 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGood Books are Complex Matters: Gauging Complexity Profiles Across Diverse Categories of Perceived Literary Quality
Apr 14, 2024In this study, we employ a classification approach to show that different categories of literary "quality" display unique linguistic profiles, leveraging a corpus that encompasses titles from the Norton Anthology, Penguin Classics series, and the Open Syllabus project, contrasted against contemporary bestsellers, Nobel prize winners and recipients of prestigious literary awards. Our analysis reveals that canonical and so called high-brow texts exhibit distinct textual features when compared to other quality categories such as bestsellers and popular titles as well as to control groups, likely responding to distinct (but not mutually exclusive) models of quality. We apply a classic machine learning approach, namely Random Forest, to distinguish quality novels from "control groups", achieving up to 77\% F1 scores in differentiating between the categories. We find that quality category tend to be easier to distinguish from control groups than from other quality categories, suggesting than literary quality features might be distinguishable but shared through quality proxies.
World Literature According to Wikipedia: Introduction to a DBpedia-Based Framework
Jan 04, 2017
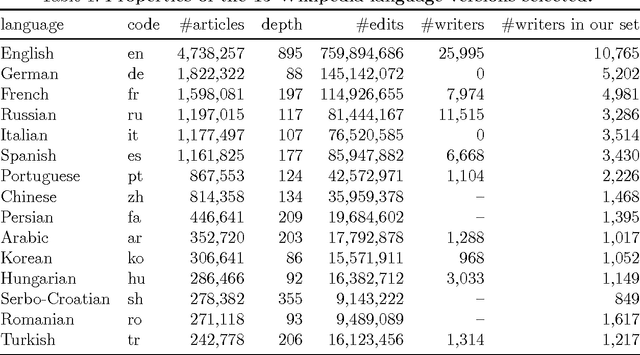
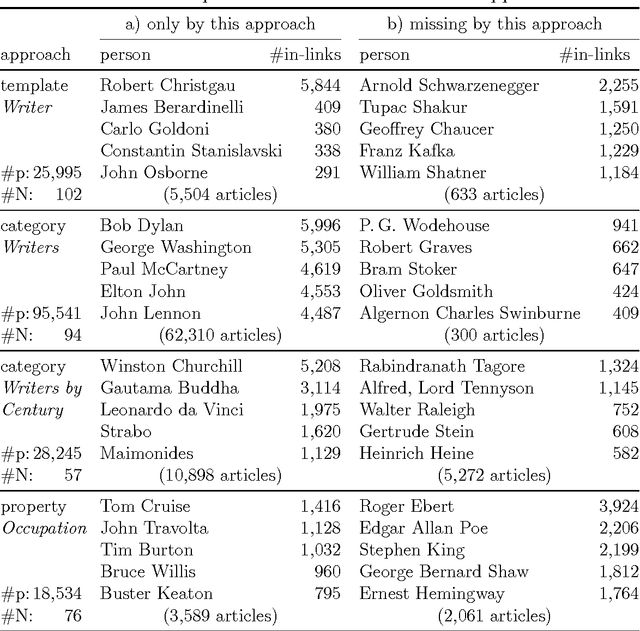
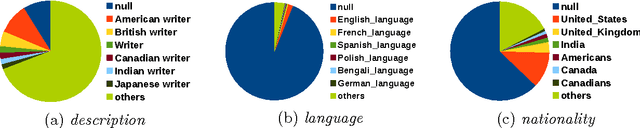
Among the manifold takes on world literature, it is our goal to contribute to the discussion from a digital point of view by analyzing the representation of world literature in Wikipedia with its millions of articles in hundreds of languages. As a preliminary, we introduce and compare three different approaches to identify writers on Wikipedia using data from DBpedia, a community project with the goal of extracting and providing structured information from Wikipedia. Equipped with our basic set of writers, we analyze how they are represented throughout the 15 biggest Wikipedia language versions. We combine intrinsic measures (mostly examining the connectedness of articles) with extrinsic ones (analyzing how often articles are frequented by readers) and develop methods to evaluate our results. The better part of our findings seems to convey a rather conservative, old-fashioned version of world literature, but a version derived from reproducible facts revealing an implicit literary canon based on the editing and reading behavior of millions of people. While still having to solve some known issues, the introduced methods will help us build an observatory of world literature to further investigate its representativeness and biases.