 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Based Statement Classification for Biased Language
Paper and Code
Nov 14, 2018
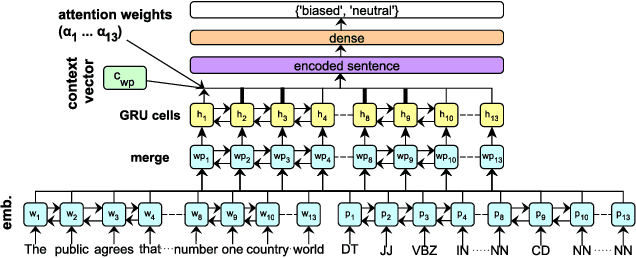


Biased language commonly occurs around topics which are of controversial nature, thus, stirring disagreement between the different involved parties of a discussion. This is due to the fact that for language and its use, specifically, the understanding and use of phrases, the stances are cohesive within the particular groups. However, such cohesiveness does not hold across groups. In collaborative environments or environments where impartial language is desired (e.g. Wikipedia, news media), statements and the language therein should represent equally the involved parties and be neutrally phrased. Biased language is introduced through the presence of inflammatory words or phrases, or statements that may be incorrect or one-sided, thus violating such consensus. In this work, we focus on the specific case of phrasing bias, which may be introduced through specific inflammatory words or phrases in a statement. For this purpose, we propose an approach that relies on a recurrent neural networks in order to capture the inter-dependencies between words in a phrase that introduced bias. We perform a thorough experimental evaluation, where we show the advantages of a neural based approach over competitors that rely on word lexicons and other hand-crafted features in detecting biased language. We are able to distinguish biased statements with a precision of P=0.92, thus significantly outperforming baseline models with an improvement of over 30%. Finally, we release the largest corpus of statements annotated for biased language.