 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Based Statement Classification for Biased Language
Nov 14, 2018
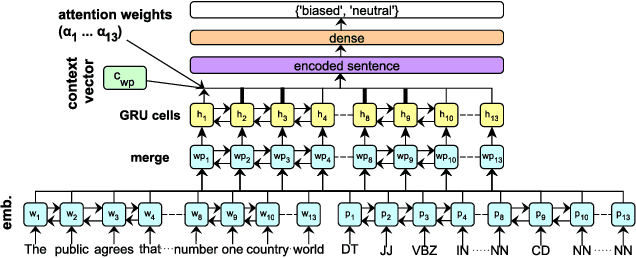


Biased language commonly occurs around topics which are of controversial nature, thus, stirring disagreement between the different involved parties of a discussion. This is due to the fact that for language and its use, specifically, the understanding and use of phrases, the stances are cohesive within the particular groups. However, such cohesiveness does not hold across groups. In collaborative environments or environments where impartial language is desired (e.g. Wikipedia, news media), statements and the language therein should represent equally the involved parties and be neutrally phrased. Biased language is introduced through the presence of inflammatory words or phrases, or statements that may be incorrect or one-sided, thus violating such consensus. In this work, we focus on the specific case of phrasing bias, which may be introduced through specific inflammatory words or phrases in a statement. For this purpose, we propose an approach that relies on a recurrent neural networks in order to capture the inter-dependencies between words in a phrase that introduced bias. We perform a thorough experimental evaluation, where we show the advantages of a neural based approach over competitors that rely on word lexicons and other hand-crafted features in detecting biased language. We are able to distinguish biased statements with a precision of P=0.92, thus significantly outperforming baseline models with an improvement of over 30%. Finally, we release the largest corpus of statements annotated for biased language.
World Literature According to Wikipedia: Introduction to a DBpedia-Based Framework
Jan 04, 2017
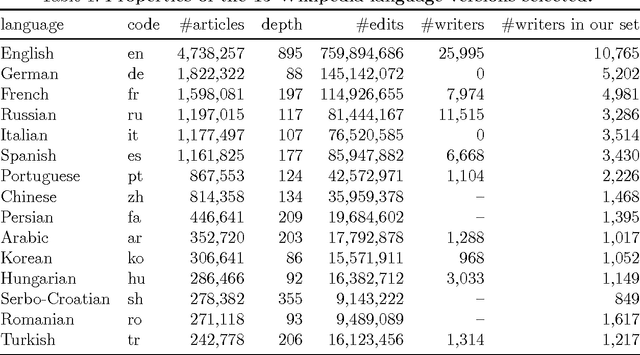
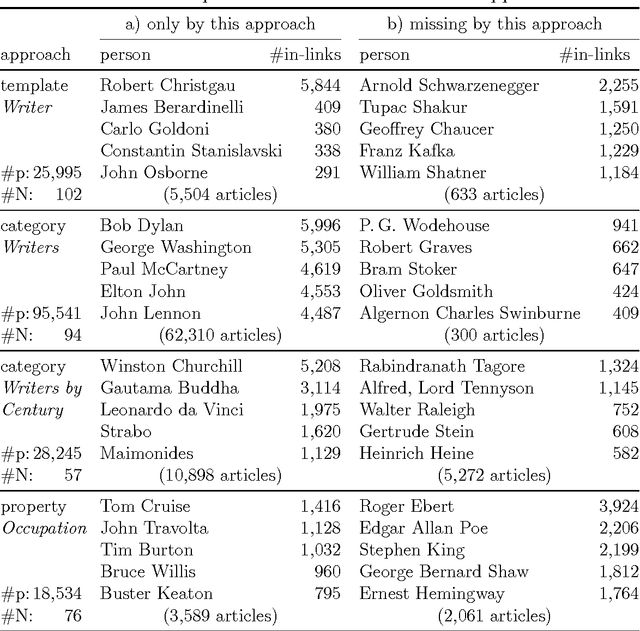
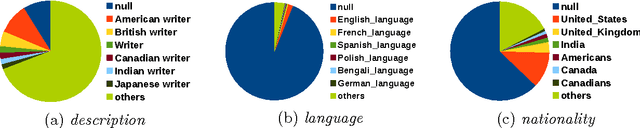
Among the manifold takes on world literature, it is our goal to contribute to the discussion from a digital point of view by analyzing the representation of world literature in Wikipedia with its millions of articles in hundreds of languages. As a preliminary, we introduce and compare three different approaches to identify writers on Wikipedia using data from DBpedia, a community project with the goal of extracting and providing structured information from Wikipedia. Equipped with our basic set of writers, we analyze how they are represented throughout the 15 biggest Wikipedia language versions. We combine intrinsic measures (mostly examining the connectedness of articles) with extrinsic ones (analyzing how often articles are frequented by readers) and develop methods to evaluate our results. The better part of our findings seems to convey a rather conservative, old-fashioned version of world literature, but a version derived from reproducible facts revealing an implicit literary canon based on the editing and reading behavior of millions of people. While still having to solve some known issues, the introduced methods will help us build an observatory of world literature to further investigate its representativeness and biases.