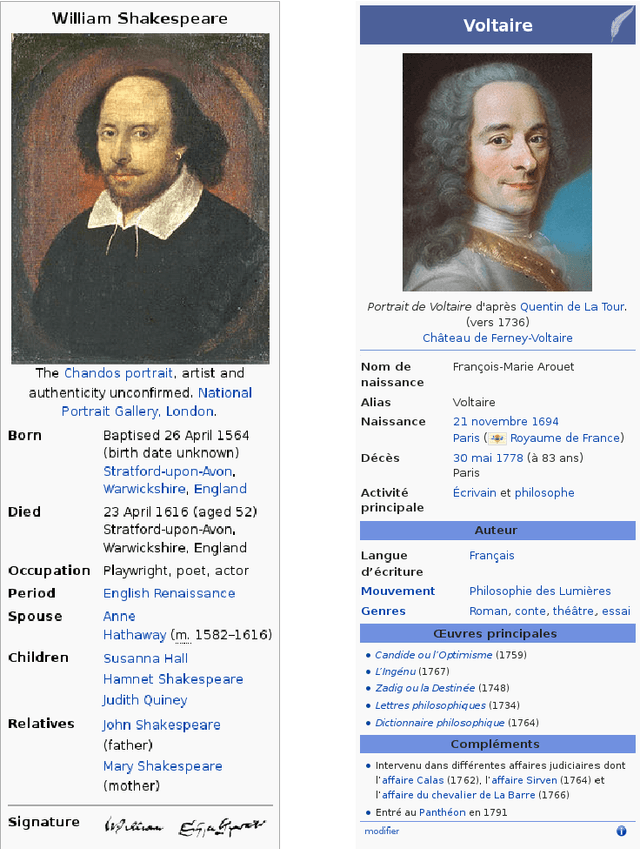
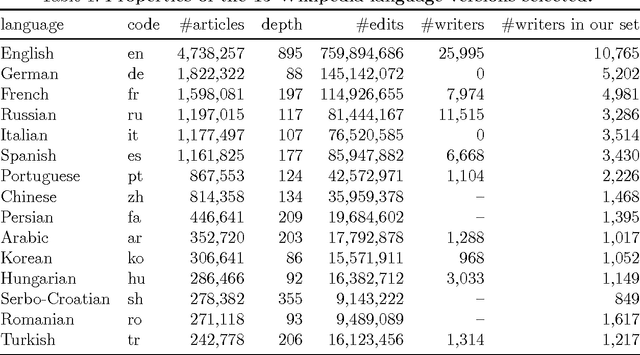
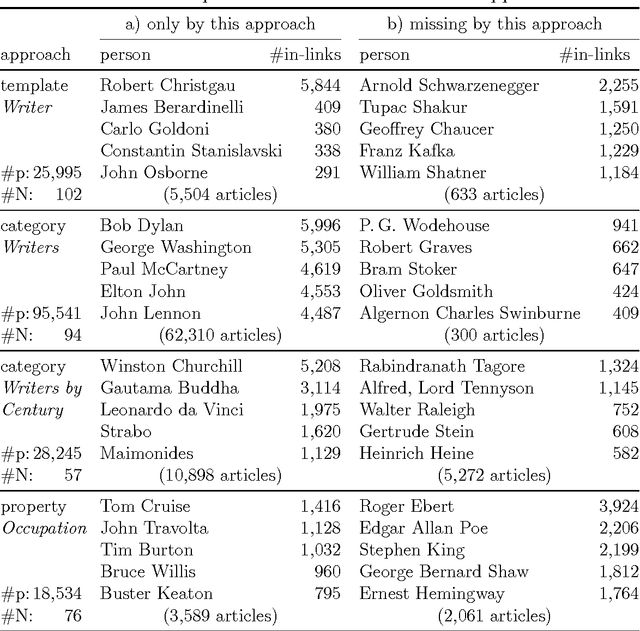
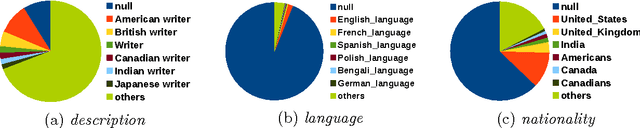
Among the manifold takes on world literature, it is our goal to contribute to the discussion from a digital point of view by analyzing the representation of world literature in Wikipedia with its millions of articles in hundreds of languages. As a preliminary, we introduce and compare three different approaches to identify writers on Wikipedia using data from DBpedia, a community project with the goal of extracting and providing structured information from Wikipedia. Equipped with our basic set of writers, we analyze how they are represented throughout the 15 biggest Wikipedia language versions. We combine intrinsic measures (mostly examining the connectedness of articles) with extrinsic ones (analyzing how often articles are frequented by readers) and develop methods to evaluate our results. The better part of our findings seems to convey a rather conservative, old-fashioned version of world literature, but a version derived from reproducible facts revealing an implicit literary canon based on the editing and reading behavior of millions of people. While still having to solve some known issues, the introduced methods will help us build an observatory of world literature to further investigate its representativeness and biases.