 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark and Robustness Study of In-Context-Learning with Large Language Models in Music Entity Detection
Paper and Code
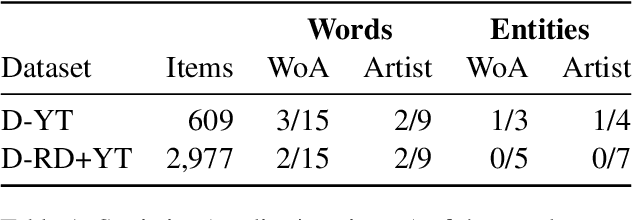
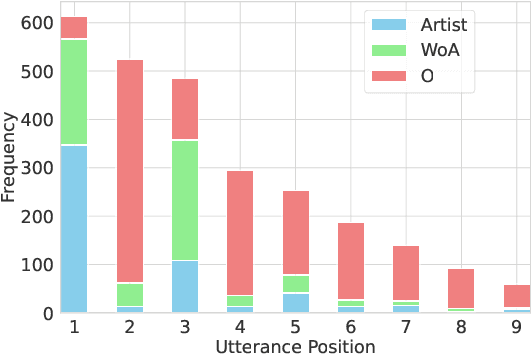


Detecting music entities such as song titles or artist names is a useful application to help use cases like processing music search queries or analyzing music consumption on the web. Recent approaches incorporate smaller language models (SLMs) like BERT and achieve high results. However, further research indicates a high influence of entity exposure during pre-training on the performance of the models. With the advent of large language models (LLMs), these outperform SLMs in a variety of downstream tasks. However, researchers are still divided if this is applicable to tasks like entity detection in texts due to issues like hallucination. In this paper, we provide a novel dataset of user-generated metadata and conduct a benchmark and a robustness study using recent LLMs with in-context-learning (ICL). Our results indicate that LLMs in the ICL setting yield higher performance than SLMs. We further uncover the large impact of entity exposure on the best performing LLM in our study.